Database Caching: A Double-Edged Sword? Examining the Pros and Cons

Caching database query results can have amazing benefits for performance, cost efficiency and user experience! In this article, we'll talk about these benefits as well as the challenges and drawbacks of database caching.
Table of contents
- Why cache database query results?
- Using a traditional database cache
- Challenges of traditional caching
- Wrapping up
Why cache database query results?
When creating a web application, retrieving data from a database is essential. However, as your traffic and database size grows, database queries can become progressively slower. To provide fast responses to users, caching database query results can be a cost-effective and simple solution instead of implementing complex query optimizations or upgrading your database.
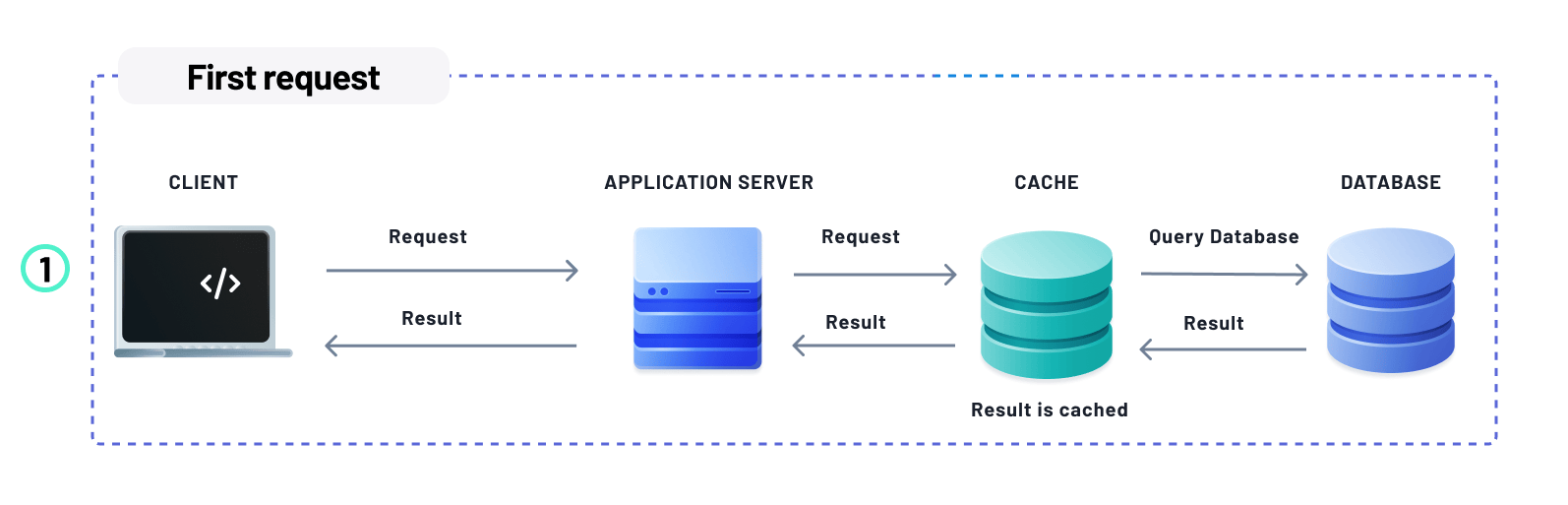
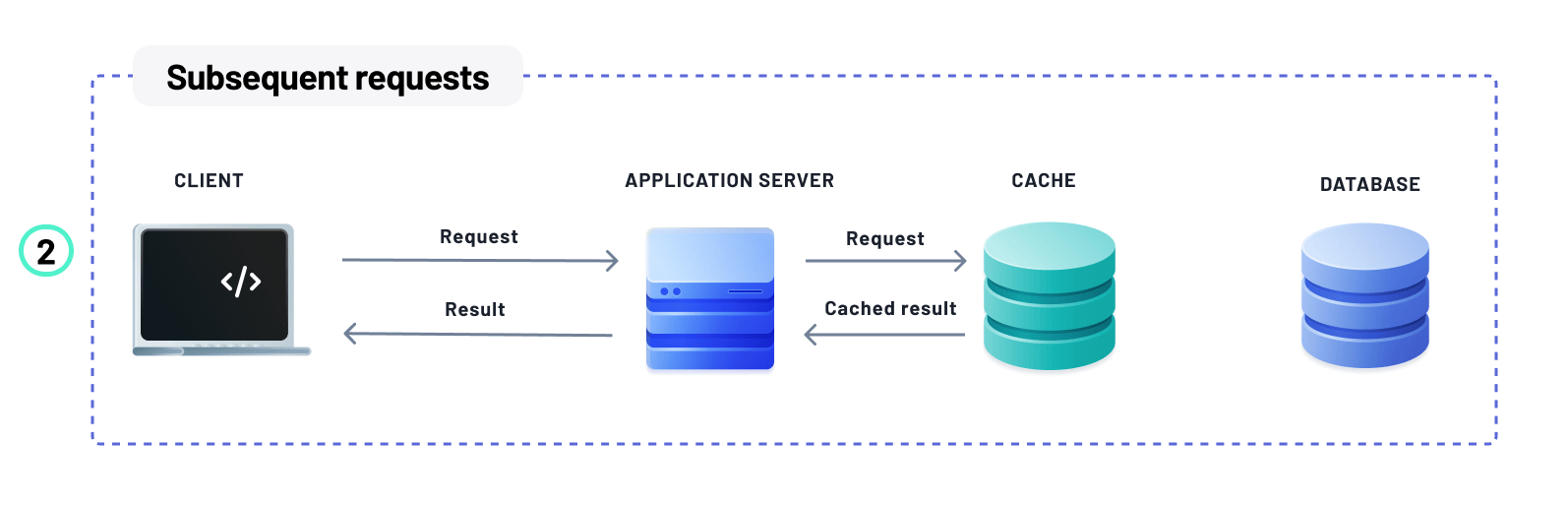
Caching significantly improves performance
Using a cache to store database query results can significantly boost the performance of your application. A database cache is much faster and usually hosted closer to the application server, which reduces the load on the main database, accelerates data retrieval, and minimizes network and query latency.
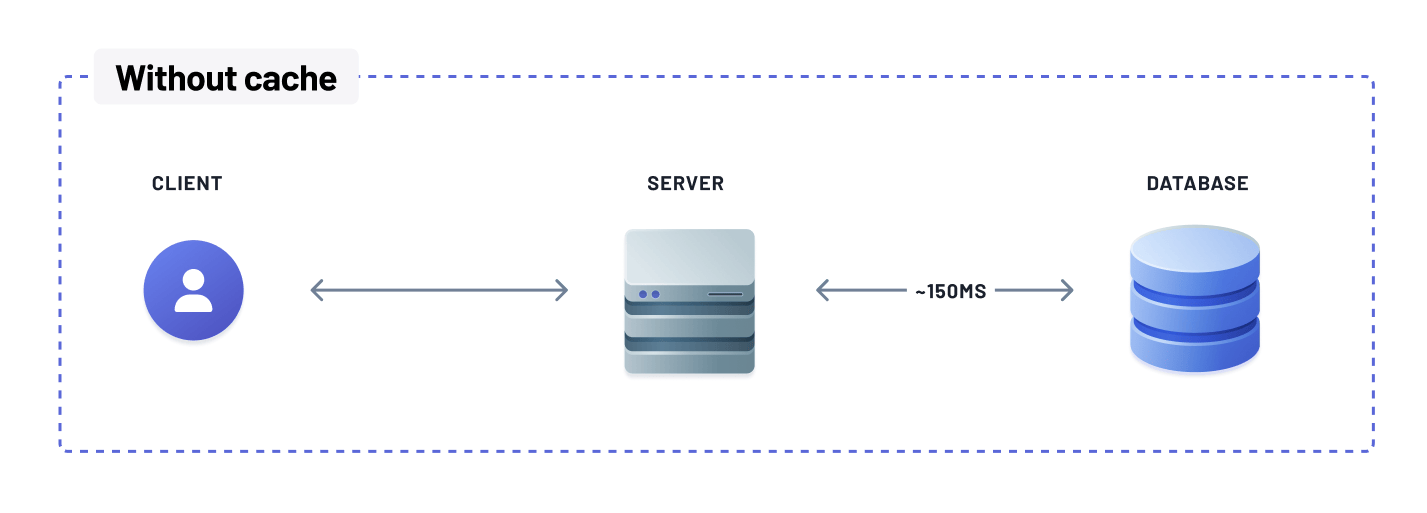
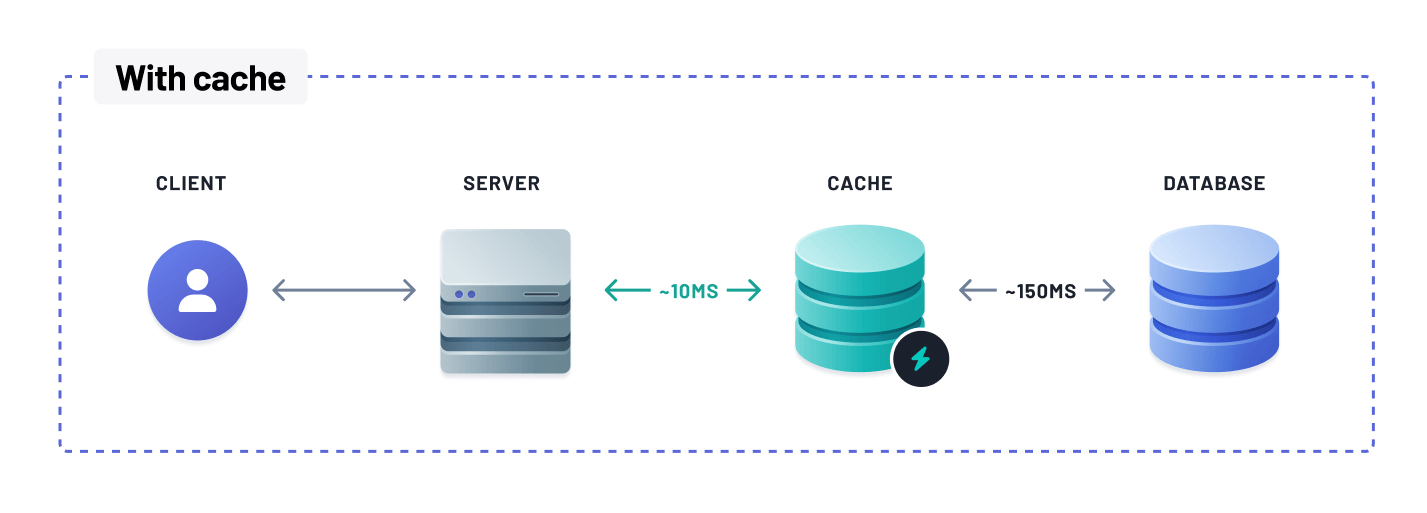
Faster data retrieval
Caching eliminates the need to retrieve data from slower disk storage or perform complex database operations. Instead, data is readily available in the cache memory, enabling faster retrieval for subsequent read requests. This reduced data retrieval latency leads to improved application performance and faster response times.
Efficient resource utilization
Caching reduces CPU usage, disk access, and network utilization by quickly serving frequently accessed data to the application server, bypassing the need for a round trip to the database.
By efficiently utilizing resources, system resources are freed up in both the database and application server, enabling them to be allocated to other critical tasks. This results in an overall system performance improvement, allowing more concurrent requests to be handled without requiring additional hardware resources.
Caching improves scalability
In addition to performance enhancements, caching also plays a crucial role in improving the scalability of your application, allowing it to handle increased loads and accommodate higher user concurrency and more extensive data volumes.
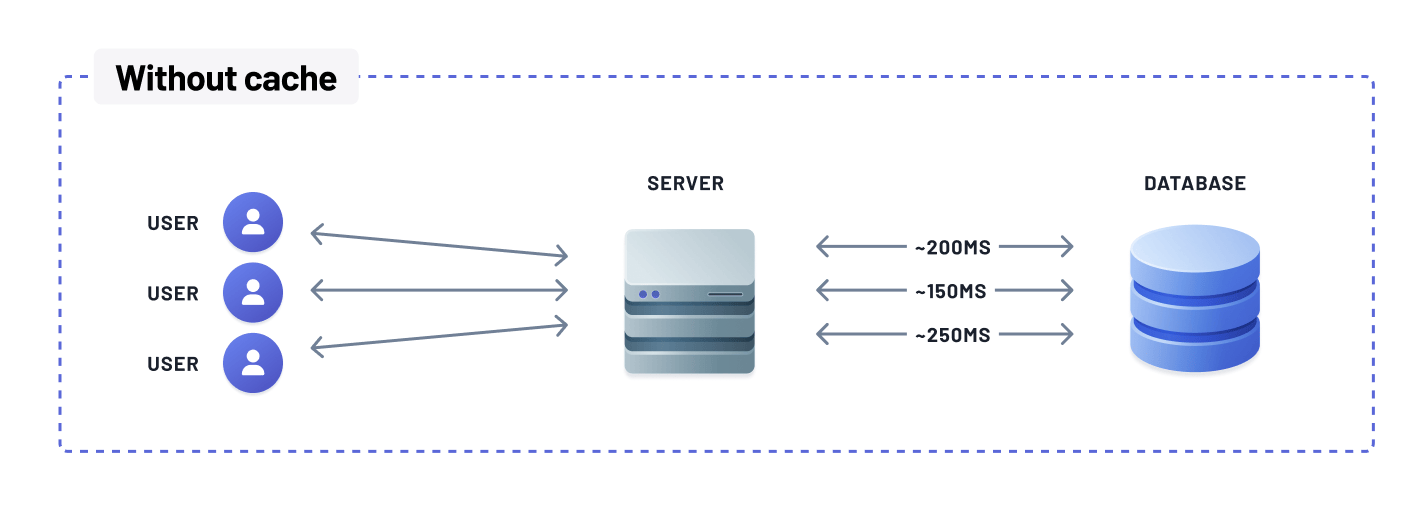
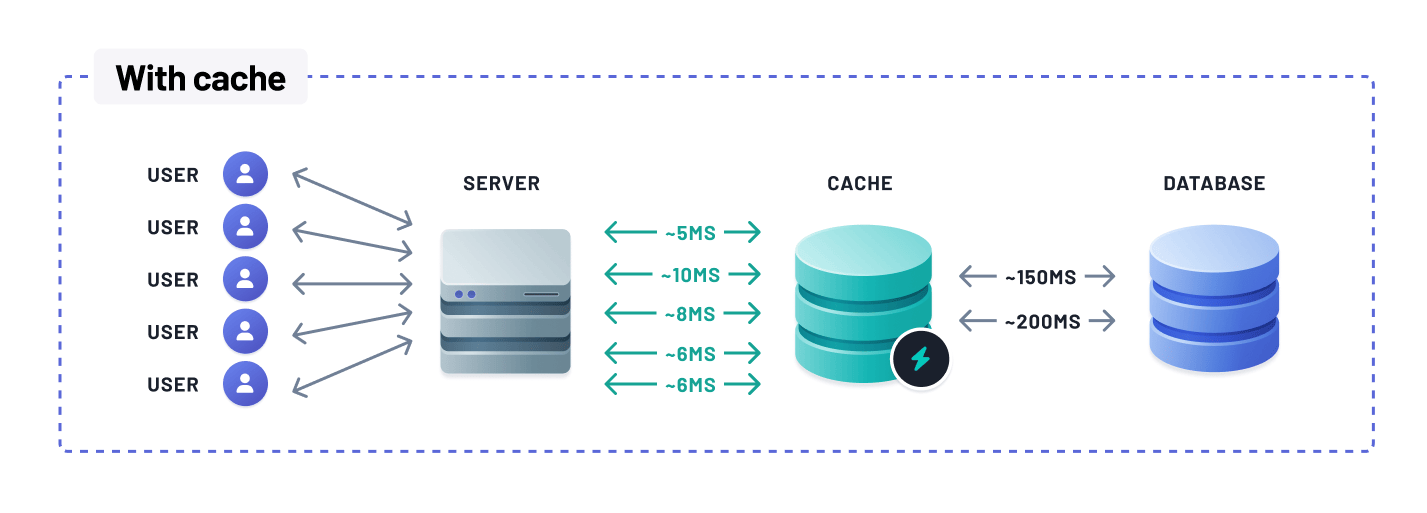
Reduced application server and database load
Storing frequently accessed data in memory through a cache enables quick retrieval of data items without querying the underlying database. This reduces the load on the database server, significantly reducing the number of database queries. As a result, the database can handle more queries with ease.
Since application servers retrieve most data from the cache, which is much faster, they can handle more requests per second. Adding a cache thus increases the system's capacity to serve users, even with the same database and server configurations. By optimizing the utilization of database resources, caching improves the overall scalability of the system, ensuring smooth operation even under high user concurrency and large data volumes.
Mitigated load spikes
During sudden spikes in read traffic, caching helps absorb the increased demand by serving data from memory. This capability is valuable when the underlying database may struggle to keep up with the high traffic. By effectively handling load spikes, caching prevents performance bottlenecks and ensures a smoother user experience during peak usage periods.
Using a traditional database cache
A common practice in web applications is to use a caching layer to improve performance. This layer, usually implemented using software such as Redis or Memcache, sits between your application server and database, acting as a buffer that can help reduce the number of requests to your database. By doing so, your application can cache and load frequently accessed data much faster, reducing overall response times to your users.
Challenges of traditional caching
While traditional caching offers many benefits, it can introduce additional complexity and potential issues that must be considered.
Cache invalidation is hard
Cache invalidation is the process of removing or updating cached data that is no longer accurate. This helps ensure data accuracy and consistency, as serving outdated cached data can lead to incorrect information for users. By invalidating the cache, users get the most accurate data, resulting in a better user experience.
There are several considerations to make when invalidating the cache. Some core aspects are:
Time
Time is crucial in determining when to invalidate the cache. Invalidating it too soon would result in more redundant requests to the database while invalidating it too late would serve stale data.
Granularity
A cache can store a large amount of data, and it is difficult to know which cached data to invalidate when a subset of that data changes in the underlying database. Fine-grained cache invalidation can be an expensive operation, while coarse-grained invalidation results in unnecessary data being removed.
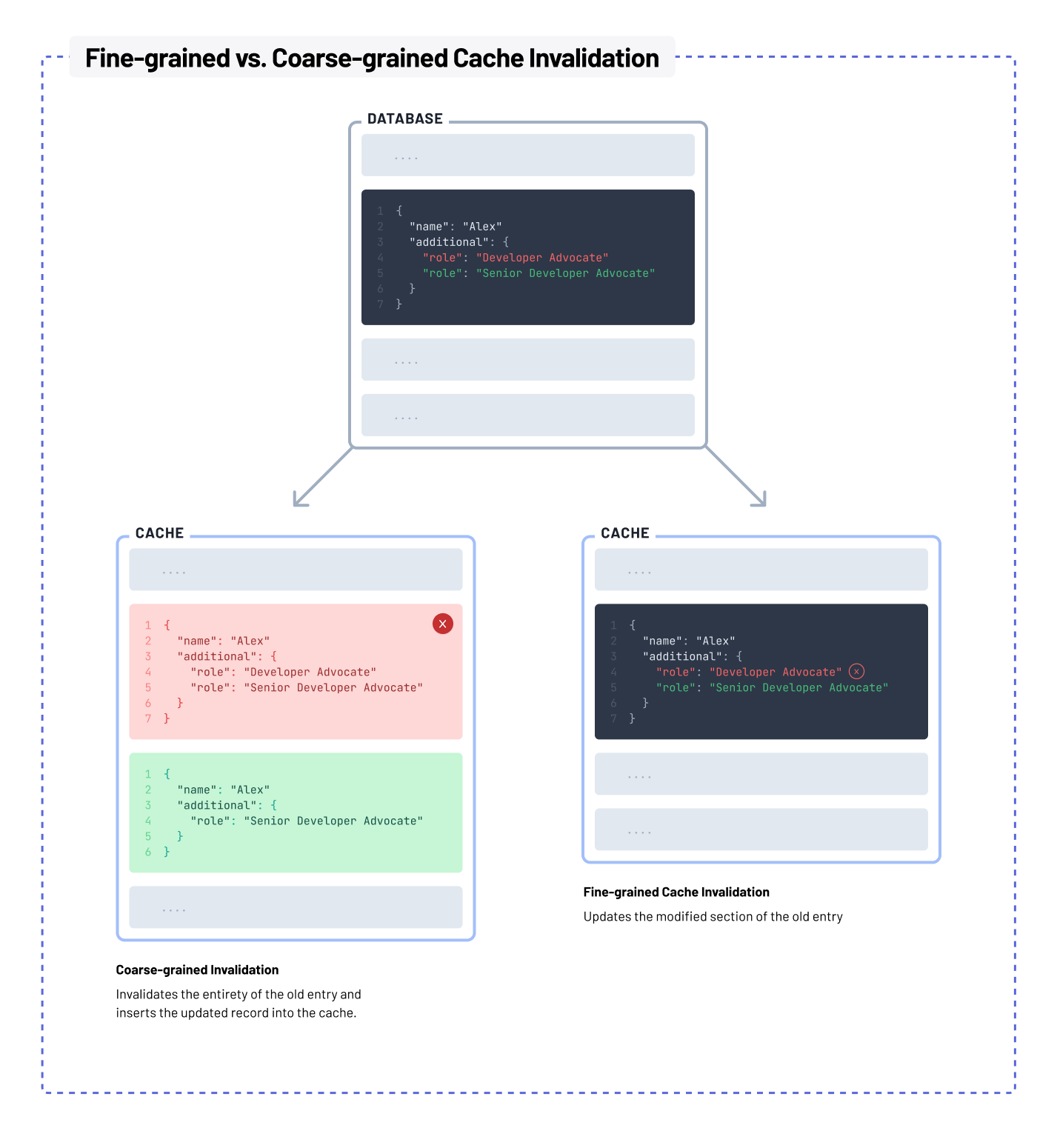
Coherency
When using a globally distributed cache, invalidating a cache item requires that it is reflected across all nodes globally. Failure to do so results in users in specific regions receiving stale data.
A load balancer should be used between your application servers and distributed cache servers to manage traffic. Additionally, a synchronization mechanism is required to reflect changes across all cache nodes to prevent the serving of stale data.
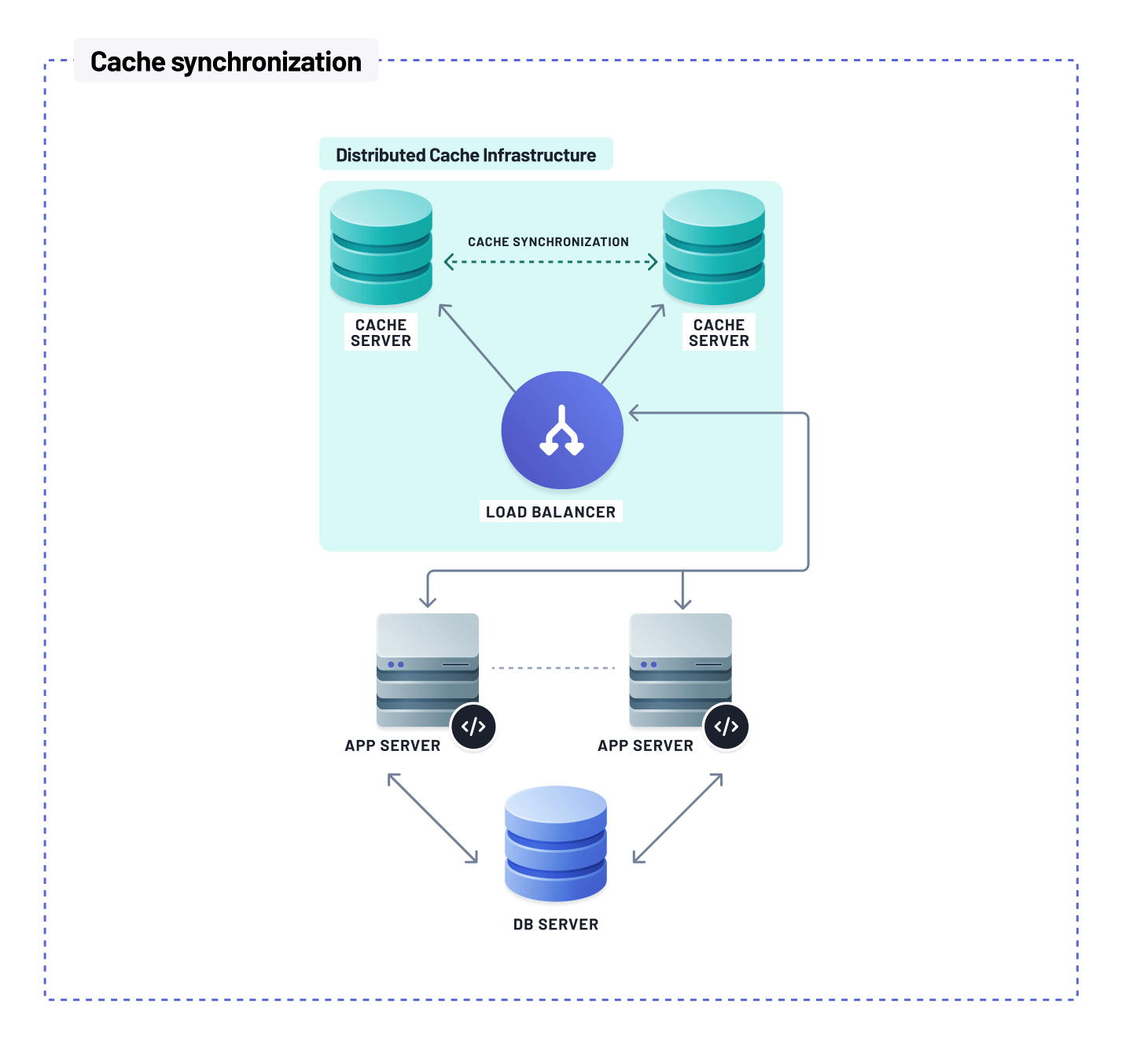
A caching system can be complicated to manage
Hosting and managing a cache layer between your server and database requires additional maintenance effort. It's important to use the right monitoring tools to keep an eye on the health of your caching service.
Situations such as a cache avalanche may occur when, for some reason, the cache set or the cache system fails, or there is no data in the cache within a short period of time. When this happens, all concurrent traffic goes directly to the database, putting extensive pressure on it. As a result, there is a significant drop in application performance, which can cause downtime.
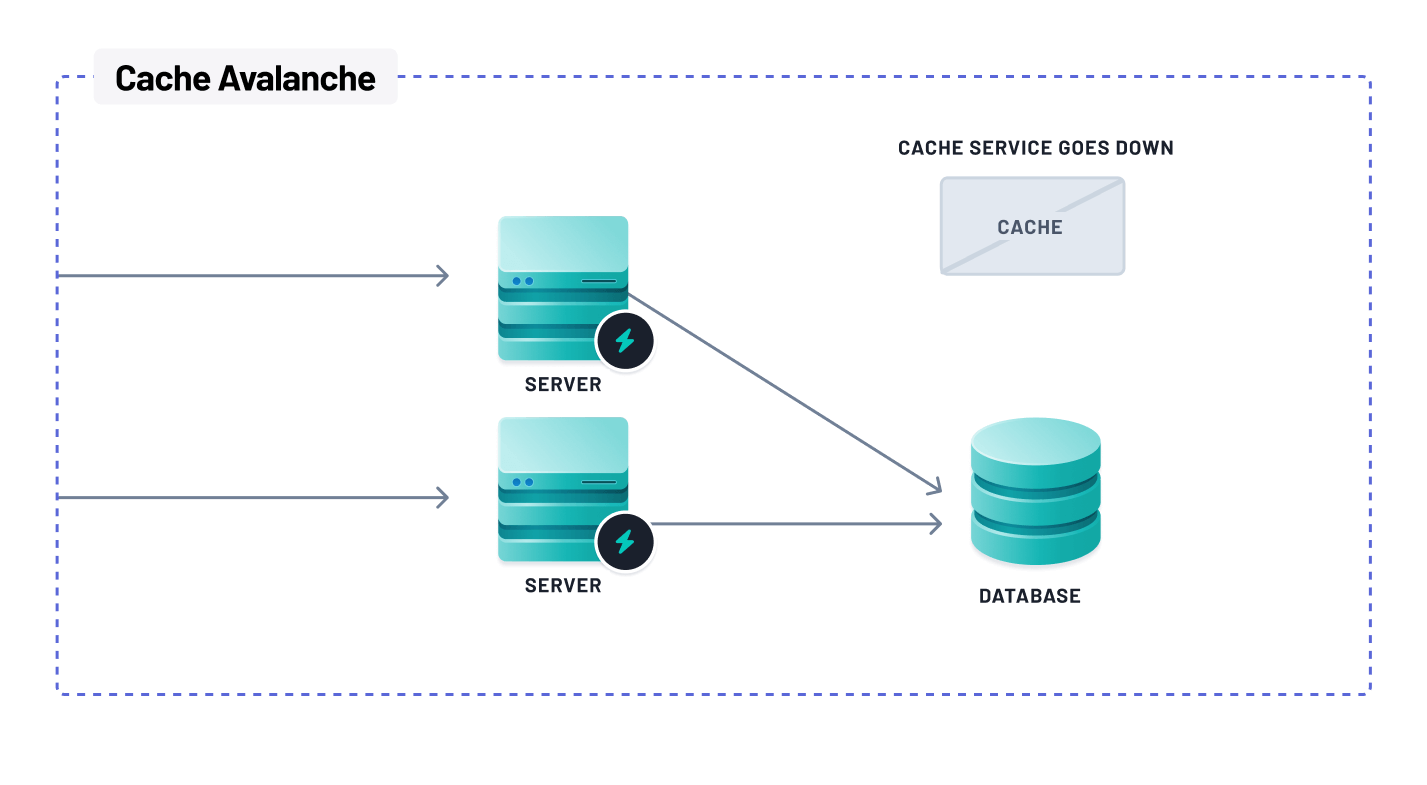
To avoid such scenarios, proper planning, expertise, and ongoing maintenance are necessary to handle these complexities and ensure a reliable and high-performance caching infrastructure.
Managed caching services can be expensive
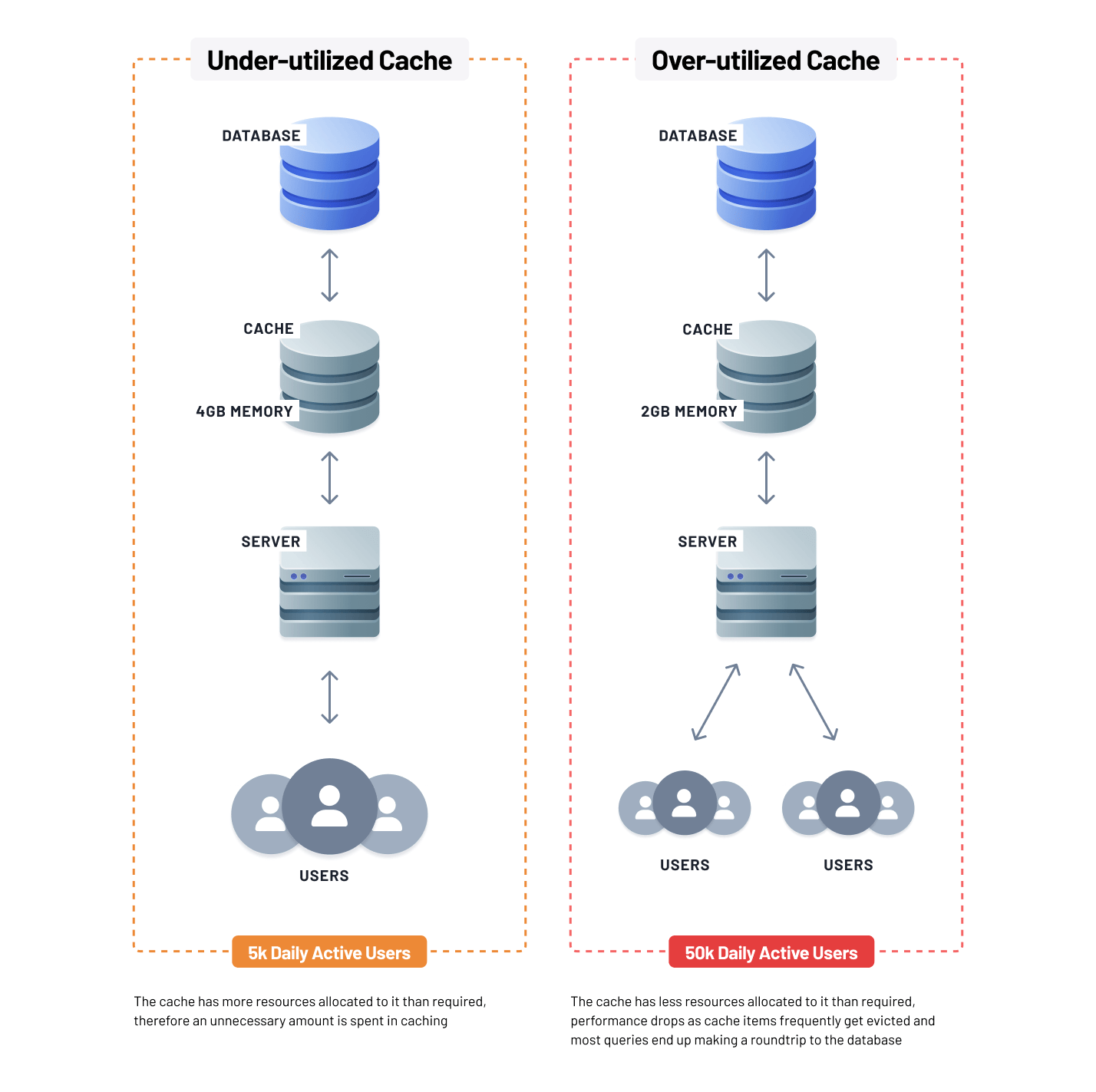
Caching utilizes memory storage to enable fast data retrieval. However, managed cache memory database services can be expensive, and adding more memory can increase costs. Over-provisioning the cache can lead to waste and unnecessary expenses, while under-provisioning may result in poor performance due to frequent database access. Therefore, proper capacity planning is crucial.
To estimate the optimal cache size, historical usage patterns, workload characteristics, and anticipated growth should be taken into consideration. Scaling the cache capacity based on these insights ensures efficient resource utilization and performance while managing the cost of memory allocation against caching benefits.
Synchronizing the cache globally is challenging
Some bsinesses use a distributed cache to ensure consistent performance across regions, but synchronizing it globally can be complex due to coordinating challenges across different regions or systems. To achieve real-time cache coherence and data consistency, efficient communication mechanisms are required to mitigate network latency and concurrency control issues and prevent conflicts.
Maintaining global cache synchronization requires trade-offs between consistency and performance. Strong consistency guarantees increased latency due to synchronization overhead, which can impact overall system responsiveness. Striking the right balance between consistency and performance requires careful consideration of specific requirements and constraints of the distributed system.
To address these challenges, various techniques and technologies are employed, such as cache invalidation protocols and coherence protocols, which facilitate the propagation of updates and invalidations across distributed caches. Distributed caching frameworks provide higher-level abstractions and tools for managing cache synchronization across multiple nodes. Replication strategies can also be implemented to ensure data redundancy and fault tolerance. Achieving global cache synchronization enables distributed systems to achieve consistent and efficient data access across geographic boundaries.
Debugging caching-related bugs can be challenging
Debugging and troubleshooting can be challenging when issues arise with the caching logic, such as stale data being served or unexpected behavior. Caching-related bugs can be subtle and difficult to reproduce, requiring in-depth analysis and understanding of the caching implementation to identify and resolve the problem. This can drastically slow down the software development process.
Wrapping up
In conclusion, when implemented correctly, database caching can significantly enhance your application's performance. Using a cache to store query results, you can effectively address high query latencies and greatly improve your application's responsiveness. So, don't hesitate to leverage the power of database caching to unlock a smoother and more efficient user experience.
At Prisma, we aim to simplify the process of caching for developers. We understand that setting up a complex infrastructure can be tricky and time-consuming, so we built Accelerate as a solution that makes it easy to cache your database query results in a simple and predictable way. Follow us on X/Twitter or join us on Discord to learn more about the tools we're building.
Keep reading

Prisma Postgres vs Neon Pricing 2026
Is Prisma Postgres or Neon cheaper? They bill for different things: operations vs compute-hours. A side-by-side breakdown to match pricing to your usage.


Prisma Next Is ~90% As Fast as Raw PG
Prisma Next performance benchmarks achieves ~90% of the raw pg driver's peak throughput, holds latency low under load, and ships as a 148.5 KB gzipped bundle for serverless and edge workloads.

Build your next app with Prisma
Start free. Scale when you’re ready.