Saving Black Friday With Connection Pooling

Connection pooling is crucial for ensuring your data-driven app can handle massive load without failure. In this blog, we explore how connection pooling with Accelerate can save an online e‑commerce platform deployed in a serverless environment during peak traffic on Black Friday.
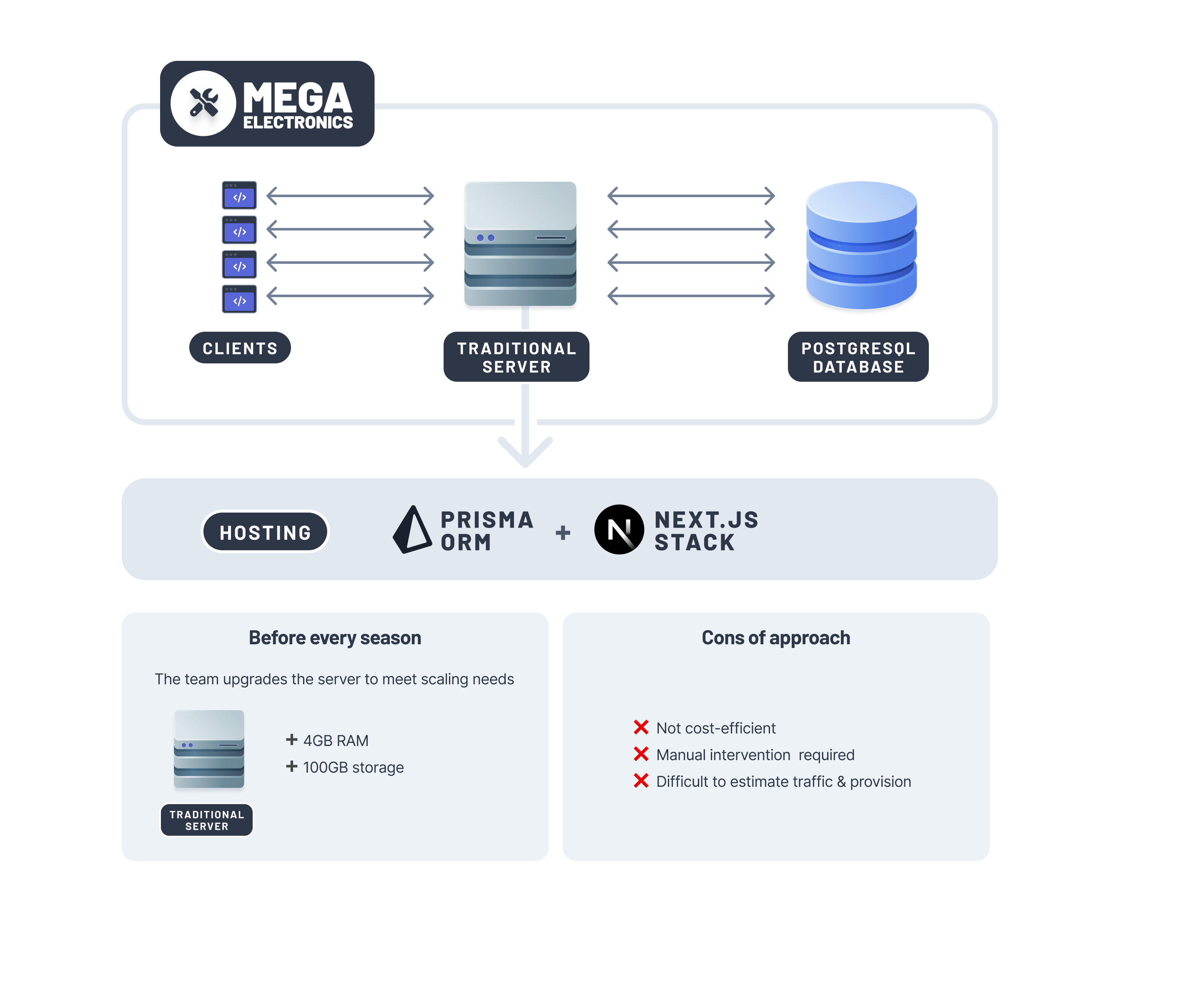
Imagine that your company, Mega Electronics, has an e-commerce app built using Next.js and Prisma ORM with PostgreSQL, which sells electronic devices. Mega Electronics is deployed on a traditional server and experiences consistent traffic from across the globe.
As high sales seasons approaches, your team anticipates traffic surges due to increased demand for your products. To prepare, your team upgrades the backend server by adding 100GB of storage and 4GB of RAM. However, this manual process of increasing server resources proves to be time-consuming and tedious. To streamline operations, your team decides it would be more efficient if the infrastructure could automatically scale with demand.
Moving to serverless and edge
Serverless environments offer the perfect solution for scaling servers based on real-time demand. They optimize costs by dynamically scaling down during periods of low traffic and scaling up during peaks. Each serverless function, however, initiates a separate database connection for API requests, which can lead to issues we'll discuss in this blog.
To make sure your app automatically meets scaling needs, your team decides to migrate your app to a serverless environment. To further reduce page loading times for users worldwide, your team decides to use an edge runtime for some APIs so that the data is served to your users from a server closest to their location. Because Prisma ORM and Next.js have support for edge runtimes, migrating some of the APIs is straightforward.
However, during weekends or small sales seasons, when traffic increases, your team starts seeing error messages from the database that say, “Sorry! Too many clients already.”
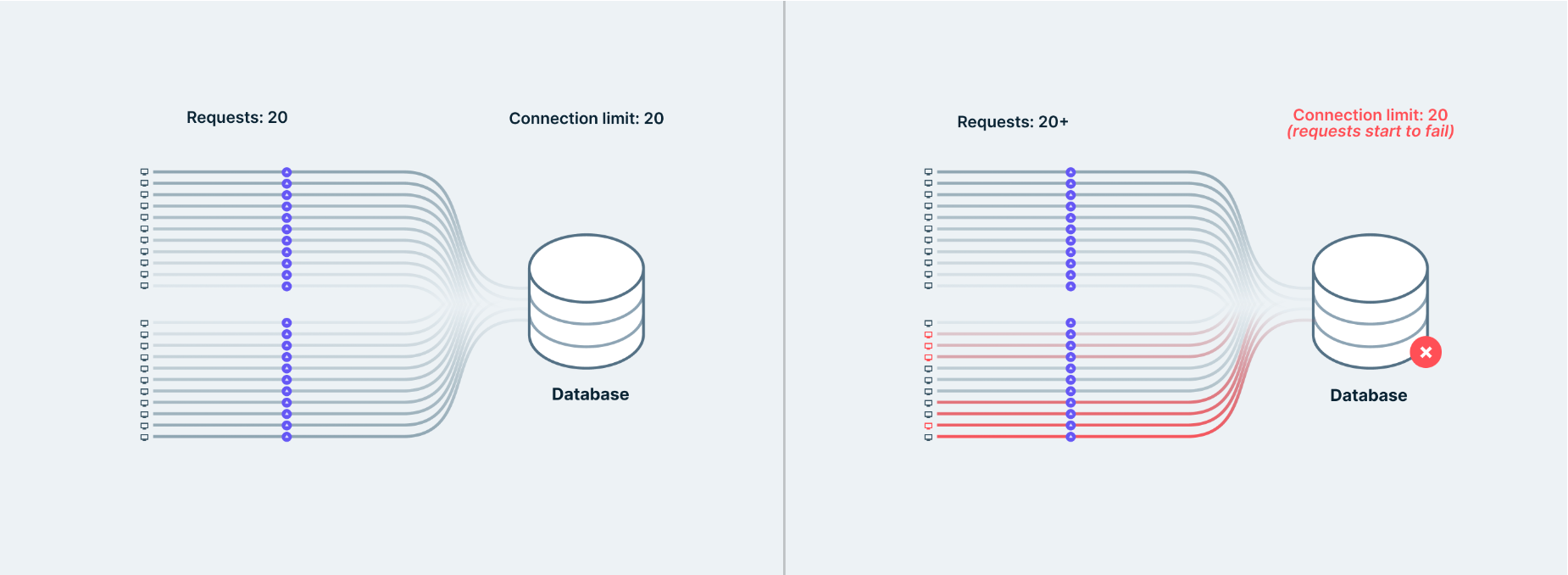
This error occurs due to the database being overloaded as each serverless function spawns a new connection to the database, overwhelming its connection limit. To address this issue, your team upgrades the database to handle more connections, anticipating improved performance under higher loads. Your team realizes that the frequent updates are costing more money and resources. Thankfully, the upgrade proves effective, as the larger instance with the ability to accept more connections can now manage the increased influx of connections.
The unprecedented traffic on Black Friday
It is Black Friday, bringing a huge wave of shoppers to Mega Electronics. Just as the holidays kick off, disaster strikes: Mega Electronics goes down.
The culprit? The database connection pool is overwhelmed again, and despite the upgrades to the database, the error message “Sorry! too many clients already” reappears, especially from the API endpoints using an edge runtime. The database connection pool was overwhelmed again from those routes as the database connections weren’t reused at all and the traffic was significantly higher than expected. Your team figured that upgrading the database again to handle more connections would become very expensive and wasn’t a practical solution. The aftermath of the event led to unhappy customers and a loss of potential sales.
Imagine there were 10,000 requests that failed during downtime. If we assume each request represents a potential customer who would've spent $2 on average, then the total lost sales would be 10,000 requests x $2 each, which equals $20,000.
Why the database can become a bottleneck in serverless or the edge
Serverless and edge apps usually don’t have state and can scale massively. On the other hand, database connections are stateful, require reuse, and generally have limited scalability.
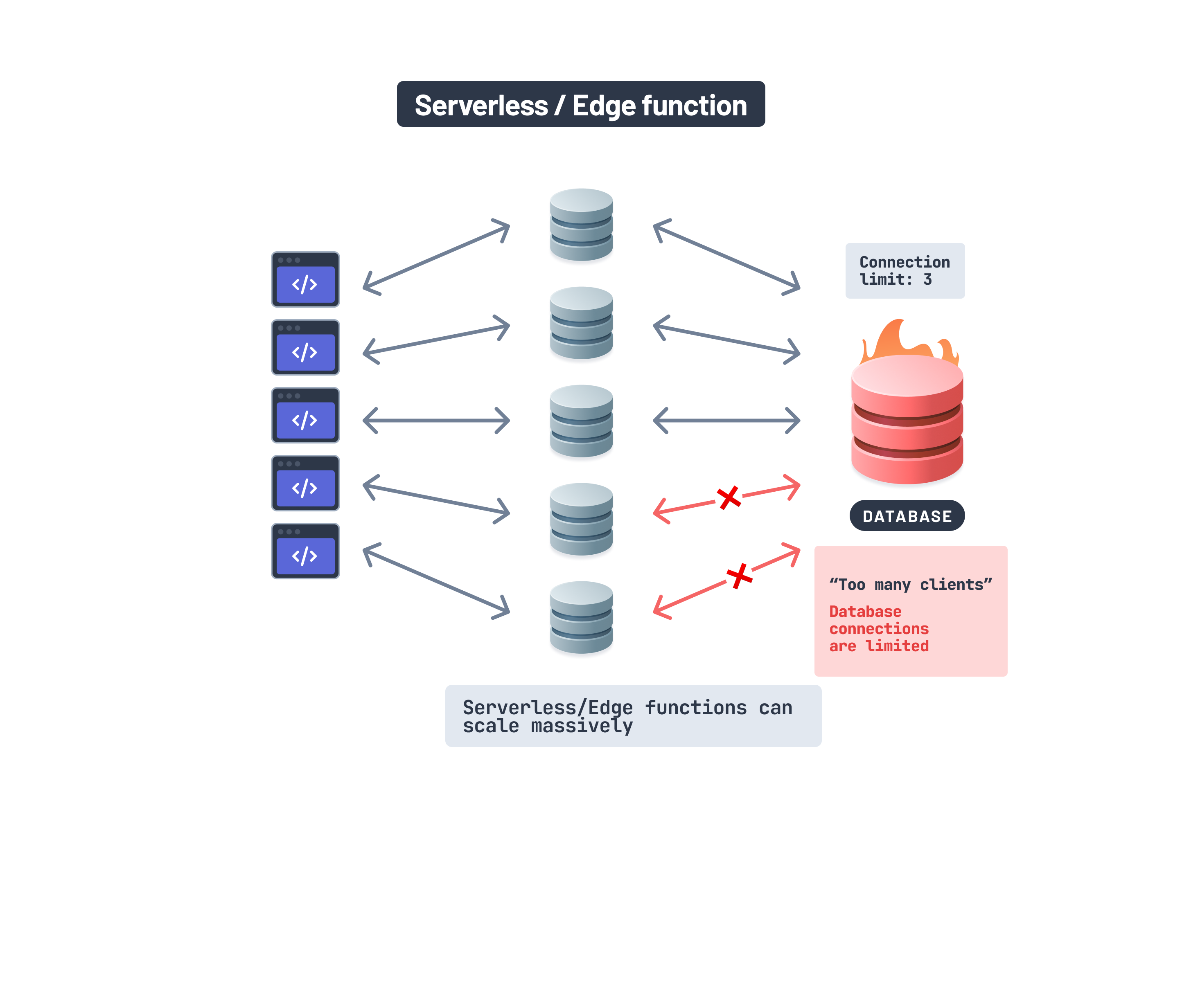
When a new function is invoked, a connection to your database is created. Databases can only have a limited number of connections to them, and setting up or closing a connection is usually very costly in terms of time. Hence, even if your team upgraded the database instance to accept more connections, the performance wouldn’t improve significantly. Your team finally decides to solve the problem at its root and decides to introduce an external connection pooler.
The power of connection pooling
A connection pool is essential for reusing and managing database connections efficiently in serverless and edge apps. It prevents your database connections from getting easily exhausted, saving you the cost of frequent database upgrades.
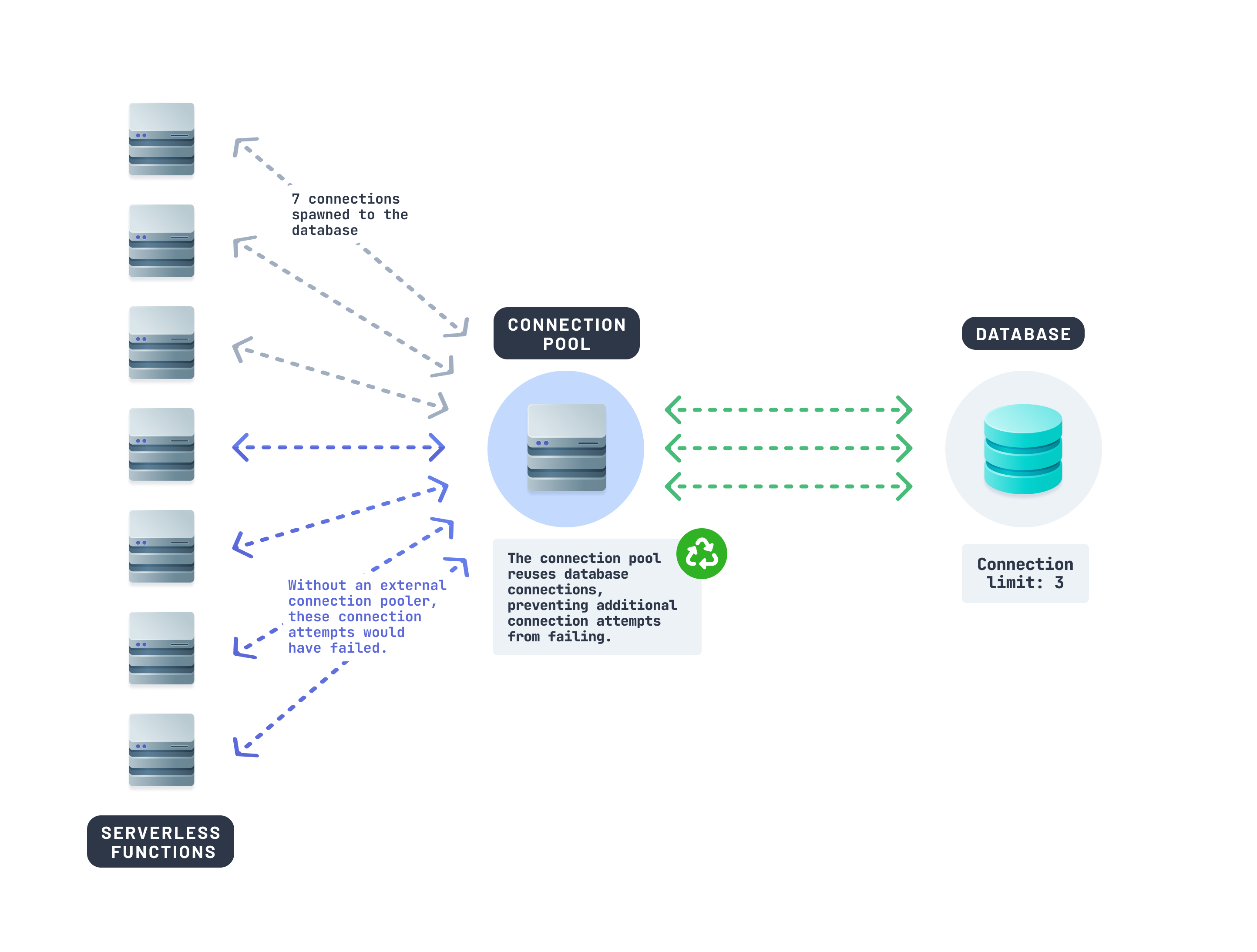
Your team considers three options for introducing an external connection pooler to the stack:
- Implementing a standalone server to manage connections: This approach introduces more challenges for your team. Managing your own connection pooling infrastructure would lead to high overhead in maintenance and developer operations.
- Using a popular reliable open-source option like PgBouncer: While robust, this solution requires your team to deploy and maintain it, resulting in high operational and management overhead.
- Using Prisma Accelerate, a managed connection pooling solution: Given that your team already uses Prisma ORM, this option integrates seamlessly with your setup. It simplifies the process by eliminating additional training and reducing maintenance and operational overhead.
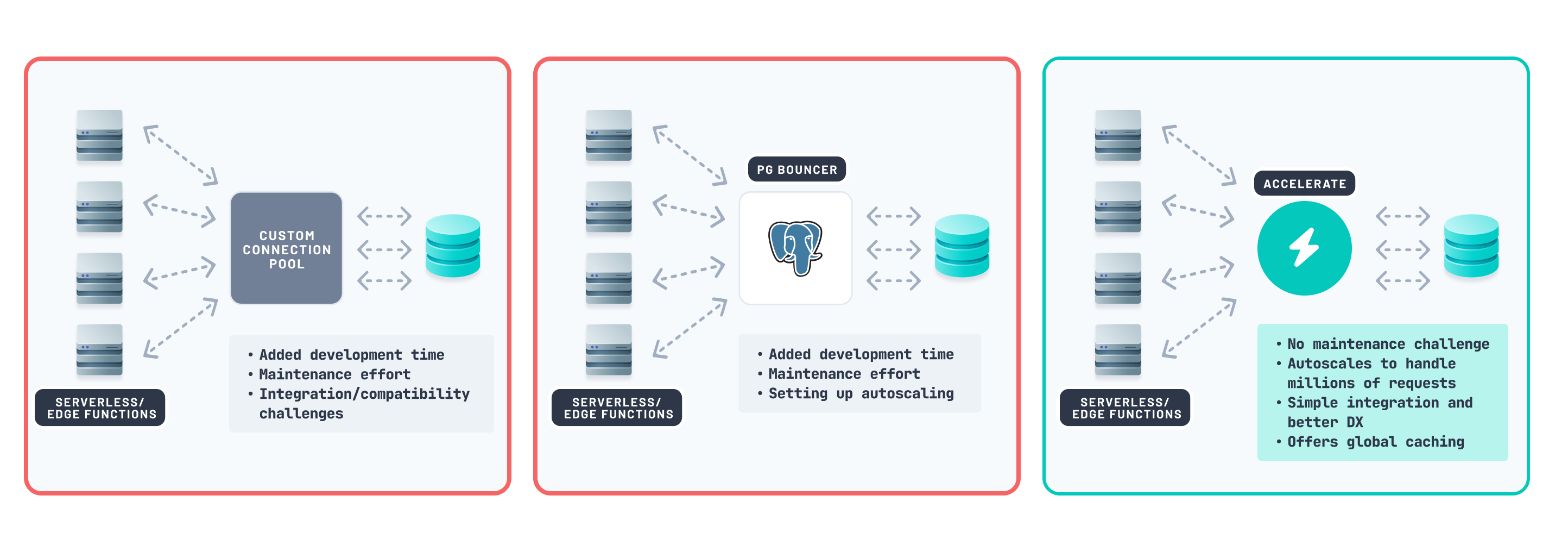
Your team believes Prisma Accelerate is the best solution for tackling the connection pooling issue with minimal maintenance. It robustly scales database connections during peak traffic, ensuring smooth operation.
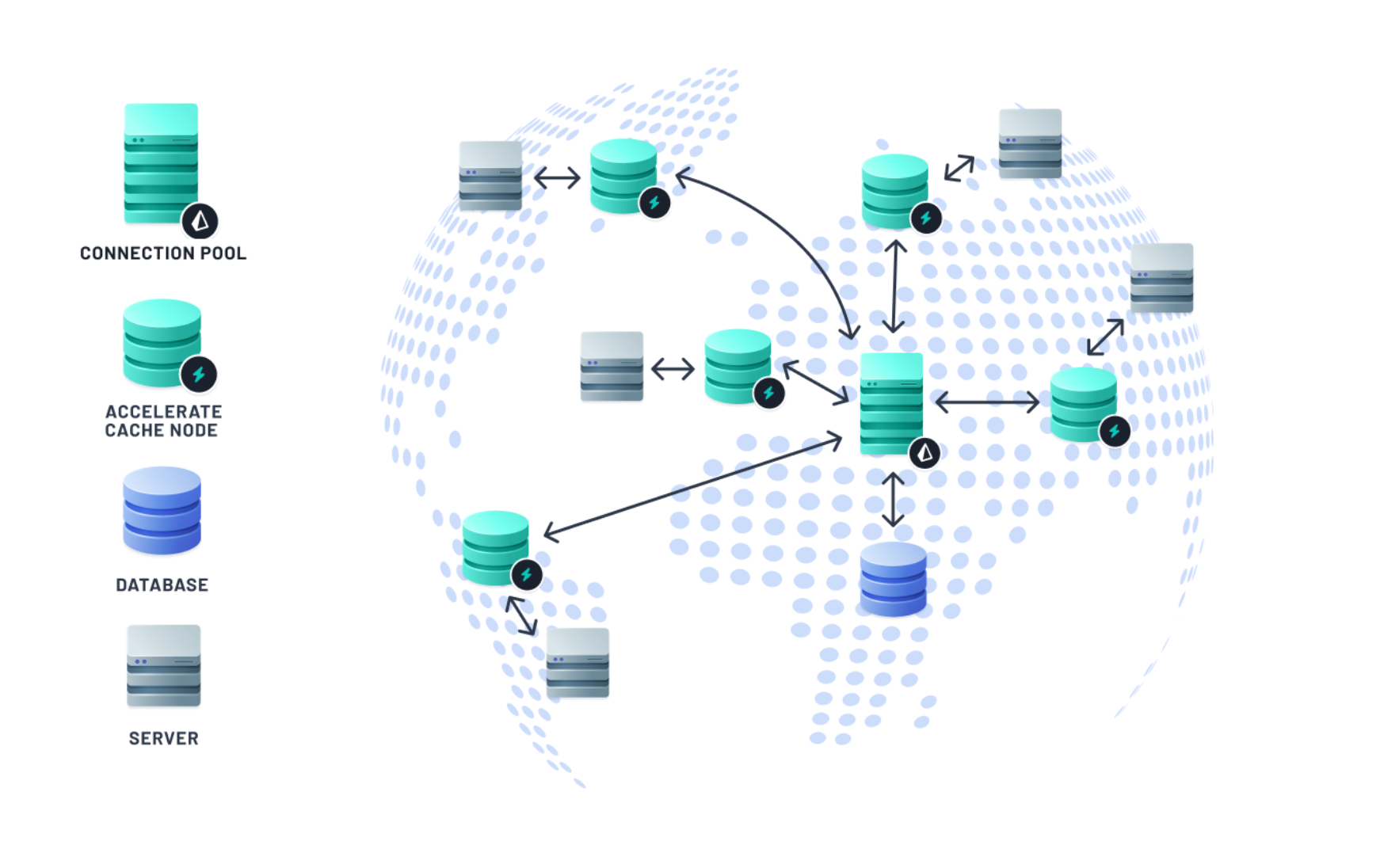
Accelerate — The connection pool that just works
Prisma Accelerate offers a connection pooler across 16 regions and an opt-in global cache. It helps you ensure your database connections aren’t easily exhausted and enables your app to run smoothly during periods of high load. To add Prisma Accelerate to a project, follow the getting started guide and install all the required dependencies. Then, adding connection pooling with Prisma Accelerate to your Prisma ORM project will look like this:
import { PrismaClient } from '@prisma/client/edge'
import { withAccelerate } from '@prisma/extension-accelerate'
// This will route all Prisma ORM queries through the connection pool
const prisma = new PrismaClient().$extends(withAccelerate())You can also see Prisma Accelerate improving the performance of a serverless function under high load by watching the video below:
Bonus: Cache your queries with Accelerate
In addition to connection pooling, Prisma Accelerate’s global caching vastly improves the performance of your serverless and edge apps. Whenever you cache a query result with Prisma Accelerate, it stores the result at the edge, in a data center close to the user. This allows data to be delivered to your users in under ~5 to 10 milliseconds, resulting in more responsive apps. To learn more about how caching is beneficial, read our blog on caching.
Key takeaways
In Mega Electronics' story, the lesson is clear: connection pooling is crucial for handling peak traffic spikes and scaling your serverless and edge apps. Prisma Accelerate makes this easier, ensuring your app stays fast and reliable, even when faced with crazy traffic.
Prisma Accelerate reduces the need for constant manual intervention, freeing up valuable time for your team to focus on innovation and business growth. With improved reliability and great DX, adopting Prisma Accelerate isn't just a technical upgrade—it's a strategic investment in the success of your online business. This means fewer instances of downtime for your business, keeping customers satisfied and potential sales intact.
Keep reading

Price the Work, Not the Workflow
Agents can ship, preview, test, and retry in loops. Infrastructure pricing should charge for the work an app performs, not the workflow around it.


App Hosting and Compute Platforms for AI Agents in 2026
A field guide to the 2026 wave of app-hosting and compute platforms (Prisma Compute, Neon, Cloudflare Containers, Hosting.com, Unkey, and Insforge) and how close each gets to one coherent stack for agents.

Build your next app with Prisma
Start free. Scale when you’re ready.