Relay vs Apollo - Comparing GraphQL clients for React apps

Relay and Apollo are the most popular and sophisticated GraphQL clients available at the moment. But how do you know which one to choose?
An un-opinionated comparison of GraphQL clients for React apps
Relay and Apollo are the most popular and sophisticated GraphQL clients available at the moment. But how do you know which one to choose?
In this article, we’ll cover the following:
- Why a GraphQL Client?
- Overview
- Server Requirements
- React Integration
- Queries
- Mutations
- Subscriptions
- Conclusion
Note: This article only applies to Relay Classic, we’ll update it for Relay Modern soon. Stay tuned!
In this article, we are going to shed some light on the commonalities and differences between Relay and Apollo and want to help you in making an informed decision on which GraphQL client is the best for your next project!
This article assumes some familiarity with basic GraphQL concepts such as queries, mutations or fragments. If you’re just getting started with GraphQL, the How to GraphQL fullstack tutorial website is a great entry point!
At Prisma, we have been using Relay and Apollo extensively over the last years and now want to share our learnings with the community. Also note that while Apollo can also be used with other frameworks, this article primarily targets React developers and specifically compares Relay and Apollo in the context of React applications.
Why a GraphQL client?
GraphQL backends commonly expose their API over HTTP where queries and mutations can be sent in the body of a POST request. When building a JavaScript app, this means that you can get quite far by using fetch or request and thus interact with the GraphQL API directly.
However, there are a number of recurring challenges and use cases in working with a GraphQL backend that are agnostic to the app that’s being built and that would have to be reimplemented with every new project. A few examples are:
- caching data that is returned by the server
- UI framework integration (React, Angular, Vue, …)
- keeping the local cache consistent after a mutation
- managing up websockets for GraphQL subscriptions enabling realtime updates
- pagination for collections
A GraphQL client should come with that kind of functionality so that you don’t have to reimplement these behaviours yourself. Instead, you can completely focus on your application domain and on implementing the specific requirements of your app.
Overview
In the following, we are going to explore how to solve common and recurring client-side tasks when working with a GraphQL API, both from a Relay and an Apollo perspective.
Relay vs Apollo
To give you a broad overview of both clients, here is a high-level comparison before we dive into more details.
| Relay | Apollo | |
|---|---|---|
| Frameworks | React, React Native | Framework agnostic |
| GraphQL API | Requires custom schema | Works with any schema |
| Flexibility | Fixed structure | Very flexible |
| Productivity | Great DX but high entry barrier | More manual work |
| Difficulty | New concepts & high entry barrier | Easy to get started |
| Subscriptions | No subscriptions support yet | Yes: subscriptions-transport-ws |
| Schema scheck | Build-time via Babel (required) | Optional tools |
When reading about Relay and Apollo, you’ll notice that one major difference lies in the flexibility of the two approaches. While Relay is very opiniated and doesn’t give you a lot of freedom in how you want to structure your application, Apollo has a variety of options that range from lightweight integrations to much more sophisticated approaches.
In short, Relay lends itself well for large-scale applications that have complex data requirements and many dependencies between different parts of the application where maintaining these dependencies by hand would be very tedious and error-prone. Apollo on the other hand provides a much more lightweight and flexible approach that works in any environment. Many tasks such as keeping the local cache consistent can also be achieved with the Apollo Client but require more manual work and bookkeeping.
An example to follow along
In the following, we are going to compare Apollo and Relay by practical examples and show how each of them can be used to deal with a certain use case. We are going to use the data model for the Pokedex application that is being used on Learn Relay and Learn Apollo.
This is what the data model looks like:
type Pokemon {
id: ID!
name: String
trainer: Trainer @relation(name: "OwnedPokemons")
url: String
}
type Trainer {
id: ID!
name: String
ownedPokemons: [Pokemon!]! @relation(name: "OwnedPokemons")
}Server Requirements
In contrast to Apollo Client that works with any GraphQL schema, Relay actually has a few requirements when it comes to the structure of the GraphQL schema that’s implemented on the server.
With Relay, the GraphQL server is expected to expose the following capabilities:
- The ability to query one particular resource (node) by its ID. This is done with a root query field in the GraphQL schema called node that takes an ID as an argument: node(id: ID!). In Relay, every object is expected to have a unique ID which is why every type needs to implement the Node interface:
interface Node {
id: ID!
}The reason for this is that Relay can efficiently fetch a node by its ID after it was mutated and generally brings further performance benefits when working with the data graph.
- The ability to query the data graph using a root field called
viewerthat contains all other fields as children. Thevieweris the root field that all other nodes are somehow connected to. While the availability of this field is not actually a hard requirement for Relay to work, it's conventional and you'll find it in almost all GraphQL APIs that work with Relay. You can read more about the rationale of theviewerfield here. - Mutation arguments must be wrapped in input type object. Relay requires that every mutation receives its input arguments in the form of one single object. So, for a
createPokemonmutation that expects anameand aurl, this information needs to be provided as one object wrapping these two values. - Requirements for mutation payloads. Relay has strong conventions for how mutations work and how updates to the local Relay store are performed. This requires that certain fields need to be included in the payload of a mutation — which fields exactly have to be included depends on the mutation kind.
- Using connections for modelling relationships. In Relay, the concept that is used to model a relationship between two types is called Connection. It requires that a relation in the data model is expressed using edges that each contain a node. If you wanted to access the first 100 Pokemons in the database, this would look as follows with Relay:
{
viewer {
allPokemons(first: 100) {
edges {
node {
id
name
}
}
}
}
}In this case, the viewer has a connection to the allPokemons field. Also notice that a connection requires an indication of how many objects should be fetched, here this is done using the first parameter but more options such as last, after or beforeare available as well. This allows for easy slicing of the list and implement pagination easily. This article gives a lot of insights on the rationale behind the connection model and how it enhances pagination.
React Integration
While Apollo can be used in any client-side environment (such as React, Angular, Vue or plain JS as well as on iOS and Android), Relay is restricted to be used with React or React Native.
However, they actually both follow a similar approach when being used in a React application: With both clients, the general idea is that React components are wrapped using a higher-order component which takes care of fetching the data and making it available to the component through its props. Data requirements for a component are specified in a declarative manner and all actual networking logic is completely abstracted away and hidden from the developer. A major benefit of this approach is that the container can manage data fetching and resolution logic without interfering with the state of the inner component.
Queries
A major responsibility of any GraphQL client is the ability to fetch data and make it available to the view layer of the app. In Relay, the major way of getting access to data inside of a React component is by means of a higher-order component called Relay.Container.
With Apollo, it is possible to use a similar approach with the graphql higher-order component. Another way to obtain data from the server would be to directly send queries using the ApolloClient class and process the returned data with a promise. In the following, we are going to dive into what data fetching with Relay and with Apollo looks like.
In the next two sections, we are going to analyze the following query and how it would be incorporated using each Relay and Apollo:
query {
allPokemons(filter: { trainer: { name: "Ash Ketchum" } }) {
id
name
url
}
}Data fetching with Relay
Co-located queries
Relay heavily relies on GraphQL fragments to express data requirements for the React components. In fact, when working with Relay, we’re not actually writing full-blown GraphQL queries but only specify the data that is needed for each component in terms of a fragment. Relay then takes care of composing the fragments and building the actual GraphQL queries that are getting sent to the server. It hides all the details in this process so that the developer never has to deal with the nitty-gritty of network connections and HTTP requests.
As mentioned above, React components that need data from the server must be wrapped with a Relay.Container. This higher-order component does not directly take care of fetching the data but rather provides the wrapped component with the ability to define its data requirements and then guarantees that this data is available before the component is rendered.
Let’s take a look at some example code that creates and exports a Relay.Container which wants to display all Pokemons of the trainer called "Ash Ketchum" in a Pokedex component.
The Pokedex component renders a list of PokemonPreview components where each PokemonPreview presents information for one particular Pokemon.
// wrap Pokedex class with a RelayContainer and inject the data requirements via fragments
export default Relay.createContainer(
// the wrapped component
Pokedex,
{
// specify data requirements in terms of a fragment
fragments: {
viewer: () => Relay.QL`
fragment on Viewer {
allPokemons (
filter: {
trainer: {
name: "Ash Ketchum"
}
},
first: 1000
) {
edges {
node {
id
# include fields that appear in the `pokemon` fragment in `PokemonPreview`
${PokemonPreview.getFragment('pokemon')}
}
}
}
id
}
`,
},
},
)In the wrapped React component, we have to specify props according to the defined fragments on the Relay container. In this case, we need to specify viewer that includes the allPokemons object.
// the Pokedex class is responsible to display multiple pokemons
class Pokedex extends React.Component {
// require the viewer prop type
static propTypes = {
viewer: React.PropTypes.shape({
allPokemons: React.PropTypes.object,
}),
}
render () {
return (
<div>
<div>
// iterate the edges and nodes in the allPokemons connection
{this.props.viewer.allPokemons.edges.map((edge) => edge.node).map((pokemon) =>
<PokemonPreview key={pokemon.id} pokemon={pokemon} />)
}
</div>
</div>
)
}
}It’s important to note however that this approach still requires the viewer prop to be passed in to the Pokedex component through the component hierarchy - the mere fact that we have declared the viewer as a data requirement in a fragment does not yet guarantee its availability! It only serves to express what parts of the viewer are needed in that particular component.
When working with React and Relay, there are two separate trees being managed by these frameworks: The component tree that is managed by React and that will eventually represent the UI of the application as well as the fragment tree managed by Relay where the individual GraphQL fragments will be composed to queries that are sent over to the server.
Relay is heavily based on conventions. A major advantage of this approach is that following these conventions will enforce a very clean architecture and reduce subtle bugs that appear when changing certain parts of a system that had interdependencies with other parts.
Relay also optimizes for performance and tries to minimize the data transfer by only ever fetching data that is not yet available on the client. Facebook created GraphQL and Relay in the context of trying to improve the user experience of their applications in regions with very low connectivity, sending as little data as possible over the wire was one of the primary goals and still is a major part of the whole framework.
Data normalization with nodes
Relay requires the unique id field on every node in the GraphQL backend. This id is heavily used by Relay to normalize the data and make sure that all components rerender when there is new data for a certain node. No more configuration is needed to make the cache consistent from the client side - however, there is also no possibility to change this behaviour.
For example, for a GraphQL backend that only has unique IDs per type, Relay’s cache mechanisms would break. Graphcool uses cuids to generate unique IDs across all nodes in your project, so this is not an issue.
To read more about GraphQL queries in Relay, refer to the section in Learn Relay.
Data fetching with Apollo
With Apollo, it is possible to fetch data in two different ways:
- Wrapping the React component with the
graphqlhigher-order component and make the data available through the props - Send a query directly using the
ApolloClientclass and handle the return data in a promise
1. Using graphql to wrap a React component
When a React component requires some data, it can be wrapped with a query that expresses these data requirements and then the result of that will be available through the component’s props. Apollo further injects a loading and error property into the wrapped component. This allows the component to render in situations where the data has not yet arrived in the client (where loading will be true) or where the network request failed (so error will contain some info about what went wrong).
Taking the same scenario as above where the Pokedex component displays all Pokemons owned by the trainer called "Ash Ketchum", the code to wrap the Pokedex component looks as follows:
const allPokemonsQuery = gql`
query {
allPokemons(filter: { trainer: { name: "Ash Ketchum" } }) {
id
name
url
}
}
`
export default graphql(allPokemonsQuery)(Pokedex)The response for the query as well as the loading and error properties are all part of an object called data in the props of the wrapped component. Note that it is possible to rename this object, but it's called data by default.
Consequently, in our scenario the implementation of the Pokedex component could be done like so:
// the Pokedex class is responsible to display multiple pokemons
class Pokedex extends React.Component {
// require the data prop type
static propTypes = {
data: React.PropTypes.shape({
loading: React.PropTypes.bool,
error: React.PropTypes.object,
allPokemons: React.PropTypes.array,
}).isRequired,
}
render() {
// data.loading informs about loading state - we can easily render a loading animation or a text
if (this.props.data.loading) {
return <div>Loading</div>
}
// in the case of an error with the query, data.error contains more information
if (this.props.data.error) {
console.log(this.props.data.error)
return <div>An unexpected error occurred</div>
}
return (
<div className="w-100 bg-light-gray min-vh-100">
<div className="flex flex-wrap justify-center center w-75">
{this.props.data.allPokemons.map(pokemon => (
<PokemonPreview key={pokemon.id} pokemon={pokemon} />
))}
</div>
</div>
)
}
}2. Directly send queries using ApolloClient
The second option is to send a query using ApolloClient and processing the result as a promise. In that case, the query method of the ApolloClient class can be used:
client
.query({
query: gql`
{
allPokemons(filter: { trainer: { name: "Ash Ketchum" } }) {
id
name
url
}
}
`,
})
.then(result => console.log(result))This approach leads to more flexibility if you require certain data for something other than displaying it in the UI.
Controlling the Apollo Store
Apollo uses a normalized store for its local cache. That means that the data that is being returned by the server (potentially) has a nested shape and will be flattened before being put into the store. All objects will be stored on the first level of the cache uniquely identified by their ID.
Let’s consider the following example query:
query {
Trainer(name: "Ash Ketchum") {
id
name
ownedPokemons {
id
name
}
}
}And assume it returns the following JSON data:
{
"data": {
"Trainer": {
"id": "ciwj0dw5dm6aj01632pto44t0",
"name": "Nikolas",
"ownedPokemons": [
{
"id": "ciwj0dw6zpeuj0148xvsgc3hr",
"name": "Mewtwo"
},
{
"id": "ciwj0dw8gm6c80163wh8zku78",
"name": "Pikachu"
}
]
}
}
}Apollo would now flatten the nested Pokemons and put them on the first level of the store, so the contents of the store would look somewhat similar to this:
{
"ciwj0dw5dm6aj01632pto44t0": {
"id": "ciwj0dw5dm6aj01632pto44t0",
"name": "Nikolas",
"ownedPokemons": [ciwj0dw6zpeuj0148xvsgc3hr, ciwj0dw8gm6c80163wh8zku78]
},
"ciwj0dw6zpeuj0148xvsgc3hr": {
"id": "ciwj0dw6zpeuj0148xvsgc3hr",
"name": "Mewtwo"
},
"ciwj0dw8gm6c80163wh8zku78": {
"id": "ciwj0dw8gm6c80163wh8zku78",
"name": "Pikachu"
}
}In order for this approach to work, the Apollo store needs to be able to uniquely identify an object. It therefore provides the dataIdFromObject function that can be provided upon initialization of the ApolloClient. In this method, we can specify how an object can be uniquely identified. With Graphcool, this is done using the id property, so the implementation would look as follows:
const client = new ApolloClient({
networkInterface: createNetworkInterface({ uri: 'https://api.graph.cool/simple/v1/__PROJECT_ID__' }),
dataIdFromObject: o => o.id,
})With another GraphQL backend, your IDs might only be unique per type. In this case, you can use the following setup:
const client = new ApolloClient({
networkInterface: createNetworkInterface({ uri: 'https://api.graph.cool/simple/v1/__PROJECT_ID__' }),
dataIdFromObject: o => o.__typename + ' ' + o.id,
})In both cases, you have to make sure to include the id in all queries and mutations whose results should be normalized. To read more about GraphQL queries in Apollo Client, refer to the Learn Apollo. There's also an excursion on the Apollo Store.
Mutations
Sending mutations is a core feature of any GraphQL client allowing you to create, modify or delete data in a GraphQL backend.
While calling mutations in both Relay and Apollo is done with mutation strings where GraphQL variables are injected, the two clients handle cache consistency in combination with mutations in completely different manners. Mutations in Relay are extremely powerful and guarantee that the local store is always in a consistent state with the server. With Apollo on the other hand, achieving cache consistency requires a bit more manual work and potentially allows the developers to make mistakes which can lead to inconsistencies on the client-side.
We now want to explore how we can send the following GraphQL mutation with Relay and Apollo:
mutation {
createPokemon(
name: "Zapdos"
types: [FLYING, ELECTRIC]
url: "http://assets.pokemon.com/assets/cms2/img/pokedex/full/145.png"
) {
id
name
}
}Mutations with Relay
Mutations in Relay are very verbose and complex, this complexity however provides a lot of power and saves large amounts of work from the developer. When creating a mutation, we need to provide specific information that Relay uses behind the scenes to make sure all places in our app where the mutated data is used are getting updated properly.
It’s also important to note that the only way in Relay to change the state in the local store is by means of a mutation, there is no way to manually influence how the data in the store should be updated. After a mutation is sent, it is possible for the developer to specify what an opmistic UI update should look like, however, any changes that actually end up in the local store have to be confirmed by the server! If the interaction with the server fails, the optimistic UI updates are rolled back.
Generally, a mutation needs to be defined as a subclass of the Relay.Mutation class. After an instance of that class was created, there are two methods on the Relay object that can be used to actually send that mutation to the server:
commitUpdate(mutation)send the mutation right awayapplyUpdate(mutation)returns a transaction that can be sent later on by simply callingcommit()on it
When subclassing Relay.Mutation, the following methods must be implemented:
getMutation(): Specify the name of the mutation (from the GraphQL schema).getFatQuery(): Specify all nodes, edges and connections in our data graph that may change after this mutation.getConfigs(): Tell Relay what exactly happens with this mutation. The configurationRANGE_ADDneeds aparentName, aparentID(that's what we need theviewerin the fragments for!), aconnectionNameand anedgeName. Additionally we need a list ofrangeBehaviors, but typically'': 'append'is enough. The Relay documentation have listed the arguments that are required for each configuration.getVariables(): Specify the variables needed for this mutation.getOptimisticResponse()(optional): Specify optimistic data for the query response. It's only possible to return data specified in the fat query andviewer.
We also need to provide the static property fragments:
fragments: Specify the data needed by this mutation that is already a part of our data graph, this is similar to specifying data requirements in aRelay.Container. In our case, we need theviewerID so that we're able to append a pokemon node to theallPokemonsconnection (seegetConfigs).
This is what our mutation subclass would look like:
import Relay from 'react-relay'
export default class CreatePokemonMutation extends Relay.Mutation {
// Specifies required data for this mutation.
// Needs to be supplied together with `getVariables` defined below when calling this mutation.
static fragments = {
viewer: () => Relay.QL`
fragment on Viewer {
id
}
`,
}
// Specifies name of the mutation from the GraphQL schema.
getMutation () {
return Relay.QL`mutation{createPokemon}`
}
// Specifies what data may have changed due to this mutation.
getFatQuery () {
return Relay.QL`
fragment on CreatePokemonPayload {
pokemon
edge
viewer {
allPokemons
}
}
`
}
// Uses RANGE_ADD type to add `pokemon` node to `allPokemons` edge
getConfigs () {
return [{
type: 'RANGE_ADD',
parentName: 'viewer',
parentID: this.props.viewer.id,
connectionName: 'allPokemons',
edgeName: 'edge',
rangeBehaviors: {
'': 'append',
},
}]
}
// Required variables for this mutation.
// Needs to be supplied together with objects defined in `fragments` above when calling this mutation
getVariables () {
return {
name: this.props.name,
url: this.props.url,
}
}
// Defines an optimistic response to instantly update the UI. This will be overwritten if the mutation fails.
getOptimisticResponse () {
return {
edge: {
node: {
name: this.props.name,
url: this.props.url,
},
},
viewer: {
id: this.props.viewer.id,
},
}
}
}In this mutation, we describe what Relay needs to know about the createPokemonMutation to first execute the mutation and then update the client side store to keep its data consistent.
We can then actually send the mutation to the server using the commitUpdate() method that was mentioned above:
Relay.Store.commitUpdate(
new CreatePokemonMutation({ name: this.state.name, url: this.state.url, viewer: this.props.viewer }),
{
onSuccess: response => console.log('created pokemon', response),
onFailure: transaction => console.log('error', transaction),
},
)To find out more, you can read about other mutation configurations and optimistic responses or read the official mutation documentation.
Mutations with Apollo
Calling mutations with the Apollo Client follows the same approach as sending queries. We again have two options:
- Wrapping the React component that should send the mutation with the
graphqlhigher-order component - Send a mutation directly using
ApolloClientand handle the return data in a promise
In contrast to Relay however, Apollo doesn’t take care of cache consistency with every mutation that is sent, so we have to manually specify how Apollo should update the cache after the mutation has been performed.
1. Wrapping the component with graphql
First, we define a mutation with variables using the gql syntax and wrap a React component with graphql to later call the mutation:
const createPokemonMutation = gql`
mutation createPokemon($name: String!, $url: String!) {
createPokemon(name: $name, url: $url) {
id
name
url
}
}
`
const AddPokemonComponentWithMutation = graphql(createPokemonMutation)(AddPokemonComponent)
export default AddPokemonComponentWithMutationWhen we used the same approach for fetching data, the query was sent behind the scenes and the returned data was made available to our component as a data object in its props. This time, since we're dealing with a mutation where we want keep control as to when that mutation is fired, Apollo actually injects a new function called mutate into the component's props that we can use explicitly to send the mutation to the server:
const { name, url } = this.state
this.props.mutate({ variables: { name, url } }).then(data => {
console.log(data)
})However, to ensure cache consistency in that scenario, we have to configure our AddPokemonComponentWithMutation with an updateQueries object.
From the Apollo docs: Most of the time, your UI will update automatically based on mutation results, as long as the object IDs in the result match up with the IDs you already have in your store. See the
dataIdFromObjectdocumentation above for more information about how to take advantage of this feature. However, if you are removing or adding items to a list with a mutation or can’t assign object identifiers to some of your objects, you’ll have to useupdateQueriesto make sure that your UI reflects the change correctly.
In essence, the updateQueries object is a map from the name of a query (that we used previously to fetch some data) to a function that will specify how the new data that's returned from the mutation should be incorporated into the former result of the query. We thus avoid having to refetch the data for the query but instead specify how the cache should be changed after the mutation. The function that we specify follows the same principle as a Redux reducer in that it receives the previous result of the query and the mutation data and merges the two into the new query result.
Taking the example from above, we can add the updateQueries configuration like so:
const AddPokemonComponentWithMutation = graphql(createPokemonMutation, {
props({ ownProps, mutate }) {
return {
createPokemon({ variables }) {
return mutate({
variables: { ...variables },
updateQueries: {
allPokemonsQuery: (prev, { mutationResult }) => {
const newPokemon = mutationResult.data.createPokemon
return {
...prev,
allPokemons: [...prev.allPokemons, newPokemon],
}
},
},
})
},
}
},
})(AddPokemonComponent)What happens here with updateQueries is that we tell the Apollo Client to update all places where we used the allPokemonsQuery to also include the new pokemon. Once the mutation is sent and the data is returned from the server, the function we specified for the allPokemonsQuery will be called and the cache will be updated as specified. The resulting change is made available through the props of all components that were using data from that query and the UI will be rerendered.
Note that if we have multiple queries that are affected by a mutation, all of them need to be included in updateQueries individually. For example, consider this query:
const TrainerQuery = gql`
query TrainerQuery {
Trainer(name: "Ash Ketchum") {
ownedPokemons
}
}
`If we used this query at some point before and its returned data was cached, we would have to include a TrainerQuery as part of the returned object in updateQueries as well to make sure the cache is properly updated.
To find our more, you can read about other advanced mutations, managing Apollo Store or read the official mutation documentation.
2. Using ApolloCient to directly send a mutation
Rather than making the mutation available through the props of a component, we can also use an instance of the ApolloClient to directly send a mutation. The code for that would look similar to sending a query but using the mutate method of the client:
mutate({
mutation: gql`
mutation createPokemon($name: String!, $url: String!) {
createPokemon(name: $name, url: $url) {
id
name
url
}
}
`,
variables: {
name: 'Zapdos',
url:
'[http://assets.pokemon.com/assets/cms2/img/pokedex/full/145.png](http://assets.pokemon.com/assets/cms2/img/pokedex/full/145.png)',
},
updateQueries: {
allPokemonsQuery: (prev, { mutationResult }) => {
const newPokemon = mutationResult.data.createPokemon
return {
...prev,
allPokemons: [...prev.allPokemons, newPokemon],
}
},
},
}).then(result => console.log(result))Note that we can specify how Apollo should be updating the local cache after the mutation in the same way as before using updateQueries.
Subscriptions
GraphQL offers the ability for clients to subscribe to changes that are caused by mutations in a GraphQL backend. This allows the client to implement realtime functionality in an application and always keep the UI up to date with the current server-side state.
With Relay, there is not a lot of support for handling subscriptions on the client. You can use this helper package to ease up integration of subscriptions in Relay. Other than that there is not a lot of support that comes with Relay.
Apollo on the other hand offers a relatively sophisticated support for subscriptions through an additional package called subscriptions-transport-ws. If you're keen on learning more about how subscriptions work with the Apollo Client, you can read up on it in our comprehensive tutorial and checkout the example project.
Conclusion
Relay and Apollo vary greatly in their approaches how they interact with a GraphQL server and make data available to React components.
Apollo optimizes for ease of use and flexibility, thus allowing developers to get started quickly with their applications. However, making sure that the local cache is kept consistent with Apollo requires lots of manual effort and, especially in larger applications, can get pretty complicated.
Relay on the other hand is a very sophisticated system that is designed from the ground up to maximize efficiency in the communication with the server. React components express their data requirements using GraphQL fragments that are co-located to each component. This makes it easier to ensure that each component gets the data it needs even when data requirements for other components in the hierarchy are changing. Relay is doing a lot of work behind the scenes to keep its local store consistent with the state on the server. The power of Relay comes at the price difficult to grasp complexity and a slow learning curve.
Both Apollo and Relay are still actively being worked on and improved. Facebook is planning a major release they’re currently sometimes referred to as Relay Modern that is supposed to improve the developer experience and lower the entrace barrier for people getting started with Relay. Apollo very recently added their an imperative store API that allows the developer to have more fine-grained control over how the local cache should be updated after a mutation and provides an alternative to updateQueries.
Keep reading

Price the Work, Not the Workflow
Agents can ship, preview, test, and retry in loops. Infrastructure pricing should charge for the work an app performs, not the workflow around it.

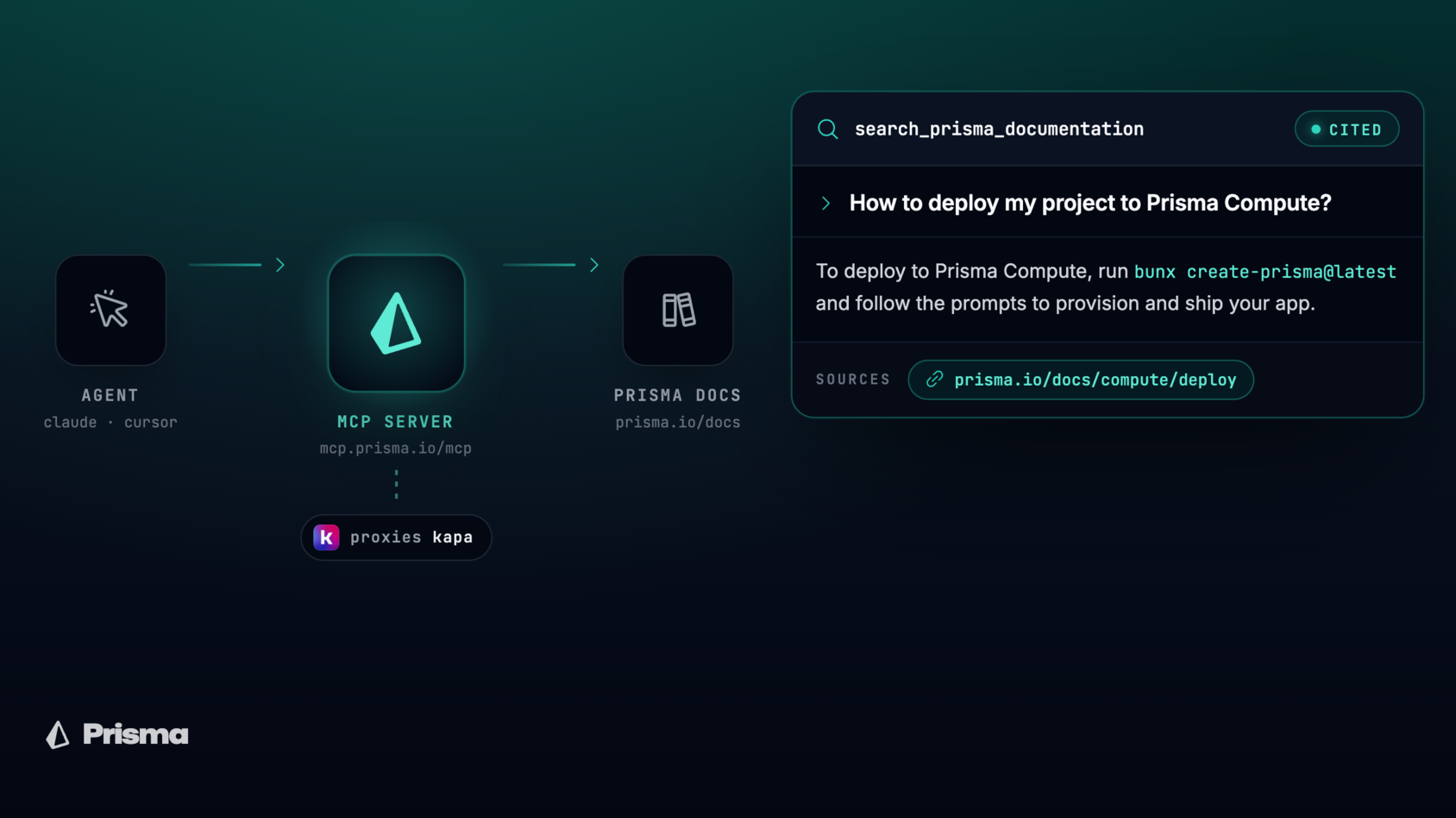
Search the Prisma Docs Using Your Coding Agent
The Prisma MCP server now answers documentation questions in your editor. Ask about ORM, Postgres, or Compute and get a cited answer, no tab-switching, no extra setup.

Build your next app with Prisma
Start free. Scale when you’re ready.