Optimizing Postgres for Global Apps

Postgres uses a chatty, stateful protocol to connect clients to the database. While great for connecting over a local network, it was designed before the age of serverless deployments, multi-region applications, and modern network architectures. Let's talk about the challenges that occur when connecting to Postgres in 2025 and how to mitigate them.
Tyler Benfield is a Staff Engineer at Prisma and an expert in all things Postgres, from high-level architecture to low-level protocols. His knowledge and expertise helped make Prisma Postgres the most innovative serverless database on the market. In this article, he's sharing his experience of working on Prisma Postgres and his vision for its future.
Intro
The year is 1998. I was playing Pokémon Red on my Game Boy Pocket, snacking on Dunkaroos, and listening to ignoring NSYNC in the background from our kitchen radio. Meanwhile, unbeknownst to me, the Internet was rapidly transitioning from academia to household commodity. Following the Internet was a wave of tools, many evolving from research projects themselves, for building the Web that we rely so heavily on today. One of those tools was PostgreSQL, a next-generation database engine created at UC Berkeley. In 1998, the Postgres wire protocol was released, formalizing the specification for connecting to a Postgres database.
I'm writing this in 2025. The screen is split between Notion and my handy AI agent. Eating Dunkaroos would likely send me into sugar shock. I've seen the Web transition from marquee tags on Geocities to full-stack applications deployed around the world with a single command. AI is in the midst of making app development accessible to everyone, not just those with a software engineering background, while the demand for software has never been higher. Despite all this change, Postgres, the database from the 90's, is still one of the most popular databases and continues to expand.
Obviously I'm a sucker for the nostalgia, but this post is actually about using Postgres in the modern world of app development. While the Postgres protocol has evolved over the years, it's fundamentally suboptimal for the serverless, globally deployed apps that are popular today. Let's explore those drawbacks and how we can improve Postgres for 2025 and beyond.
Postgres Wire Protocol
I'm going to be writing a lot about the wire protocol, so maybe we start by talking about what that is.
What's a Wire Protocol?
A wire protocol is a specification for sending data as messages over a connection boundary. It outlines a common language for clients and servers and allows anyone to build a compatible tool.
What technologies use a wire protocol? Besides databases like Postgres, MySQL, and MongoDB, we have HTTP, WebSockets, gRPC, FTP, SMTP, SSH, TLS, MQTT, and many other acronyms. Wire protocols are at the heart of any communication between two systems.
In Postgres, the wire protocol is a byte-level binary specification that is typically transmitted over a TCP connection. This has enabled the community to build clients across every programming language and for every runtime environment that supports TCP connections (✨foreshadowing✨). In some cases, we've even seen new database engines adopt the Postgres wire protocol in order to be compatible with the ecosystem of Postgres clients. As a result, the Postgres wire protocol has become something of a standard on its own. Being so ingrained in the ecosystem also makes it incredibly difficult to adopt something new, despite attempts at improving the protocol for modern architectures.
Postgres Protocol Handshake
The Postgres wire protocol, formalized in 1998, set out to make Postgres accessible to clients across a variety of languages and runtimes. System architectures at that time often hosted Postgres and application servers on the same machine, or at least over a local network. There were no cloud providers or serverless runtimes to consider. As a result, the Postgres wire protocol is a chatty, stateful protocol with significant drawbacks for modern applications architectures.
Let's break down a typical Postgres connection. We'll use the modern protocol here rather than the original from 1998:
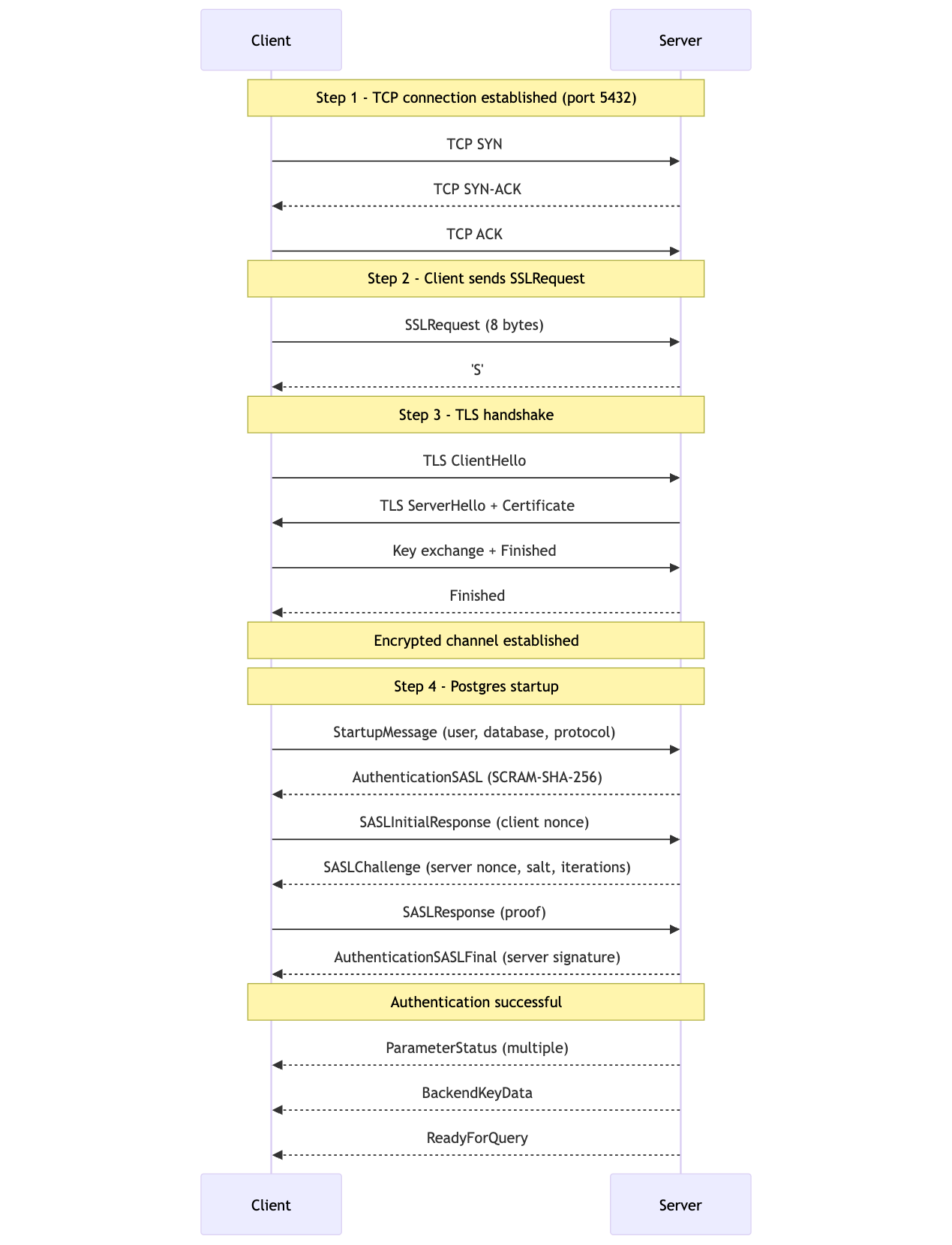
That's 18 messages across the network before the first query can be executed! Let's also look at how we prepare a query. There are two methods for this: simple query protocol and extended query protocol. Applications typically use the extended query protocol as it supports parameterized queries to prevent SQL injection, so we'll keep our focus there:
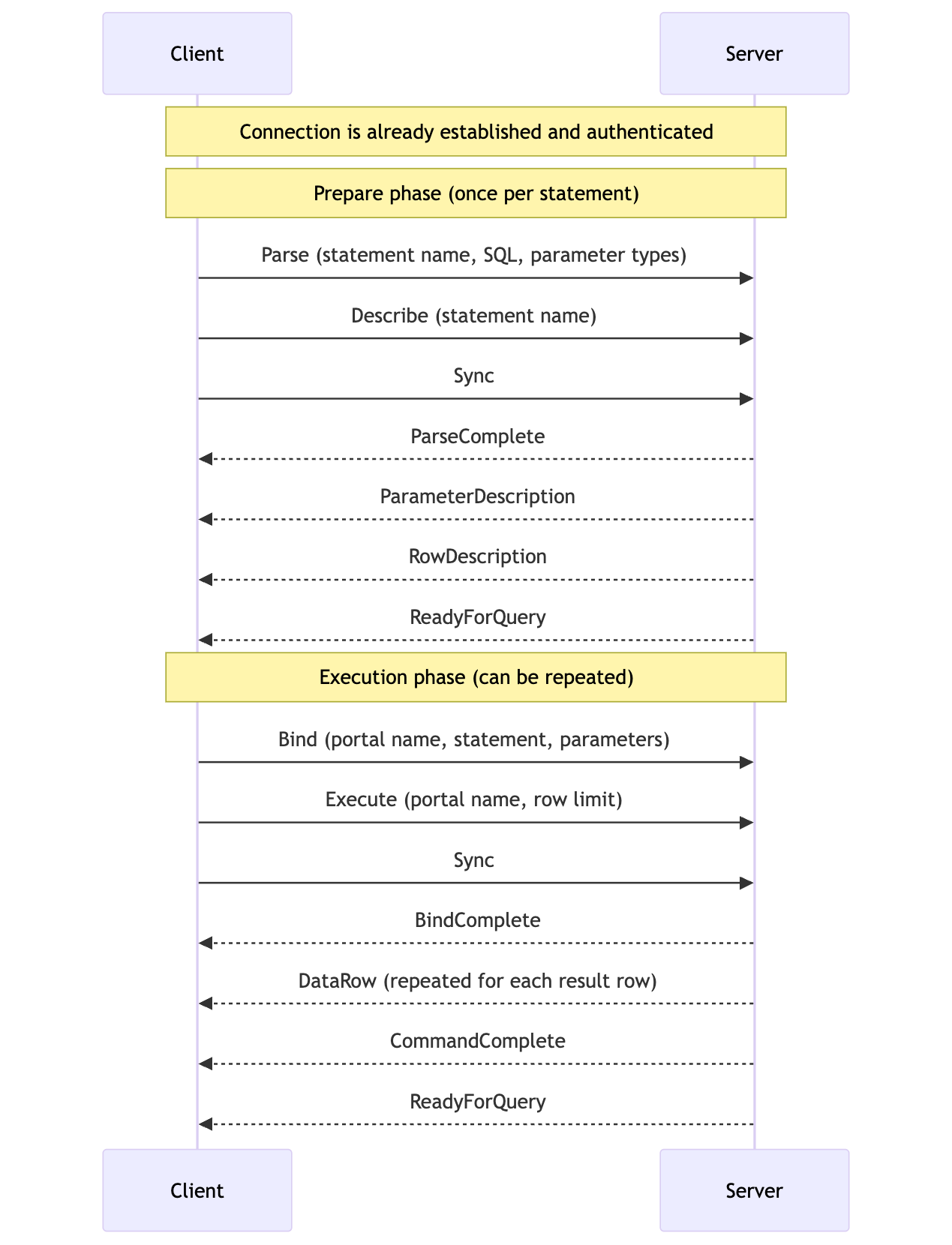
14 messages just to execute a query! For the wEll aCTuaLLy readers, not all of these messages are blocking. Multiple arrows in the same direction are sent without waiting for any response, so technically we have 4 I/O blocking sequences. The prepare phase is expected to be reused with different parameter values on the same connection, taking this to a harmless pair of 2 I/O sequences: one to the server and one back to the client forming a single round-trip. That's not so bad! Fortunately for this blog post, there's more to unpack…
The Postgres protocol was clearly designed for stateful servers that can maintain a long-running TCP connection. The type of server that was deployed in 1998. The overhead of establishing a connection and preparing queries is kept to a minimum when the connection can be reused thousands of times.
Modern apps are deploying to serverless runtimes like AWS Lambda, Cloudflare Workers, and Vercel, where these TCP connections are established and dropped with every request. That chatty handshake to establish a connection is killing your serverless app performance and there's nothing you can do about it.
My pessimism doesn't end there!
Speed of Light
Now that we've seen how chatty the Postgres wire protocol is, let's add global deployments into the mix.
Let's revisit the Postgres connection handshake from above. That was 18 messages to establish a connection. Some of those are bundled and treated optimistically, leaving us with around 5 round-trips that are necessary to complete the handshake.
Let's also say you have a user accessing your app in Tokyo with your Postgres database in Virginia (us-east-1). Since you're running on Cloudflare Workers, your user gets a low-latency connection to your app 🎉 Then you need to query your database 💀 The geographic distance compounds over the number of round-trips and leaves you with ~460ms to establish a connection. Pro tip: don't let your manager run a lighthouse score while traveling internationally.
Connection Pooling
So you've done your reading and discovered that connection pools will keep hot connections? Allow me to ruin your day.
Connection pooling does maintain hot connections, but your app still has to connect to the connection pool securely. How does that work? Postgres wire protocol. The sequence I outlined above for connecting to a Postgres server is the same sequence used to connect to a connection pooler like PgBouncer. A connection pool provides no material performance benefits for connection latency.
Connection pools are important for protecting your database from connection exhaustion, but that's not the topic of this post.
Globally Accessible Postgres
I wouldn't be writing all of this if I didn't have something cool to share.
At Prisma, we are building a Postgres database platform that is designed for modern app deployments. It's real Postgres, running on a unique bare metal architecture that enables incredible performance with simple, pay-per-query pricing. You can read more about Prisma Postgres in our docs. For the context of this post, I want to focus on how we make Postgres suitable for globally deployed serverless apps.
Abusing Optimizing the Postgres Protocol
In order to support connections from any Postgres client into Prisma Postgres, we cannot deviate from the Postgres wire protocol specification. As I outlined above, this introduces drawbacks that contradict with our mission of building the best Postgres platform for modern apps. So we got creative.
What if we moved the chatty parts of the protocol closer to the app without moving the database? What if we took advantage of the network backbone we have to more quickly connect to the database? What if I got to the freaking point already?
To make this possible, we operate a global network of Postgres-aware proxies across our entire bare metal cluster that powers Prisma Postgres. Every host on our network can receive an inbound Postgres connection from a client, maintaining low-latency round-trips between our proxy and your app. The optimal proxy is identified using latency-based DNS resolution, so you'll always connect to the fastest proxy even if it is not the closest geographically. As we expand into more regions, we will continue to expand our proxy network as well.
We then distribute the routing and authentication data to every datacenter where these hosts operate. This allows the proxy to terminate the Postgres connection handshake with the Postgres client. All that chattiness is now over a shorter geographic distance, resulting in much faster round-trips.
We will have to establish a connection from the proxy to the database, potentially across a geographically distant connection. With this connection now over our high-bandwidth network, we can seamlessly optimize the steps based on measurements from real-world workloads.
All in all, the connection looks something like this:

Now you might be realizing that is more messages than the original. You're right! Geographic distance and optimizations are important here. Client → Proxy is a close-proximity connection, while Proxy → Postgres is potentially a geographically distant connection. That geographic distance is still there, right? Right.
It's also important that our proxy servers are stateful. They are running on bare metal hardware with high-bandwidth connectivity. We can optimize reuse of upstream Postgres connections, similar to connection pooling, and make our own optimizations to the connection handshake since Prisma operates both sides of the connection. Between the Preview and GA releases of direct TCP connections to Prisma Postgres, you can expect the connection latency to be significantly reduced as a result of these optimizations.
Connection Pooling (coming soon for direct TCP connections)
Where does connection pooling fit into all of this? Soon, we'll be adding connection pooling to direct TCP connections. The Prisma Postgres connection pool will operate on the same bare metal machine as the database, offering zero latency connections between the connection pool and Postgres. This will enable a higher volume of inbound connections by reducing the load on the database caused by connection spikes or idle client connections.
As I mentioned above, connection pools still have to negotiate a connection with the client, nullifying any perceived connection latency improvements. Unless that handshake is moved closer to the client. That's where our proxy comes in again. The proxy will pool connections on its own and proactively create new connections based on client activity. The chatty connection handshake may be handled in the background, allowing the proxy to simply assign one of the connections it already has established to the upstream connection pool. Put another way, the proxy also acts as a distributed connection pool.
Extending Beyond the Protocol
So far I've talked about how Prisma Postgres improves the performance of Postgres connections from across the globe, but what about environments where TCP connections are not available? Add TCP to the browser you cowards!
I know. Connecting to the database from your frontend is bad. Why is it bad? Because someone told you it's bad? No, it's bad because it exposes raw database access to anyone using your app. I'm telling you that is bad. Browsers are used for more than your app frontend though. We're seeing a wave of browser-based tools for doing software development, including IDEs like GitHub Codespaces and AI agents like v0. Since the browser does not have a low-level TCP API, these tools are forced to connect you to your database through their backend.
To make Prisma Postgres more accessible to browser-based development tools (again, not your app frontend) we're planning to upgrade our proxy to also accept inbound WebSocket connections. WebSockets can relay binary data, just like TCP connections, allowing us to terminate a connection from a browser session, establish a TCP connection to Postgres, and relay binary messages across both channels. This will allow Postgres clients running in the browser (again, for development tools) to use a WebSocket as the underlying transport when connecting to your Prisma Postgres database. While TCP is still optimal for environments that support it, we believe that WebSocket capability expands into additional environments without compromising the capabilities of the Postgres protocol.
In the meantime, we've also released @prisma/ppg, a lightweight HTTP-based client for querying Prisma Postgres, into Early Access. The @prisma/ppg client is great for simple use cases where you only need to execute queries and don't need access to the more advanced capabilities of the Postgres wire protocol like streaming results, running cancelable queries, and leveraging the copy protocol.
Accelerating the Prisma ORM
Everything above applies to connections to Prisma Postgres using TCP. If you're using Prisma ORM, this is handled automatically along with other optimizations to network round-trips. In fact, the strategies we've learned from optimizing the connection between Prisma ORM and Prisma Postgres gave us a blueprint for the improvements to TCP that I discussed above.
When using Prisma ORM with Prisma Postgres, the Prisma Client in your app leverages a lightweight HTTP client rather than the full Postgres client. The Prisma operation that you send to Prisma Postgres is serialized in a JSON representation and sent through our Cloudflare-backed edge network until it reaches a query executor close to your Postgres database. That executor is able to turn the JSON into one or more SQL queries and execute them using its built-in connection pool. This reduces the geographic network calls to 1 per Prisma operation regardless of its complexity. This network-level optimization is how we can charge for Prisma operations rather than compute time.
How can we make this better? Make them even closer! We're migrating the query executor from an AWS EC2-backed architecture onto the same bare metal infrastructure that powers Prisma Postgres databases. Complex, heavily nested Prisma queries will be deconstructed into individual SQL queries on the same hardware that executes the query. This eliminates the network latency for executing queries, dramatically changing the performance profile.
For this reason, we still recommend connecting the Prisma ORM to Prisma Postgres using the existing method rather than TCP. We're doing everything we can to optimize TCP connections within the constraints of the Postgres protocol, but owning the full request lifecycle enables us to go even further.
Wrapping Up
I've seen so much conversation on the Web about moving apps to the edge, followed by conversations about moving back to be close to the data. The truth is, it depends. Your app will respond faster if it is closer to your users and database queries will be slower if your app is further from your database.
What you can do is to make as few round-trips to your database as possible and avoid sequential, waterfall queries. With Prisma Postgres, we can minimize the cost of those queries when they happen. Don't give up on the edge yet.
I hope this post helped you better understand Postgres connections. Find me on X, Bluesky, or the Prisma Discord if you have more questions about Postgres, Prisma Postgres, or Prisma ORM.
Keep reading

Prisma Next Is ~90% As Fast as Raw PG
Prisma Next performance benchmarks achieves ~90% of the raw pg driver's peak throughput, holds latency low under load, and ships as a 148.5 KB gzipped bundle for serverless and edge workloads.


Bloom Filters in Postgres: The Index Type Most Developers Overlook
One bloom index can replace a stack of B-trees on wide tables with many filter combinations. A tour of the concept, the Postgres extension, and a benchmark you can run yourself.

Build your next app with Prisma
Start free. Scale when you’re ready.