How Prisma and GraphQL fit together


There are many confusions around the relationship Prisma has with GraphQL. In this article, we clarify how developers should think about GraphQL and Prisma and provide a glimpse into Prisma's future.
TLDR: GraphQL is one of many use cases for Prisma
We love GraphQL and strongly believe in its bright future! We will keep investing into the GraphQL ecosystem and strive to make Prisma the best tool for building database-backed GraphQL servers. One example of our efforts is the upcoming Yoga2 framework which will enable a Ruby-on-Rails-like experience for GraphQL.
Prisma is an ORM replacement that has many more use cases beyond GraphQL, such as building REST or gRPC APIs. Prisma's goal is to simplify database workflows. Think of it as a suite of database tools to ease database access, migrations and data management.
History: From GraphQL to ORMs & databases
Let's start with a short history lesson and revisit how Prisma evolved to what it is today.

1) Graphcool: Making GraphQL easy for frontend developers
Before the launch of Prisma and the official rebranding, our core product used to be Graphcool (an open-source GraphQL BaaS). From the very beginning, the goal of Graphcool was to make it as easy as possible for developers to use GraphQL.
The architecture was simple since Graphcool represented the entire backend stack. It included the database, application layer and GraphQL API:

After running Graphcool in production for two years, we've noticed the following recurring customer feedback and requests:
- Graphcool was loved for its ease-of-use. Developers used it for prototyping but then often dropped it in production in favor of building their own GraphQL servers.
- Developers wanted more control and flexibility in their backend stack, for example:
- Decoupling the database from the API layer
- Defining their own domain-driven GraphQL schemas (instead of generic CRUD)
- Flexibility in choosing programming languages, frameworks, testing & CI/CD tools
2) Prisma bindings: Build a GraphQL server with any database
It was clear that the requirements developers have for building sophisticated GraphQL backends weren't met by a tool like Graphcool. This realization led us to Prisma. The first version of Prisma was a standalone version of Graphcool's query engine component.
By making Prisma available as a standalone component, we gave developers the opportunity to quickly generate a CRUD GraphQL API for their database. This API was not to be consumed from the frontend. Instead, the idea was to build an additional application layer on top of it to add business logic and customize the client-facing API.
This application layer was implemented using Prisma bindings. The mental model required developers to understand that they were dealing with two GraphQL APIs (a custom client-facing API on top of a generated CRUD API):

While the primary goal of Prisma still was to make it as easy as possible for developers to use GraphQL, the focus had shifted to becoming a data access layer that connects your GraphQL resolvers with a database.
3) Prisma client: Replacing traditional ORMs
After talking to lots of customers and the Prisma community, our understanding of what Prisma was (and could eventually become) had again evolved quite a bit.
The prior approach of building GraphQL servers with Prisma bindings had a few issues:
- While Prisma bindings made it easy to get started, the complexity of the concepts developers needed to understand in more advanced use cases went through the roof (due to the intricacies of schema delegation and the
infoobject). - Very difficult and impractical to achieve fully type-safe resolvers.
- Limited to the JavaScript ecosystem.
- Limited to GraphQL as a use case.
The Prisma client solves these issues. It is an auto-generated database client with a simple and fully type-safe data access API.
With this new approach, the generated CRUD GraphQL API is not part of the core Prisma development workflows any more. It rather becomes an implementation detail:

Note that very soon there will be a version of Prisma that can be used right inside your application server, omitting the need for the extra Prisma server:

While we believe that the Prisma client API today already is one of the best data access APIs out there, a lot of community feedback helped us improving it even further. The result is an extremely powerful and intuitive database API that we'll release soon.
Because the Prisma client has a built-in dataloader, it's the perfect tool to implement the resolvers in a GraphQL server.
How to think about Prisma's generated GraphQL API
Understanding that the generated Prisma GraphQL CRUD API is considered an implementation detail is crucial to comprehend Prisma's focus and future direction.
From a declarative datamodel to generated GraphQL CRUD
The core idea of Prisma was always the same:
- Developers define their datamodel in GraphQL SDL and map it to their database
- Prisma generates a powerful CRUD GraphQL API based on the datamodel
- The generated CRUD GraphQL API is used as foundation for the application layer and the client-facing API (except with Graphcool)
While the generated CRUD GraphQL API was absoutely essential with Prisma bindings, it has become an implementation detail with the Prisma client.
This is also reflected in the latest redesign of the Prisma website, where the Prisma client has replaced GraphQL as the dominant theme:
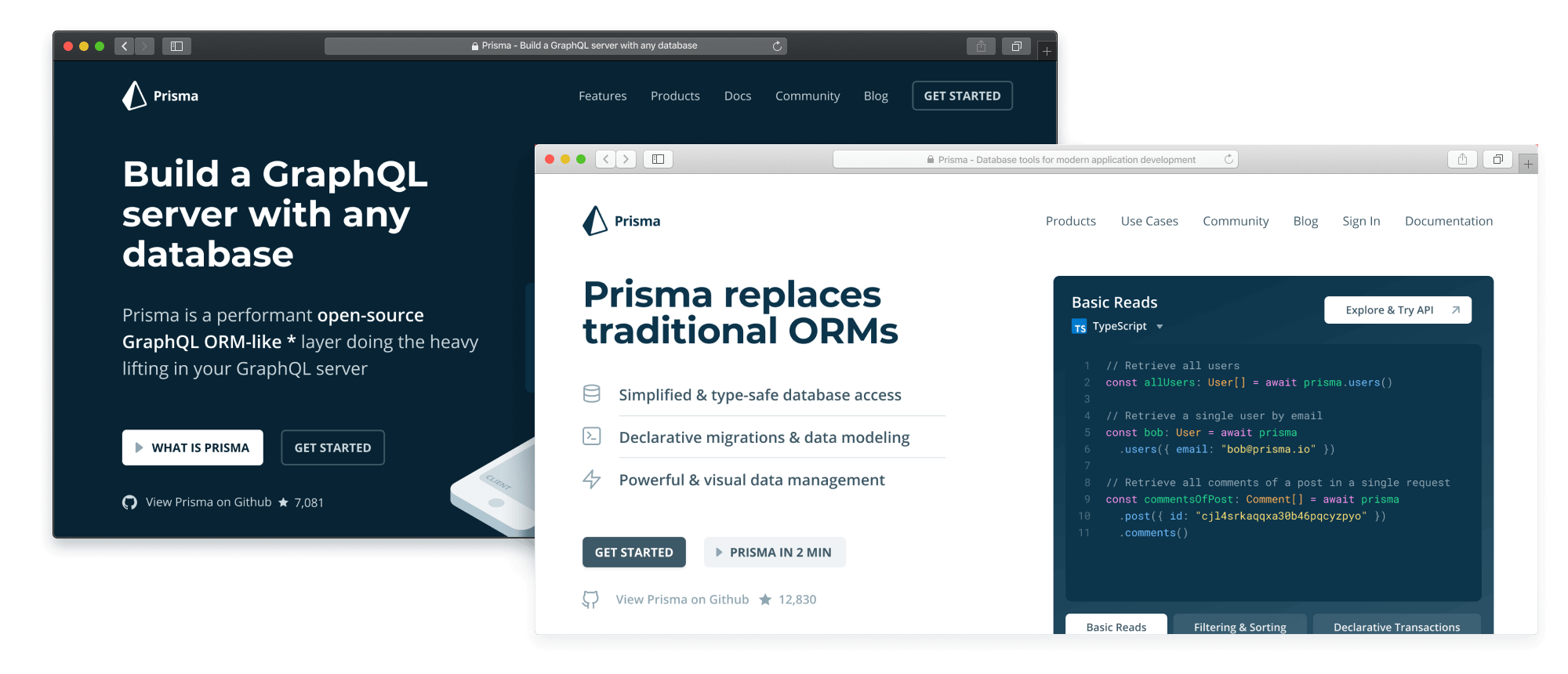
De-emphasizing Prisma's CRUD GraphQL API
Today, developers shouldn't care about how the Prisma client talks to the underlying database. What developers should care about is the Prisma client API!
To reflect this in our official documentation, we have removed the Prisma GraphQL API docs in the last Prisma release. If you still need the documentation, you can access it by navigating to older Prisma versions in the docs.
We also just introduced Prisma Admin as an additional tool to interact with the data in your Prisma project (in addition to the GraphQL Playground).
Data modelling in GraphQL SDL
Another common source of confusion in regards to Prisma and GraphQL can be data modelling. When using Prisma, the datamodel is specified using a subset of GraphQL's schema definition language (SDL).
While we've already adjusted the file type of the datamodel from .graphql to .prisma, using SDL for data modelling is still a strong tie to GraphQL. However, we are currently working on our own model language (which will be a modified version of SDL).
Comparing Prisma to AWS AppSync & Hasura
With the new understanding of the role of Prisma's CRUD GraphQL API, it becomes clear that Prisma is not in the category of "GraphQL-as-a-Service" anymore.
Tools like AWS AppSync and Hasura provision a generated GraphQL API for your database (or in the case of AppSync also other data sources). In contrast, Prisma enables simplified and type-safe database access in various languages.
GraphQL is an important use case for Prisma
Since the Prisma client was released, it's considered an implementation detail that Prisma uses GraphQL under the hood. So what role does GraphQL then play for Prisma?
We love GraphQL
The answer is clear to us: We still see GraphQL as one of the most important upcoming API technologies and want to make it as easy as possible for developers to build GraphQL servers. GraphQL remains to be an important Prisma use case for Prisma!
Investing into the GraphQL ecosystem
We will keep investing in the open-source GraphQL ecosystem. Many of the tools we've built have become the default in many GraphQL development workflows, such as the GraphQL Playground, graphql-yoga and GraphQL Nexus (built by Tim Griesser).
The recently announced nexus-prisma makes it incredibly easy to implement a GraphQL server on top of Prisma. With the upcoming Yoga2 framework, we further aim to create a Ruby-on-Rails developer experience for GraphQL.
Contributing to the GraphQL community
Similar to how we invest into the GraphQL ecosystem, we want to contribute to the GraphQL community. We're running the world's largest GraphQL community conference and maintain popular resources like How to GraphQL and GraphQL Weekly.
While we weren't among the first companies to join, we're certainly also planning to become part of the GraphQL Foundation and help steer the future direction of it.
🔮 A glimpse into the future
As highlighted throughout this post, we are working on many exciting and fundamental improvements to Prisma. To get an overview of what we are working on, feel free to check out our roadmap.
We are speccing all upcoming features in public (via GitHub issues and an RFC process), so please join the discussion on GitHub and share your opinions with us!
If you have any questions or comments, please share them on Spectrum.
We are hiring! As you will find, one item on the roadmap is a full rewrite of the Prisma core in Rust. If you are a Rust engineer or just generally interested in highly technical challenges and open-source development, definitely check out our jobs page.