How to wrap a REST API with GraphQL - A 3-step tutorial

REST APIs have been the standard for building web APIs for the past decade. In 2015, Facebook introduced a new and open-source query language for APIs that comes with notable advantages compared to REST: GraphQL!
Since then, many developers want to start using GraphQL but are stuck with their legacy REST APIs. In this article, we’re going to introduce a lightweight process for turning REST into GraphQL APIs. No special tooling required!
REST is schemaless
One of the biggest drawbacks of REST APIs is that they don’t have a schema describing what the data structures that are returned by the API endpoints look like.
Assume you’re hitting this REST endpoint with a GET request: /users
Now, you’re flying completely blind. If the person who designed the API is sane, it is probably safe to assume that it will return an array of some kind of user objects — but what data each of the user objects actually carries can in no way be derived just from looking at this endpoint.
Note that there are ways how this problem can be solved for REST APIs, using tools like JSON Schema or Swagger / Open API Spec.
When using GraphQL, the core component of each API is a strongly typed schema that serves as a strict contract for the shape of the data that can be queried. In the remainder of this article, you will learn how you can deduce and implement a GraphQL schema from the JSON structure of a REST API.
A sample REST API
In this article, we’ll take the example of a simple blogging application. Assume there are two models, users and posts. There is a one-to-many relationship between them in that one user can be associated with multiple posts.
For that example, we’d have the following endpoints:
1. /users
2. /users/<id>
3. /users/<id>/posts
4. /posts
5. /blog/posts/<id>
6. /blog/posts/<id>/userIf you want to play around with this API, you can check out the code in this repository.
With this design, we’re able to query:
- a list of users
- a specific user given their
id - all posts of a specific user given their
id - a list of posts
- a specific post given its
id - the author of a post given its
id
There are effectively two major ways how we can design the data structures to be returned by a REST API: flat and nested.
REST API Design: Flat layout
In a flat design, relationships between the models are expressed via IDs that are pointing to the related items.
For example, a call to the /users endpoint would return a number of user objects which each have a field postIds. This field contains an array of the IDs of the posts each user is associated with:
[
{
"id": "user-0",
"name": "Nikolas",
"postIds": []
},
{
"id": "user-1",
"name": "Sarah",
"postIds": ["post-0", "post-1"]
},
{
"id": "user-2",
"name": "Johnny",
"postIds": ["post-2"]
},
{
"id": "user-3",
"name": "Jenny",
"postIds": ["post-3", "post-4"]
}
]REST API Design: Nested layout
The flat API design might be preferred because its generally more slim than the nested one — however, it’s very likely that your clients will be running into the infamous N+1-requests problem with it: Imagine the client (e.g. a web app) needs to display a view with a list of users and the titles of their latest post.
In that scenario, you first need to make a request to the /users endpoint. This will return a list of IDs for the posts related to a user. So, now you need to make one additional request for each post ID to the /blog/posts/<id> endpoint to fetch the titles. Not nice!
To circumvent this problem, you can go with a nested API design. With that approach, instead of an array of IDs, each user object would directly carry an array of entire post objects:
[
{
"id": "user-0",
"name": "Nikolas",
"posts": []
},
{
"id": "user-1",
"name": "Sarah",
"posts": [
{
"id": "post-0",
"title": "I like GraphQL",
"content": "I really do!",
"published": false
},
{
"id": "post-1",
"title": "GraphQL is better than REST",
"content": "It really is!",
"published": false
}
]
},
{
"id": "user-2",
"name": "Johnny",
"posts": [
{
"id": "post-2",
"title": "GraphQL is awesome!",
"content": "You bet!",
"published": false
}
]
},
{
"id": "user-3",
"name": "Jenny",
"posts": [
{
"id": "post-3",
"title": "Is REST really that bad?",
"content": "Not if you wrap it with GraphQL!",
"published": false
},
{
"id": "post-4",
"title": "I like turtles!",
"content": "...",
"published": false
}
]
}
]This is a lot more verbose but avoids that clients run into the N+1-problem.
However, the nested approach certainly comes with its own problems! For APIs with larger model objects, bandwidth (especially on mobile devices) is likely to become a bottleneck. Another problematic aspect of this is the fact that clients in all likelihood won’t even need most of the data they’re downloading and thus are wasting the user’s bandwidth — this is referred to as overfetching.
Plus, even with the nested approach you’re not always guaranteed to get all the data you need. Imagine posts also had a relation to comments and the screen also needs to display the last three comments for the displayed article. This kind of nesting can go arbitrarily deep and with each level will become more problematic and slow down your app.
REST API Design: Hybrid layout
What ends up happening in practice is that the data that’s returned by the endpoints is designed on the go. This means the frontend team communicates its data requirements to the backend team and the backend team will include the required data in the payloads returned by the endpoints.
This introduces a lot of overhead in the software development process. It basically means that every design iteration on the frontend that involves a change in the displayed data needs to go through a process where the backend team is directly involved. This prevents fast user feedback loops and iteration cycles!
Not only is this approach extremely time-consuming, it also is brittle and error-prone. APIs that are changing a lot are hard to maintain and clients will have a hard time getting the right data. When fields are removed from certain API responses without the client being aware of it (or maybe the client was simply not updated and is still running against an older API version), there’s a high probability it’s going to crash at runtime due to missing data. Not nice!
GraphQL provides flexibility & security for clients
All the issues that we outlined above, the N+1-problem, overfetching and slow iteration cycles are solved by GraphQL.
The core difference between GraphQL and REST can be boiled down as follows:
- REST has a set of endpoints that each return fixed data structures
- GraphQL has a single endpoint that returns flexible data structures
This works because with GraphQL the client can dictate the shape of the response. It submits a query to the server that precisely describes its data needs. The server resolves that query and returns only the data the client asked for.
With GraphQL, the client dictates the shape of the response by sending a query that’s resolved by the server.
The way how data can be queried is defined in the GraphQL schema definition. Therefore, a client will never be able to ask for fields that don’t exist. Further, a query itself can be nested, so the client can ask for information of related items in a single request (thus avoiding the N+1 problem). Nifty!
Wrapping a REST API with GraphQL in 3 simple steps
In this section, we’ll outline how you can wrap REST APIs with GraphQL in 3 simple steps.
Overview: How do GraphQL servers work
GraphQL is no rocket science! In fact, it follows a few very simple rules which make it so flexible and universally adaptable.
In general, building a GraphQL API always requires two essential steps: At first you need to define a GraphQL schema, then you have to implement resolver functions for that schema.
To learn more about this process, be sure to check out the following article: GraphQL Basics: The Schema
The nice thing about this is that it is a very iterative approach, meaning you don’t have to define the entire schema for your API upfront. Instead, you can gradually add types and fields when necessary (think about it in a similar way of gradually implementing the REST endpoints for your API). This is precisely what’s meant with the term schema-driven or schema-first development.
GraphQL resolver functions can return data from anywhere: SQL or NoSQL databases, REST APIs, 3rd-party APIs, legacy systems or even other GraphQL APIs.
A huge part of GraphQL’s flexibility comes from the fact that GraphQL itself is not bound to a particular data source. Resolver functions can return data from virtually anywhere: SQL or NoSQL databases, REST APIs, 3rd-party APIs, and legacy systems.
This is what makes it a suitable tool for wrapping REST APIs. In essence, there are three steps you need to perform when wrapping a REST API with GraphQL:
- Analyze the data model of the REST API
- Derive the GraphQL schema for the API based on the data model
- Implement resolver functions for the schema
Let’s go through each of these steps, using the REST API from before as an example.
Step 1: Analyze the data model of the REST API
The first thing you need to understand is the shape of the data that’s returned by the different REST endpoints.
In our example scenario, we can state the following:
The User model has id and name fields (of type string) as well as a posts field which represents a to-many-relationship to the Post model.
The Post model has id, title, content (of type string) and published (of type boolean) fields as well as an author field which represents a to-one-relationship to the User model.
Once we’re aware of the shape of the data returned by the API, we can translate our findings into the GraphQL Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
content: String!
published: Boolean!
author: User!
}The SDL syntax is concise and straightforward. It allows to define types with fields. Each field on a type also has a type. This can be a scalar type like Int and String or an object type like Post and User. The exclamation point following the type of a field means that this field can never be null.
The types that we defined in that schema will be the foundation for the GraphQL API that we’re going to develop in the next step.
Step 2: Define GraphQL schema
Each GraphQL schema has three special root types: Query, Mutation and Subscription. These define the entry-points for the API and roughly compare to REST endpoints (in the sense that each REST endpoint can be said to represent one query against its REST API whereas with GraphQL, every field on the Query type represents one query).
There are two ways to approach this step:
- Translate each REST endpoint into a corresponding query
- Tailor an API that’s more suitable for the clients
In this article, we’ll go with the first approach since it illustrates well the mechanisms you need to apply. Deducing from it how the second approach works should be an instructive exercise for the attentive reader.
Let’s start with the /users endpoint. To add the capability to query a list of users to our GraphQL API, we first need to add the Query root type to the schema definition and then add a field that returns the list of users:
type Query {
users: [User!]!
}
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
content: String!
published: Boolean!
author: User!
}To invoke the users query that we now added to the schema, you can put the following query into the body of an HTTP POST request that’s sent to the endpoint of the GraphQL API:
query {
users {
id
name
}
}Don’t worry, we’ll show you in a bit how you can actually send that query.
The neat thing here is that the fields you’re nesting under the users query determine what fields will be included in the JSON payload of the server’s response. This means you could remove the name field if you don’t need the user’s names on the client-side. Even cooler: If you like, you can also query the related Post items of each user with as many fields as you like, for example:
query {
users {
id
name
posts {
id
title
}
}
}Let’s now add the second endpoint to our API:/users/<id>. The parameter that’s part of the URL of the REST endpoint now simply becomes an argument for the field we’re introducing on the Query type (for brevity, we’re now omitting the User and Post types from the schema, but they’re still part of the schema):
type Query {
users: [User!]!
user(id: ID!): User
}Here’s what a potential query looks like (again, we can add as many or as few fields of the User type as we like and thus dictate what data the server is going to return):
query {
user(id: "user-1") {
name
posts {
title
content
}
}
}As for the /users/<id>/posts endpoint, we actually don’t even need it because the ability to query posts of a specific user is already taken care of by the user(id: ID!): User field we just added. Groovy!
Let’s now complete the API by adding the ability to query Post items. We’ll add the queries for all three REST endpoints at once:
type Query {
users: [User!]!
user(id: ID!): User
posts: [Post!]!
post(id: ID!): Post
}This is it — we have now created the schema definition for a GraphQL API that is equivalent to the previous REST API. Next, we need to implement the resolver functions for the schema!
A note on mutations
In this tutorial, we’re only dealing with queries, i.e. fetching data from the server. Of course, in most real-world scenarios you’ll also want to make changes to the data stored in the backend.
With REST, that’s done by using the PUT, POST and DELETE HTTP methods against the same endpoints.
When using GraphQL, this is done via the Mutation root type. Just as an example, this is how we could add the ability to create, update and delete new User items to the API:
type Mutation {
createUser(name: String!): User!
updateUser(id: ID!, name: String!): User
deleteUser(id: ID!): User
}
type Query {
users: [User!]!
user(id: ID!): User
posts: [Post!]!
post(id: ID!): Post
}Note that the createUser, updateUser and deleteUser mutations would correspond to POST, PUT and DELETE HTTP requests made against the /users/<id> endpoint. Implementing the resolvers for mutations is equivalent to implementing resolvers for queries, so there’s no need to learn anything new for mutations as they follow the exact same mechanics as queries — the only difference is that mutation resolvers will have side-effects.
Step 3: Implementing resolvers for the schema
GraphQL has a strict separation between structure and behaviour.
The structure of an API is defined by the GraphQL schema definition. This schema definition is an abstract description of the capabilities of the API and allows clients to know exactly what operations they can send to it.
The behaviour of a GraphQL API is the implementation of the schema definition in the form of resolver functions. Each field in the GraphQL schema is backed by exactly one resolver that knows how to fetch the data for that specific field.
To learn more about the GraphQL schema definition and resolver functions, be sure to check out this article.
The implementation of the resolvers is fairly straightforward. All we do is making calls to the corresponding REST endpoints and immediately return the responses we receive:
const baseURL = `https://rest-demo-hyxkwbnhaz.now.sh`
const resolvers = {
Query: {
users: () => {
return fetch(`${baseURL}/users`).then(res => res.json())
},
user: (parent, args) => {
const { id } = args
return fetch(`${baseURL}/users/${id}`).then(res => res.json())
},
posts: () => {
return fetch(`${baseURL}/posts`).then(res => res.json())
},
post: (parent, args) => {
const { id } = args
return fetch(`${baseURL}/blog/posts/${id}`).then(res => res.json())
},
},
}For the user and post resolvers, we’re also extracting the id argument that’s provided in the query and include it in the URL.
All you need now to get this up-and-running is to instantiate a GraphQLServer from the graphql-yoga NPM package, pass the resolvers and the schema definition to it and invoke the start method on the server instance:
const { GraphQLServer } = require('graphql-yoga')
const fetch = require('node-fetch')
const baseURL = `https://rest-demo-hyxkwbnhaz.now.sh`
const resolvers = {
// ... the resolver implementation from above ...
}
const server = new GraphQLServer({
typeDefs: './src/schema.graphql',
resolvers,
})
server.start(() => console.log(`Server is running on http://localhost:4000`))If you want to follow along, you can copy the code from the above index.js and schema.graphql snippets into corresponding files inside a src directory in a Node project, add graphql-yoga as a dependency and then run node src/index.js. If you do so and then open your browser at http://localhost, you’ll see the following GraphQL Playground:
A GraphQL Playground is a GraphQL IDE that let’s you explore the capabilities of a GraphQL API in an interactive manner. Similar to Postman, but with many additional GraphQL-specific features. In there, you can now send the queries we saw above.
The query will be resolved by the GraphQL engine of the GraphQLServer. All it needs to do is invoking the resolvers for the fields in the query and thus calling out to the appropriate REST endpoints. This is the user(id: ID) query for example:
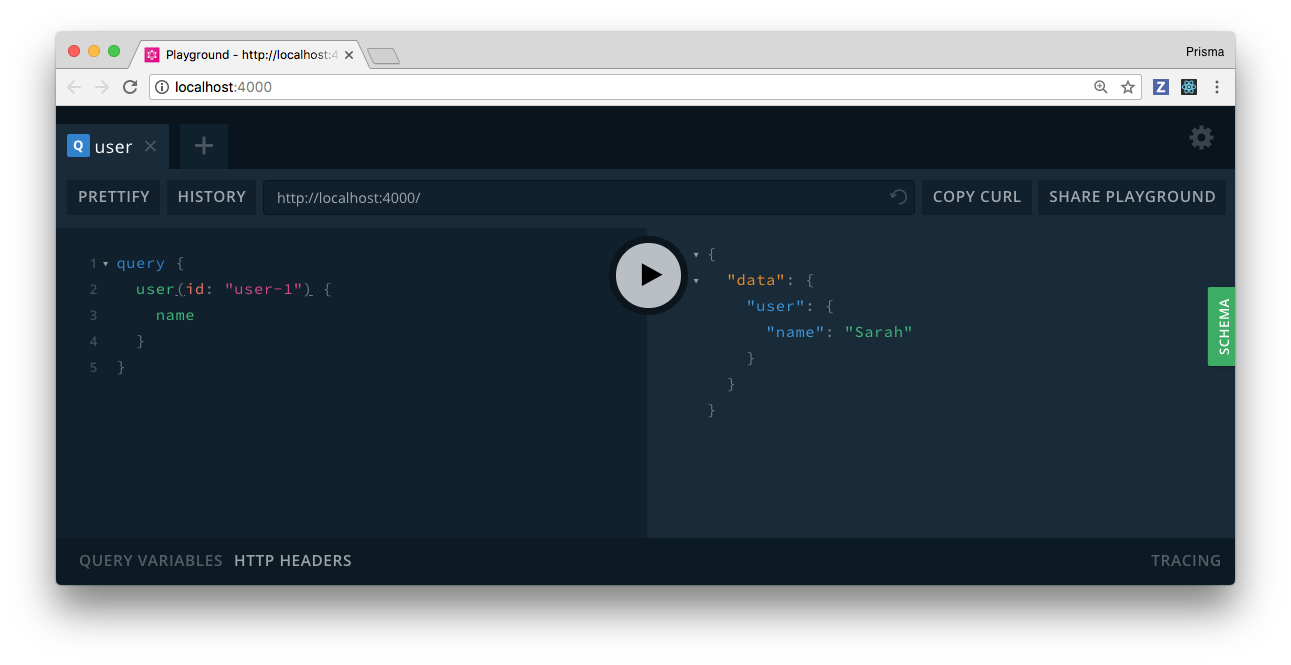
Awesome! You can now add fields of the User type to the query as you like.
However, when also asking for the related Post items of a user, you’ll be disappointed that you’re getting an error:
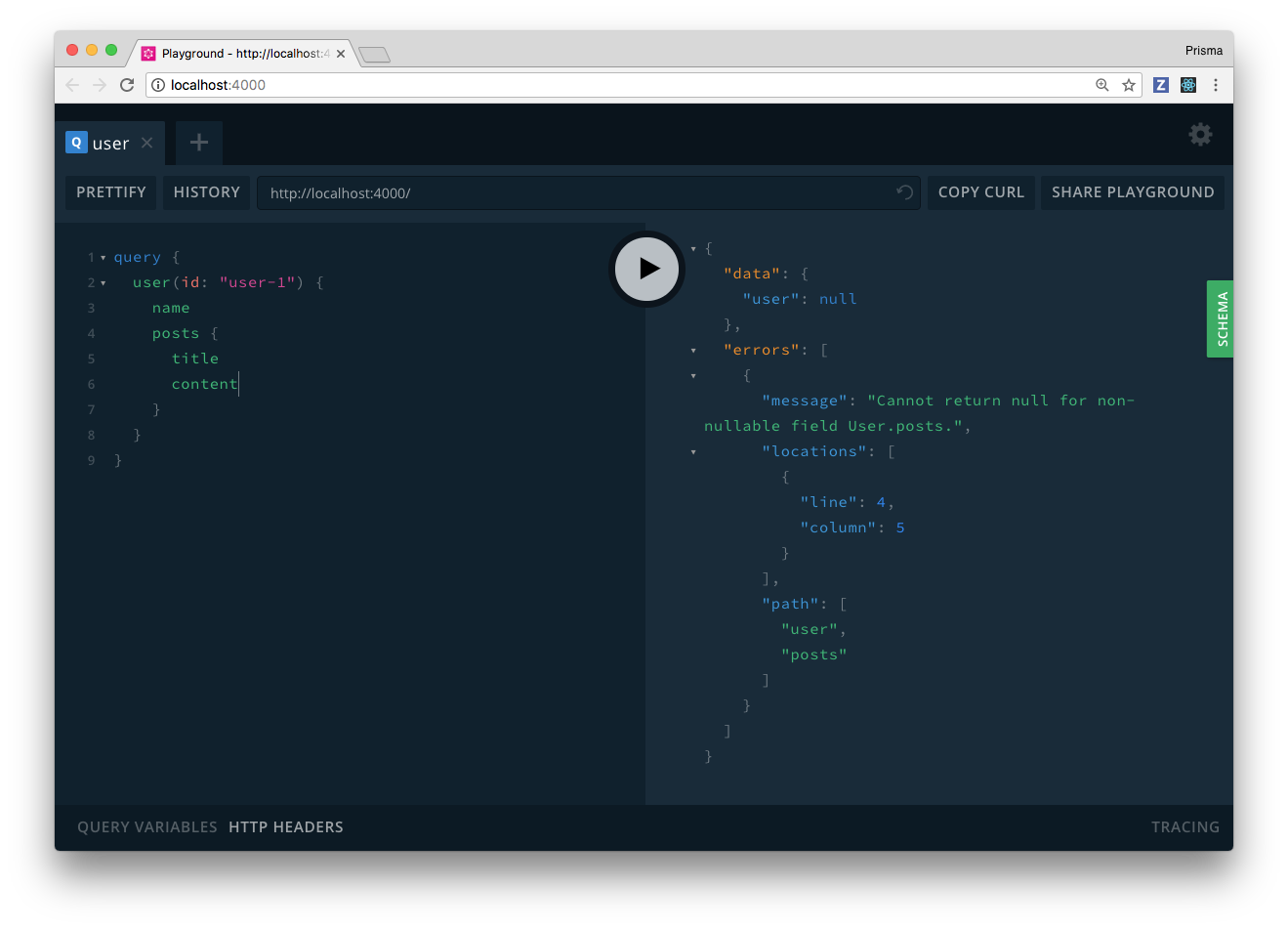
So, something doesn’t quite work yet! Let’s take a look at the resolver implementation for the user(id: ID) field again:
user: (parent, args) => {
const { id } = args
return fetch(`${baseURL}/users/${id}`).then(res => res.json())
},The resolver only returns the data it receives from the /users/<id> endpoint and because we’re using the flat version of the REST API, there are no associated Post elements! So, one way out of that problem would be to use the nested version — but that’s not what we want here!
A better solution is to implement a dedicated resolver for the User type (and in fact, for the Post type as well since we’ll have the same problem the other way around):
const resolvers = {
Query: {
// ... the resolver implementation from above ...
},
Post: {
author: parent => {
const { id } = parent
return fetch(`${baseURL}/blog/posts/${id}/user`).then(res => res.json())
},
},
User: {
posts: parent => {
const { id } = parent
return fetch(`${baseURL}/users/${id}/posts`).then(res => res.json())
},
},
}The implementation of the resolver is bug free and you can nest your queries as you wish. Pleasing!
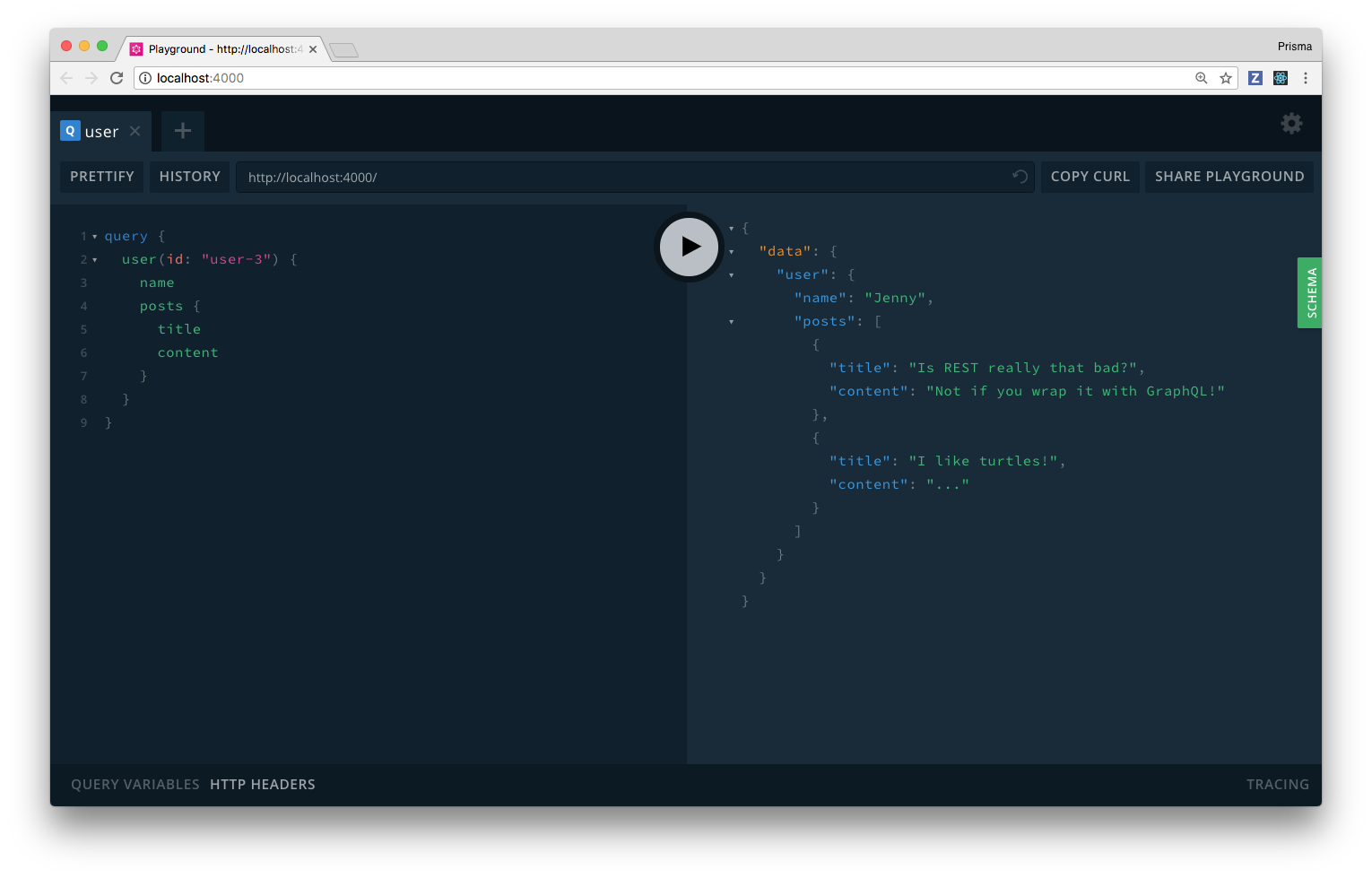
Explaining the underlying mechanics of why these additional resolvers fix the bug from before are beyond the scope of this article. If you’re curios, check out the following article: Demystifying the info Argument in GraphQL Resolvers
Great, this is it! You successfully learned how to wrap a REST API with GraphQL.
If you want to play around with this example, you can check out this repository which contains the full version of the GraphQL API we just implemented.
Advanced Topics
In this article, we really only scratched the surface of what’s possible with respect to wrapping REST APIs with GraphQL. Therefore, we briefly want to provide a few pointers regarding more advanced topics that are commonly dealt with in modern API development.
Authentication & Authorization
REST APIs usually have a clear pattern for authentication and authorization: Each API endpoint has certain requirements with respect to the clients that are allowed to access it. The incoming HTTP request usually carries an authentication token that authenticates and identifies a specific client. Depending on whether that client has the correct access rights for the endpoint it requested, the request will succeed or fail.
Now, when wrapping a REST API with GraphQL, the incoming HTTP request that’s carrying the GraphQL query needs to have a token as well. You would then simply attach the token to the corresponding header when calling out to the underlying REST API.
Performance
If you’ve paid attention throughout the article, you might have noticed that by wrapping the REST API with GraphQL, we only shifted the N+1-requests problem from the client- to the server-side: Initially, our client had to make N+1 requests with the *flat *REST API design; when the API was wrapped with GraphQL, the client could send a single GraphQL query to ask for the nested data — however, the GraphQL server still needs to make all the REST calls that were initially done by the client.
In general, this is already an improvement because that amount of requests will hurt a lot more if they’re sent from the client-side (e.g. on a shaky mobile connection). The machinery we have on the server is much more appropriate to perform that kind of heavy lifting! Additionally, if the REST API and the GraphQL server are deployed in the same datacenter or just the same region, there’s effectively no latency!
To improve performance further, you can introduce parallelization using the Data Loader pattern. When using that approach, resolver calls can be batched with dedicated batching functions which would allow to retrieve the required data in a more performant way.
Realtime
In modern applications, realtime updates are becoming a common requirement. GraphQL offers the concept of GraphQL subscriptions which allow clients to subscribe to specific events that are happening on the server-side. In the same way that GraphQL can represent the standard HTTP methods with queries and mutations, it’s also possible to wrap a realtime API (e.g. based on websockets) using GraphQL subscriptions. We’ll explore this in a future article — stay tuned!
What’s next?
In this article, you learned how to turn a REST API into a GraphQL API in three simple steps:
- Analyze the data model of the REST API
- Define your GraphQL schema
- Implement the resolvers for the schema
Wrapping REST APIs with GraphQL is probably one of the most exciting applications of GraphQL — and still in its infancy. The process explained in this article was entirely manual, the real interesting part is the idea of automating the different steps. Stay tuned for more content on that topic!
If you’d like to explore this area yourself, you can already check out the graphql-binding-openapi package which allows to automatically generate GraphQL APIs (in the form of a GraphQL binding) based on a Swagger / Open API specification.
The sample code code that was used in this article can be found in these repositories: rest-demo and graphql-rest-wrapper
Keep reading

How Prisma Compute Keeps Time Accurate in Long-Running Applications
How Prisma Compute keeps wall-clock time accurate in long-running Firecracker microVMs, using the host-paired KVM PTP clock instead of an in-guest NTP daemon.


Your agent can now provision Prisma Postgres through Stripe
Add a Prisma Postgres database to your Stripe project with one command: spending limits out of the box, plan changes from the CLI you already use.

Build your next app with Prisma
Start free. Scale when you’re ready.