Working With Data in Large Teams

When multiple teams share a database, things break. Migrations conflict, queries start to bloat, or ownership gets murky.
This post breaks down how large teams can build resilient data workflows—using SQL, ORMs, or both—while maintaining speed and autonomy. We’ll explore real-world patterns like expand-and-contract, schema CI, query conventions, and how to know when to use raw SQL.
If you're scaling teams and databases, this one’s for you.
Why data workflows fall apart at scale
As teams grow, they often collide in shared database environments. The result? Sloppy migrations, unexpected table changes, and nobody quite sure who owns what.
When ownership is vague, even well-meaning changes can cause breakages. This is especially common in fast-moving product teams that don’t have clearly defined database protocols.
Some common breakdowns occur when:
- One team ships a migration that drops a column another still needs
- Tables become bloated with fields serving conflicting purposes
- A single schema file has five owners and zero accountability
Sometimes, scaling is less about tech and more about clarity.
Pick one workflow and make it boring
Giving teams multiple ways to manage the same task might seem flexible—but it often results in inconsistency and confusion. A single, boring workflow reduces mental overhead and promotes smoother collaboration.
There are three common approaches teams use to manage schema changes:
| Approach | Examples | Description |
|---|---|---|
| Migration-first | Prisma, Rails, Knex | Write schema migrations in code and commit them to version control |
| Model-first | Django, Sequelize | Define schema via application models, and generate database changes automatically |
| DDL-first | Raw SQL, Liquibase, Atlas | Write and review SQL statements directly—offering full control and transparency |
Tip: DDL stands for Data Definition Language—SQL statements like
CREATE,ALTER, or DROP that define database structure.
Stick with one approach across teams. Mixing styles without discipline makes your workflow harder to debug and nearly impossible to scale.
Treat schema like application code
Would you ship app code without a pull request? Probably not. Database schema deserves the same level of scrutiny.
Make sure to adopt the following practices:
- Version every schema change in Git
- Review schema changes through pull requests
- Use diff tools like Prisma Migrate, Atlas, or Liquibase to visualize changes before they go live
This creates transparency, catches mistakes early, and builds a historical trail of every evolution.
Use the expand and contract pattern
Big schema changes don’t need to be risky. The expand-and-contract pattern breaks changes into non-breaking steps that minimize downtimes:
- Expand: Add the new field, table, or structure
- Migrate: Backfill and update any references or dependencies
- Contract: Remove or rename the old parts only after everything is safe
This avoids breaking production, supports rolling deployments, and helps teams maintain uptime, even when changes are complex.

It's a reliable pattern whether you're using raw SQL, Prisma, Rails, or any other system. Visit our dataguide to learn more about the expand and contract pattern.
Define when to use SQL and when to use an ORM
SQL and ORMs are complementary—not competing—tools. The key is knowing when each is the better fit based on your goals: speed of development, control over queries, and long-term maintainability.
Use an ORM when:
- You want to move quickly on product development
- You prefer readable, maintainable, and type-safe code
- Your team benefits from abstracting away boilerplate and repetitive tasks
- You want to de-risk development by not requiring every developer to be a SQL expert
Use raw SQL when:
- You’re optimizing complex joins or performance-critical paths
- You need fine-grained control over queries, indexes, or execution plans
- You’re building reporting-heavy internal tools that rely on custom logic
You don’t have to choose just one. Most modern applications combine both: use an ORM to move fast and stay type-safe, and drop down to raw SQL when performance or flexibility demands it—ideally wrapping those queries in typed helpers to keep things maintainable.
For example, TypedSQL in Prisma ORM lets you use raw SQL with full TypeScript types, right next to your ORM calls. This gives you the flexibility of SQL without giving up type safety or maintainability.
Some popular tools include:
Kysley (TypeScript), Sequelize (Node.js), Django ORM (Python), Knex (SQL builder), raw SQL via SQLX or pgx (Rust), or even SQL scripts with migration tools like Atlas or Liquibase.
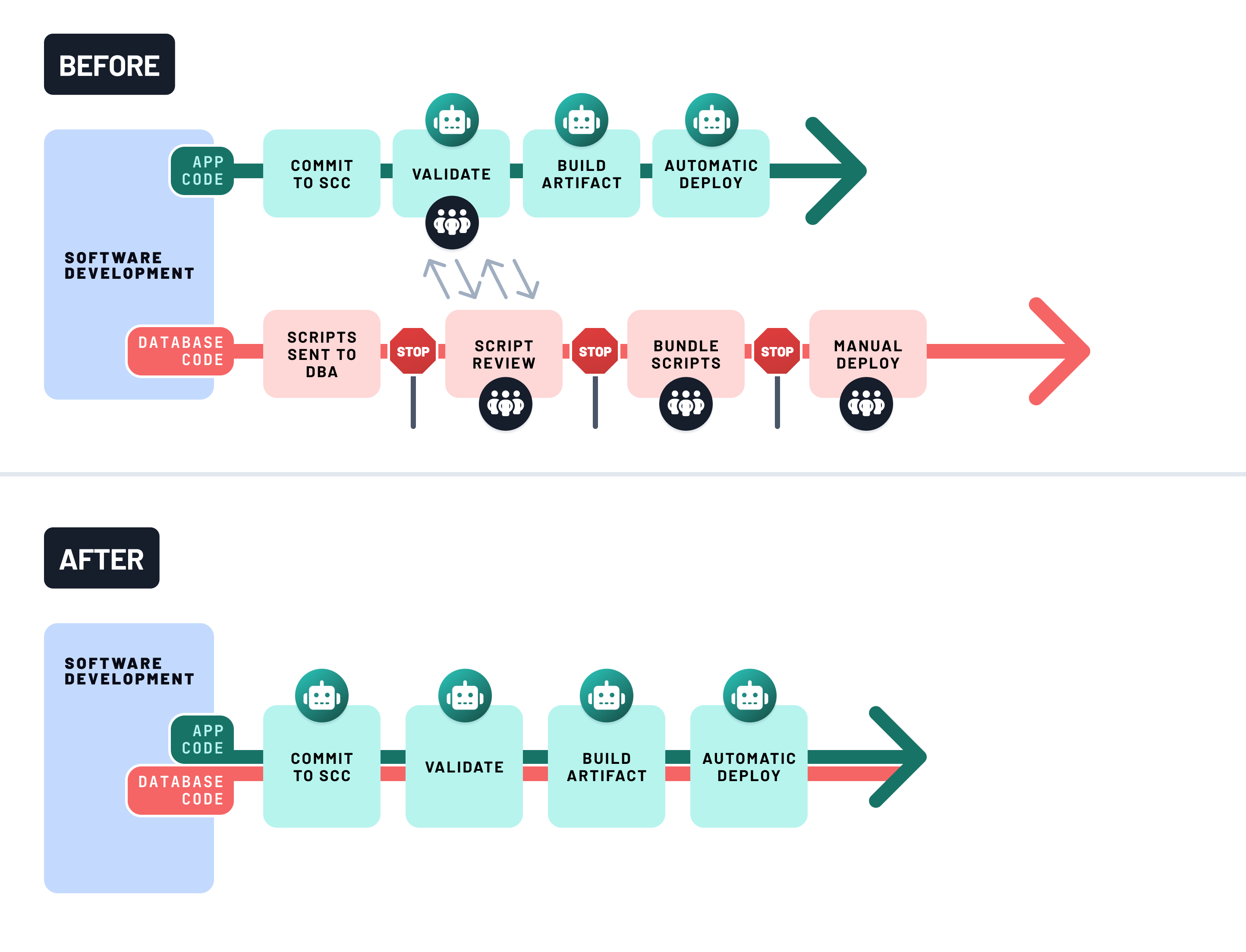
Use CI to enforce database safety
Without safeguards, schema changes can silently break production. Continuous Integration (CI) helps prevent that by validating each change before it’s merged.
A robust database CI pipeline should:
- Preview schema diffs using tools like Prisma Migrate or Atlas to detect breaking changes
- Run integration tests against a temporary or shadow database to validate behavior end-to-end
- Fail the build if destructive actions are detected (e.g. dropping columns, data loss)
Set this up with GitHub Actions, Docker, and your migration tool of choice. For example, use a job that:
- Boots a clean PostgreSQL container
- Applies migrations
- Runs your test suite
- Parses migration plans for potentially unsafe operations
This catches regressions before they hit production, and makes schema evolution a shared, reviewable part of your workflow—not a side effect of deployment.
Use OpenAPI and Swagger to define boundaries
When teams exchange data over APIs, clear contracts are essential to avoid miscommunication and bugs. OpenAPI is a widely adopted specification for describing RESTful APIs in a structured format that both humans and tools can understand.
Swagger is a popular set of tools built around the OpenAPI standard. It lets teams document, visualize, and test APIs with minimal friction.
Using tools like Swagger helps teams:
- Define API boundaries and expected behavior explicitly
- Auto-generate types and client code for both frontend and backend
- Validate changes to catch breaking updates early
- Browse and test API endpoints through interactive documentation
- Help frontend teams move faster by mocking responses and integrating typed clients
- Improve developer onboarding by making APIs self-explanatory and discoverable
This approach works especially well in microservice architectures or when multiple teams rely on shared internal APIs.
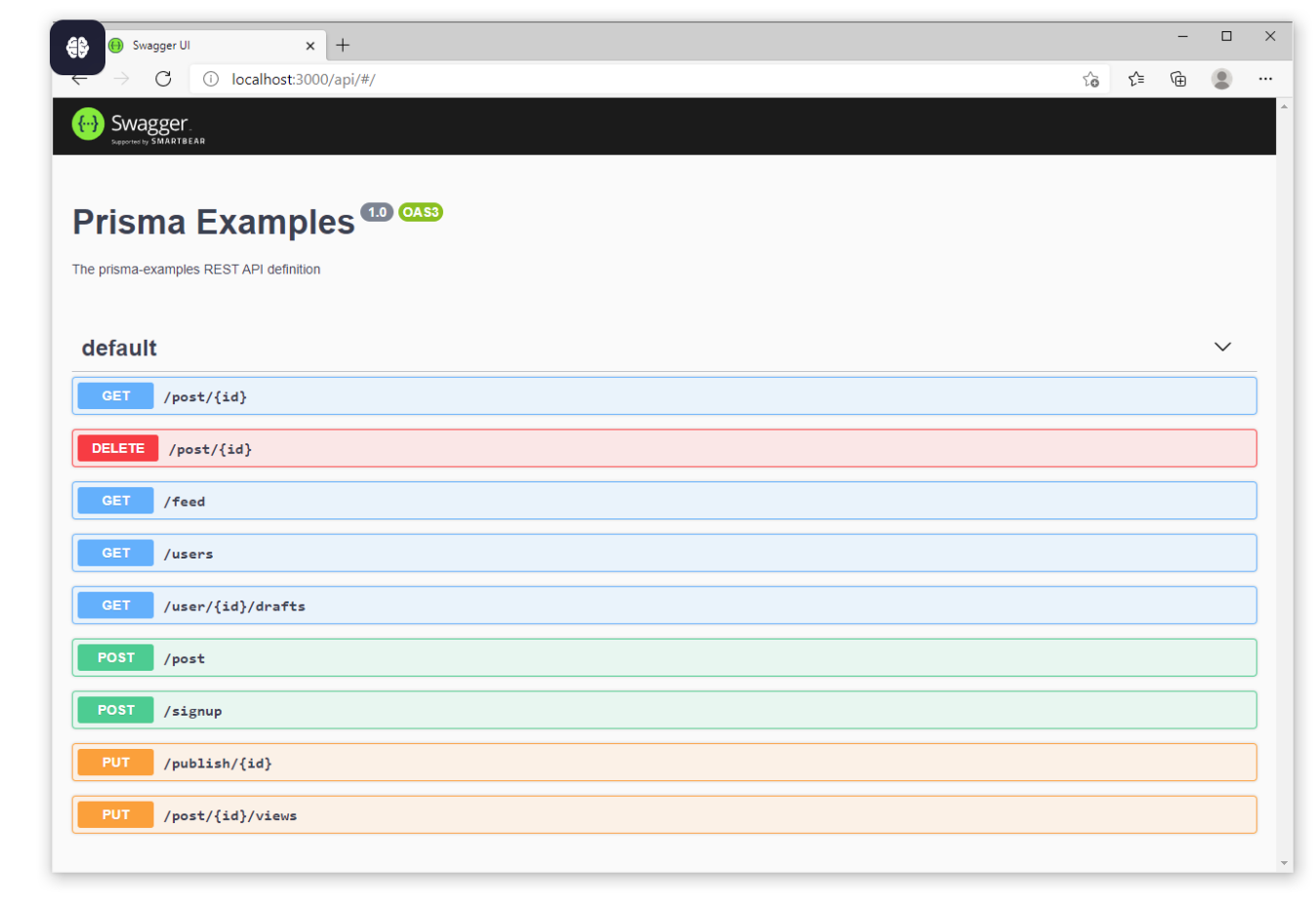
Instead of relying on tribal knowledge or Slack messages to explain how APIs work, developers can explore, prototype, and integrate confidently—powered by accurate, always-up-to-date documentation.
Co-locate queries, standardize structure
Scattered logic is hard to scale. A consistent file structure makes your codebase easier to navigate, reason about, and extend—especially as your team grows.
Instead of splitting data access logic across models/, utils/, and services/, group queries by domain. This mirrors patterns from the CLEAN architecture and modular monolith design, where feature boundaries—not technical layers—drive the structure.
db/
└── queries/
├── user/
│ ├── createUser.ts
│ ├── getUserById.ts
│ └── query.types.ts
├── project/
│ ├── createProject.ts
│ ├── listProjectsByUser.ts
│ └── query.types.ts
├── billing/
│ ├── createInvoice.ts
│ ├── getInvoiceById.ts
│ └── query.types.ts
├── auth/
│ ├── getSession.ts
│ ├── createSession.ts
│ └── query.types.ts
├── analytics/
│ ├── trackEvent.ts
│ ├── getEventSummary.ts
│ └── query.types.ts
└── internal/
├── getSystemStatus.ts
├── getAdminUsers.ts
└── query.types.tsWhy this works:
- Encourages clear ownership and encapsulation per domain
- Speeds up onboarding by making query location predictable
- Reduces cross-cutting concerns and inconsistent abstractions
- Keeps your logic close to where it's used—easier to test, document, and refactor
Design patterns like CLEAN or feature-based architecture aren’t just academic, they make collaboration smoother and systems more resilient over time. A good structure scales with your team and your product.
Share types across systems
Type mismatches between frontend and backend are a common source of bugs—like treating a number as a string, or missing optional fields. These issues often arise when teams define the same types in multiple places, leading to duplication and drift.
Code generation solves this by producing types directly from your database schema or query definitions. This gives you a single source of truth that stays in sync across your stack.
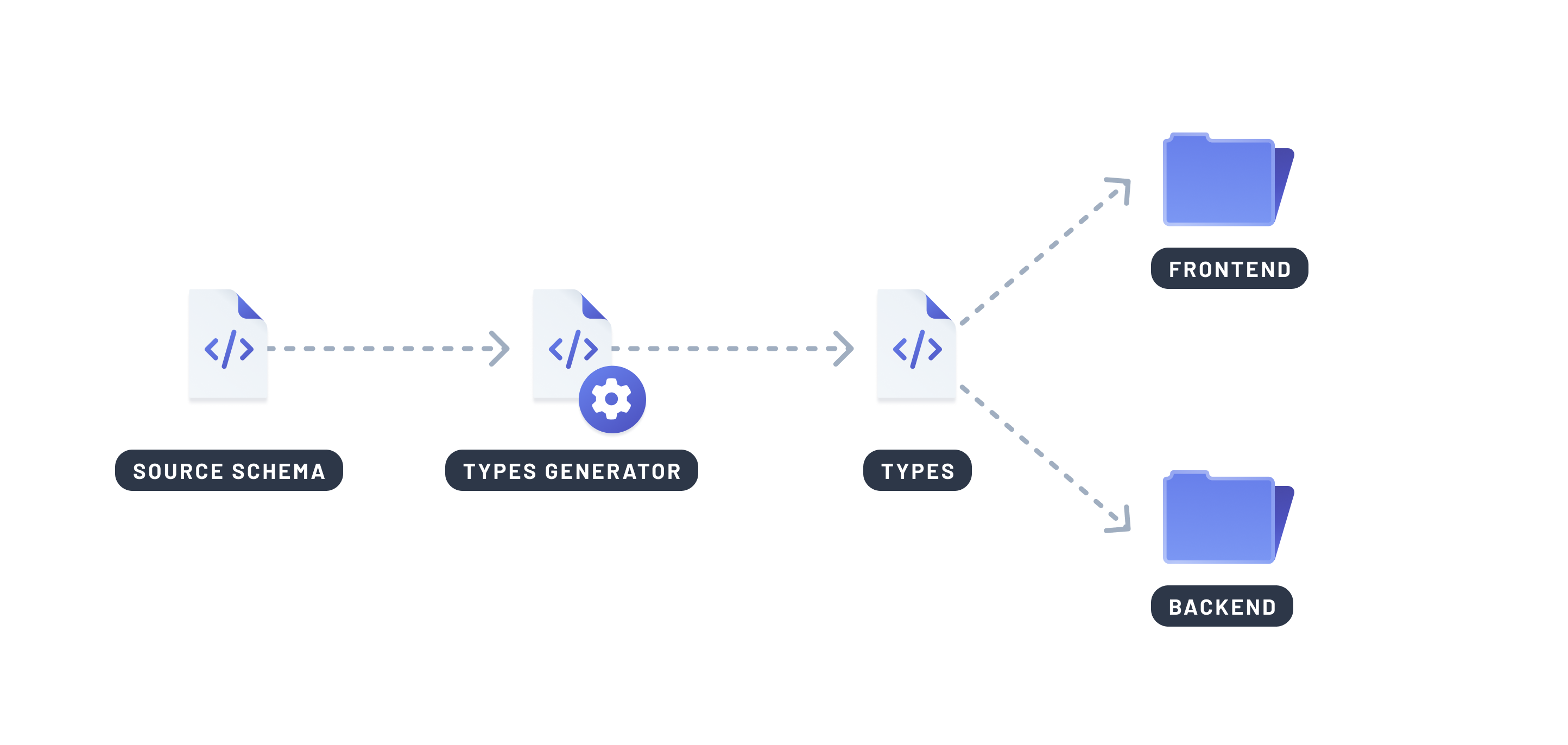
Why it matters:
- Avoids manual duplication of types across backend and frontend
- Prevents bugs caused by type mismatches or out-of-date contracts
- Enforces correctness at compile time instead of at runtime
- Makes refactoring safer with better IDE support and autocomplete
Examples of tools that help with this: Prisma ORM (TypeScript), SQLC (Go), SeaORM (Rust), Pydantic (Python)
When your application layers share the same type definitions, you reduce bugs, increase developer confidence, and ship faster with fewer surprises.
Let AI catch the obvious (and not-so-obvious)
Modern AI tools help teams move faster without sacrificing quality. By integrating large language models (LLMs) into your development workflow, you can automate the tedious, catch the subtle, and focus on solving real problems.
Use LLM-powered assistants to:
- Spot potentially unsafe or breaking schema changes
- Summarize pull request diffs for quicker reviews
- Generate test data, edge cases, and seed scenarios
- Recommend improvements or flag risks directly in pull requests
Examples of tools that help with this:
Windsurf, CodiumAI, Sweep.dev (schema & PR review), GitHub Copilot, Cursor (inline coding help), OpenDevin (backend automation).
Here’s an example from the Laravel ecosystem, called Enlightn, a tool that scans your app and offers actionable recommendations across performance, security, and more:
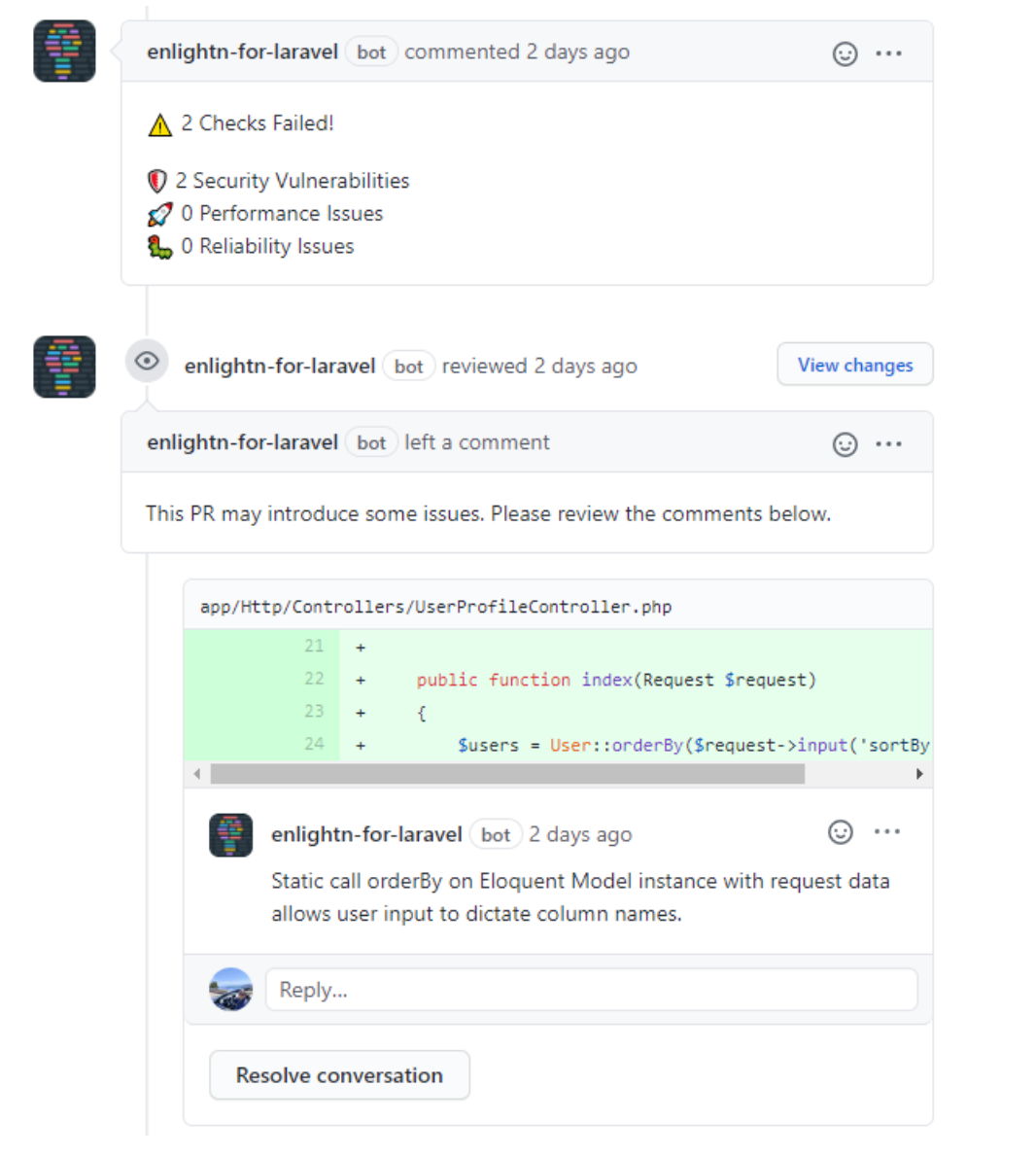
AI isn't just for speed—it’s your second pair of eyes. Used wisely, it helps you write safer code, reduce review fatigue, and offload routine tasks so you can stay focused on the bigger picture.
Optimize for team velocity, not query perfection
Well-tuned queries are valuable, but the ability to ship reliably and consistently matters more. Prioritize workflows that help your entire team move faster without sacrificing stability.
Focus on processes that:
- Encourage safe defaults and sensible conventions
- Make onboarding straightforward for new developers
- Catch issues early through tooling and CI
- Balance performance with code clarity and maintainability
Examples of velocity-focused practices:
Use ORMs with guardrails, linters and formatters, type-safe APIs, and CI checks for query regressions.
Fast teams ship more value than perfectly tuned queries, optimize for workflows that scale with your team, not just your database.
TLDR: Build a workflow, not a mess
You’ve made it this far—great! Here’s a quick recap to keep things sticky. Think of this table not as a checklist, but as a lens to diagnose and refine your current setup. Most data challenges at scale are less about technology, more about clarity and alignment.
| Problem | Solution |
|---|---|
| Conflicting migrations | Use PRs, version control, expand-contract |
| Schema ownership confusion | Organize queries, share types |
| Fragile raw SQL | Use typed helpers, CI validation |
| Teams moving too slow | Choose boring, fast workflows |
| Surprising API changes | Use OpenAPI and validate in CI |
A good data workflow is one your team understands, trusts, and can improve. That’s what scales. Choose discipline and clarity. When everyone knows how things work, teams move faster—together.
Join the conversation, shape better workflows
If this helped you, we’d love to hear about it. Tag us on X and share what you're building. Or hop into our Discord if you want to chat, troubleshoot, or nerd out about databases and performance.
We also post video deep dives regularly on YouTube. Hit subscribe if you’re into that kind of thing. More examples, more performance tricks, and maybe a few surprise launches. We’ll see you there.
Keep reading

Claude Generated 50 Websites Overnight. Prisma Compute Helped Ship Them.
Ali Fatemi gave Claude the Prisma docs and CLI, then used Prisma Compute to turn AI-generated websites into working URLs.


Prisma Compute vs Vercel Pricing
Prisma Compute vs Vercel, priced line by line: the same workload runs ~$98 vs ~$236. See why, and why Vercel bills the workflow while Prisma bills the work.

Build your next app with Prisma
Start free. Scale when you’re ready.