Prisma ORM v7.4: Query Caching, Partial Indexes, and Major Performance Improvements

For the newest numbers on where Prisma performance is heading, we've benchmarked Prisma Next, the new TypeScript-first foundation for Prisma ORM: about 87% of the raw pg driver's peak throughput and 52% more requests per second than Prisma 7. See the latest results.
We’re excited to share the release of Prisma ORM v7.4! This release comes with new features like partial indexes, a fix for BigInt precision, and a new query caching layer to address performance issues. Let’s dive in.
Partial indexes preview feature
Partial indexes allow you to create indexes that only include rows matching specific conditions, significantly reducing index size and improving query performance. This has been a community-led contribution to the ORM, and we’re excited to ship it as a preview feature.
Partial indexes are available behind the partialIndexes preview feature for PostgreSQL, SQLite, SQL Server, and CockroachDB, with full migration and introspection support.
generator client {
provider = "prisma-client-js"
previewFeatures = ["partialIndexes"]
}Raw SQL syntax
For maximum flexibility, use the raw() function with database-specific predicates:
model User {
id Int @id
email String
status String
@@unique([email], where: raw("status = 'active'"))
@@index([email], where: raw("deletedAt IS NULL"))
}Type-safe object syntax
For better type safety, use the object literal syntax for simple conditions:
model Post {
id Int @id
title String
published Boolean
@@index([title], where: { published: true })
@@unique([title], where: { published: { not: false } })
}Caching layer added to ORM
One of the main pieces of feedback we’ve received about Prisma 7 is that performance has not met the expectations we initially set. We’ve been exploring several approaches to address these concerns and are happy to share our progress here.
We’ve added a new query caching mechanism so that Prisma Client does not rebuild the SQL statement on every request. Let’s look at the numbers:
| Metric | Without caching (7.3.0) | With caching (7.4.0) |
|---|---|---|
| Per-query compilation cost | 0.1-1ms | 1-10µs |
| Typical cache hit rate | -- | ~100% |
What this represents is that once a query has been built in Prisma Client, we can reuse its base structure and template out the dynamic parts, removing the need to rebuild subsequent queries.
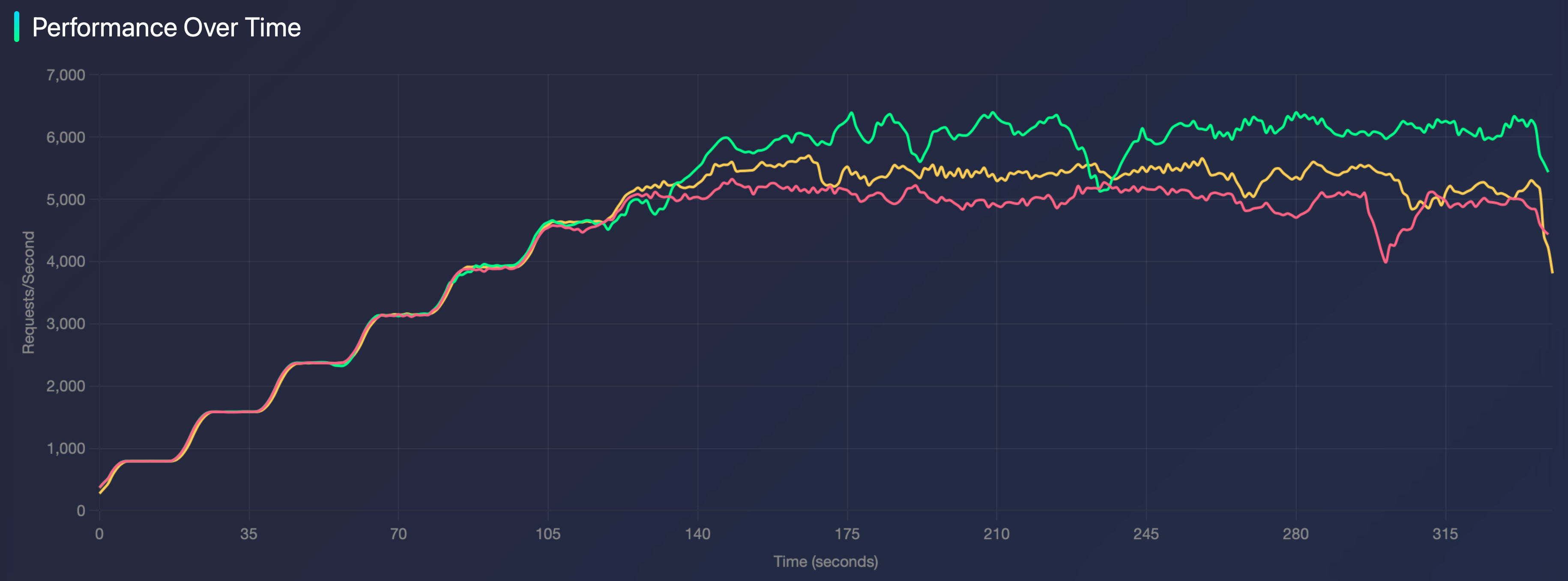
We looked at various benchmarks built by the community, including some created by our friends at Drizzle. We compared Prisma ORM 7.4.0 (green) against Prisma ORM 7.3.0 (red) and Prisma ORM 6 (yellow), and the results were encouraging.
Here, we’re measuring requests per second. At the start, all three versions of Prisma ORM perform about the same. However, at a certain point, v6 and v7.3.0 begin to run into issues. v7.4.0, however, is able to handle more requests than both v6 and v7.3.0.
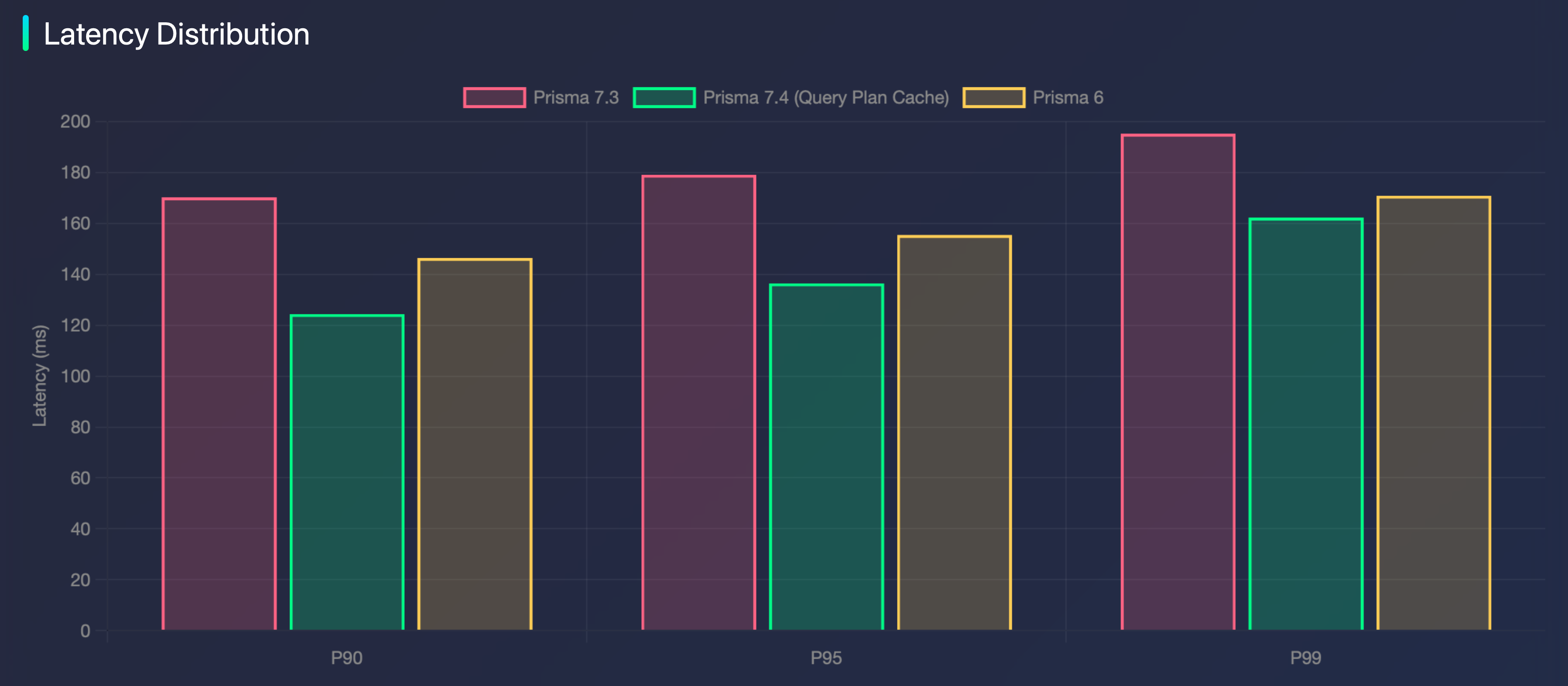
We also measured latency across v6, v7.3.0, and v7.4.0. Here, lower is better, and in every test, v7.4.0 outperforms the others.
Why did the initial release of ORM v7 have performance issue?
This stems from the move away from Rust. We made a lot of noise about our move away from Rust and our goal of simplifying the internal architecture of how Prisma ORM works. However, the trade-off was that all queries are now built in the main JavaScript event loop, whereas in v6, they were run in Rust.
When a query was performed in v6, the main JS thread would dispatch a call to the Rust engine. When the data was ready, it would be sent back over. The main JS thread, however, was not blocked because it wasn’t performing the actual query work.

This did mean that if you had a large query with a lot of data, it would take some time to serialize the data back to the JS thread. This is the core problem we set out to solve.
With v7 moving to a WASM module approach, serialization became faster, but more work moved onto the main thread. Now, every time a query is performed, a small amount of blocking occurs in order to take your Prisma ORM query and build the appropriate SQL statement.
For individual queries, compilation takes between 0.1ms and 1ms, barely noticeable in isolation. But under high concurrency, this overhead adds up and creates event loop contention that affects overall application throughput.

Query caching is one part of solving this. Take these two queries:
// Get Alice's user info
const alice = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
});
// Get Bob's user infor
const bob = await prisma.user.findUnique({
where: {
email: 'bob@prisma.io',
},
});These two queries have the exact same shape, the only dynamic part is the email. Prisma Client now parameterizes the query and reuses the static parts with minimal overhead. Parameterization separates the query structure from the values being passed:
prisma.user.findUnique({
where: {
email: %1 // cache key
//↑
// %1 = 'alice@prisma.io' (or 'bob@prisma.io')
}
})What’s great here is that in most applications, you typically run the same shape of query repeatedly. Our goal is that, with caching in place, a query only needs to be built once.
How Prisma determines what to cache
The caching mechanism is schema-aware. It uses metadata from your Prisma schema to determine exactly which fields can be safely parameterized and what types they accept. This includes:
- Scalar values: strings, numbers, booleans
- Rich types: DateTime, Decimal, BigInt, Bytes, Json
- Enum values: validated against the schema's enum definitions
- Lists: arrays of scalars or enums
- Nested objects: arguments in relation queries and filters
Structural parts of the query that affect the query plan (like field selections, ordering directions, or filter operators) are never parameterized and always contribute to the cache key, ensuring correctness.
Now, there are still other factors at play here that could impact overall performance. Node is single threaded, and doesn’t have the multi-threaded runtime provided by Rust/Tokio. Options to consider are to use the built-in node:cluster module, a process manager like PM2, or your deployment platform's scaling features if you wish to recover some of that parallelism. This benefits not just Prisma but your entire application's ability to handle concurrent load:
import cluster from 'node:cluster'
import { availableParallelism } from 'node:os'
if (cluster.isPrimary) {
for (let i = 0; i < availableParallelism(); i++) {
cluster.fork()
}
} else {
// Start your application server here
}Keeping things moving
We are continuing to improve Prisma 7 performance and want to hear from you if you are still experiencing performance issues after applying the recommendations above. Please open an issue on GitHub with details about your setup and the performance characteristics you are seeing.
Be sure to follow us on social media to stay up to date with the latest releases of Prisma ORM and Prisma Postgres:
Keep reading

How One Founder Builds a Live Sports Platform Without a Database Team
How Xeito uses Prisma ORM and Prisma Postgres to ship live scoring, leagues, payments, and player workflows without a database team.

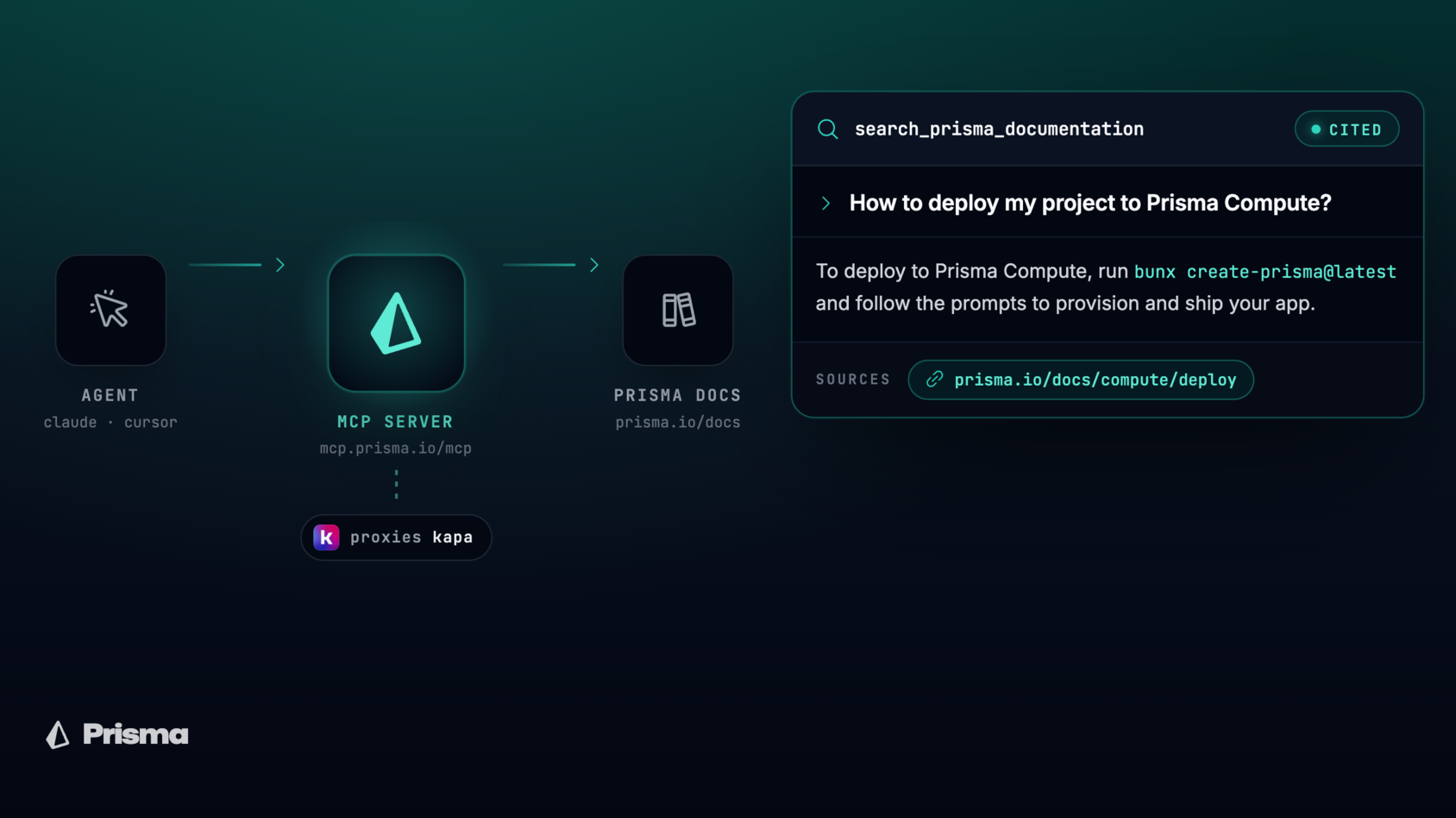
Search the Prisma Docs Using Your Coding Agent
The Prisma MCP server now answers documentation questions in your editor. Ask about ORM, Postgres, or Compute and get a cited answer, no tab-switching, no extra setup.

Build your next app with Prisma
Start free. Scale when you’re ready.