How Prisma & Serverless Fit Together

As we shift towards a serverless world, we create new opportunities and new problems to be solved. One problem has Prisma's attention: how to make databases fit into a serverless world.
Table of contents
- A brief history of deployment
- Serverless gives you the freedom to focus on building your application
- Edge puts your application as close to the user as possible 🌎
- Serverless isn’t perfect though
- We at Prisma want to fix these problems
- TL;DR
A brief history of deployment
The way software is deployed has evolved many times over the years to meet the needs of new and emerging technologies and enable teams to build more scalable systems.
At Prisma, we want to provide a great developer experience to those working with databases in applications deployed on what we see as the future of software deployment: serverless and the edge.
In this article, we want to take a step back and consider how software was deployed in the past to better understand the advantages and tradeoffs these new deployment types offer.
Bare-metal 🤘🏻
You may have been (un)fortunate enough to have been a developer during the bare-metal (or on-premise) deployment phase of development.
A bare-metal deployment is a deployment made on a physical server that is set up and managed on-premise, likely by a systems administrator. The provisioning of software updates, hardware updates, etc... is all manually done directly on a physical machine by a human being.
Even in its simplest form, bare-metal deployments are difficult as they require specialized knowledge of physical servers, how to network those servers, and how all of the individual pieces of an application's infrastructure tie together.
Virtual machines
As teams grew tired of managing so many physical machines and maintaining facilities to house that hardware, they turned to a new technology that allowed them to create virtual machines that host their applications.

A virtual machine is essentially a virtualized copy of a complete physical machine that can be run on physical hardware.
A common example of this is the Amazon EC2 service. With EC2, a virtual machine can be provisioned on one of Amazon's many physical servers, allowing developers to deploy their applications without the hassle of managing the host's hardware. If something goes wrong with the physical server, the cloud provider (AWS in this case) handles moving the virtual environment to a new machine.
Containers
The last incarnation of deployments we will talk about before getting into serverless is containers.
A container is an isolated space on a host machine's operating system that can exist and operate independently from the other processes running on that host. This means developers may run multiple containers on their machines as completely isolated virtualized machines.

The most common example of a containerization tool is Docker. Docker makes it easy for developers to host multiple applications with different environmental requirements on a single machine in a way that closely matches the production environment.
With this breakthrough, the developer can simply build a container and give it to their cloud provider, who will handle deploying it to a machine along with many other containers.
Serverless gives you the freedom to focus on building your application
Notice in each iteration of the deployment paradigms mentioned above, more and more responsibility of managing the infrastructure was passed off to a cloud provider. However, even using containerization, the developer is required to configure a container that runs their code.
As a developer, you want to spend your time building the core of your business, not thinking about infrastructure. Functions as a Service (FaaS) allow developers to deploy serverless functions while handing many of those tedious infrastructure-related tasks off to a cloud provider so they can focus on building their products.
While deploying a serverless application means giving up some of that granular control a developer might have had otherwise, the return can certainly be worth it.
Quick deployments
Serverless deployments are super simple compared to alternative deployment models. The developer no longer has to think about uploading code to multiple servers while ensuring there is no downtime.
They can simply make a change to a serverless function and upload those changes to whichever service they are using. A cloud provider then handles distributing those changes to a production environment.
This allows developers to iterate much more quickly than they otherwise would have been able to.
Geographic flexibility by deploying to different regions
Long-distance network requests cause latency that is only cured by bringing the request destination closer to the user sending that request.
Because serverless does not rely on a singular server to host your application, developers have the option to easily deploy their applications to many different regions. This allows them to put their product as close to the users as possible, eliminating that latency as long as the user is close to the geographical deployment zones.
Scales from 0 → ∞
Unlike a long-running server, serverless environments are ephemeral. When an application or function is not in use, it is automatically shut down until a new request triggers its invocation.
This is one of the major benefits of serverless as it allows developers to forego being careful about provisioning their infrastructure and focus more on their applications.
Along with those significant cognitive savings, while an application is not running developers are not charged for usage. Scaling up to infinity is an exciting idea, but scaling down to zero is where the true power lies from a financial perspective. Scaling to zero allows the developer to only pay for the compute they need rather than paying constantly for a long-running service.
Edge puts your application as close to the user as possible 🌎
Deploying to "the edge" takes the benefits of serverless one step further. Before getting into how it helps to understand what it means to be on "the edge".
An application that is deployed to the edge refers to one that is deployed across a widely distributed network of data centers in many regions, putting the application close to every user, not just some users. In this context, "the edge" typically refers to "the edge of the network".
In the most technical sense, any deployment model can be "at the edge" if it is deployed across every geographical region. That being said when we at Prisma refer to "the edge", we refer specifically to serverless deployments to the edge as this is the most feasible way to get there. Cloudflare Workers, Vercel Edge Functions and Deno Deploy are examples of this.
Edge networks like Cloudflare consist of globally distributed data centers where you can host your applications. When you deploy to an edge network, your application's code is automatically distributed to each of these data centers.
The reason the idea of the edge is so powerful and exciting is that it extends the ideas of serverless deployments to its extreme limits, removing geographical latency from the equation completely by placing your application close to every user.
Serverless isn’t perfect though
Up until now, this article has framed serverless as the ultimate solution for a developer's deployment needs. There are, however, some caveats to consider as the major shift in paradigms comes with some tradeoffs and new complexities.
Size limitations
A serverless function lies dormant until a request triggers it to life. To make this experience viable, that function should be able to jump into action very quickly.
The size of a bundled serverless function has a direct effect on the speed that function can be instantiated. Because of this, serverless functions have limitations on the size of the artifact that is deployed.
Ideally, in a serverless architecture, developers will be deploying small, modular functions rather than entire applications. If the size of those functions grows beyond the limitation of the cloud provider, that may be a sign for the developer to reconsider their design and how they bundle their code.
Note: Check out this article that details some best practices to follow when deploying serverless funcions.
Short-lived environments & cold starts
After a serverless function has done its job, it will remain alive for a limited amount of time waiting for additional requests. Once that time is up, the function will be destroyed.
This is a positive behavior of serverless functions as it is what allows serverless functions to scale to zero. A side-effect of this, however, is that once the function scales to zero, new invocations require a new function to be instantiated to handle the request. This takes a little bit of time (or a lot in some cases). This time is often referred to as a cold start.
In a serverless architecture, developers hand off the management of their infrastructure to the cloud provider. This means they don't get much of a say in how that function is instantiated or insights into where the time is spent during a cold start.
Note: We recently published an in-depth article about the startup time of serverless functions.
Your infrastructure can scale but your database can’t
There is one other major point to consider when thinking about serverless that we will mention in this article.
Serverless and edge are making huge strides toward a world where developers don't have to worry about scaling their infrastructure and can focus on building their applications — however, databases still have ways to go in terms of scalability.
One of the major benefits of serverless is the ability to easily host an application close to its users. The result is a snappy experience as data does not have to travel very far to get to the user.
Databases in a serverless setting, however, become a performance bottleneck. A serverless application may be widely distributed, but the database is still likely tied down to a single data center.
Note: There are a few exceptions to this such as distributed databases (like CockroachDB and PlanetScale) and databases that offer alternative connection methods (like Fauna and Neon).
The symptom of this problem is that requests still end up with the network hops across large geographical distances to connect to and query the database, forfeiting the benefit serverless brings of low-latency requests.
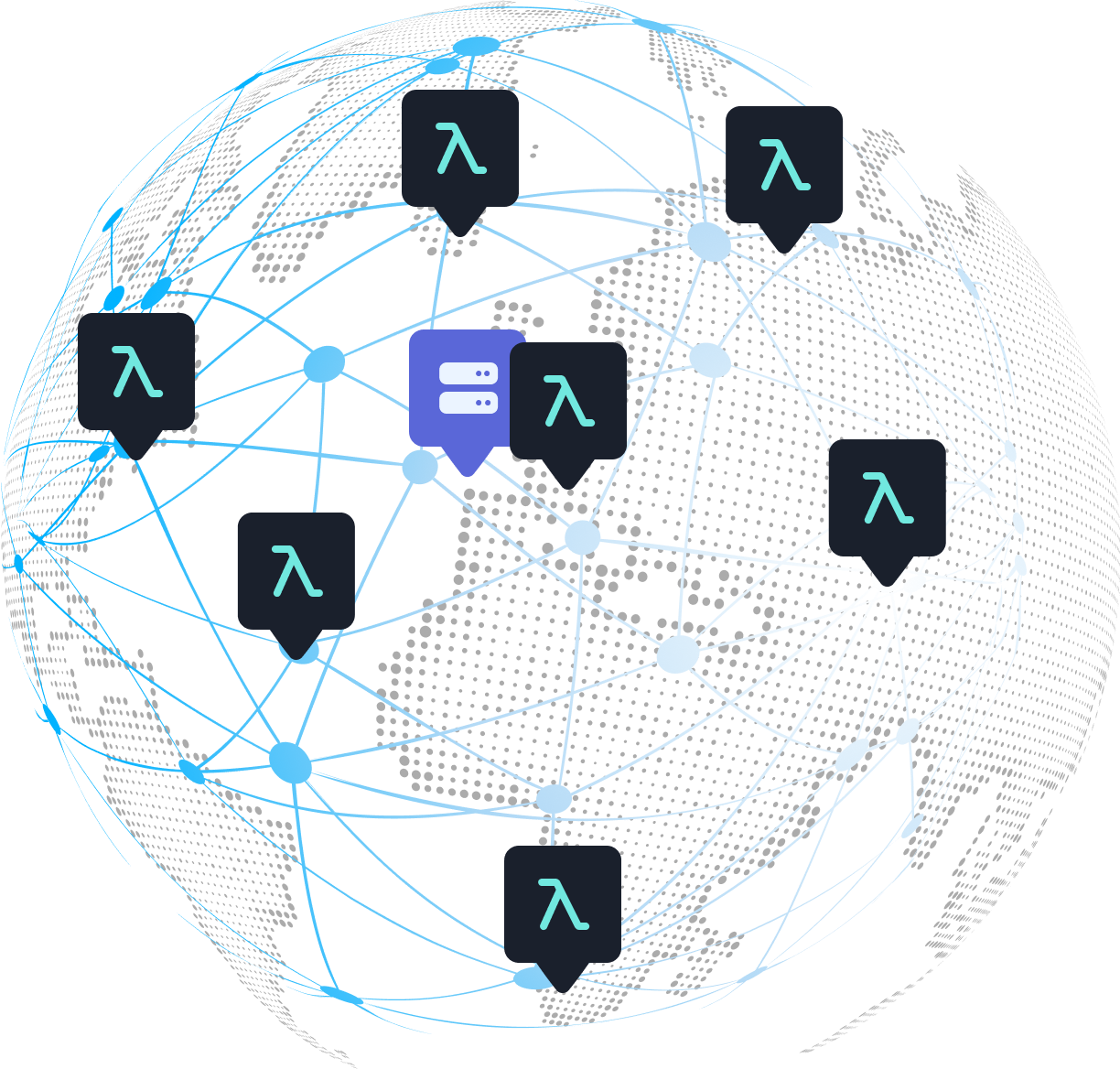
Another side-effect of the ephemeral nature of a serverless function's environment is that long-lived connections are not viable. The implications of this can be huge, especially when interacting with a traditional relational database.
In a long-running server, a TCP connection from the application to the database is made and kept alive, allowing the application to query the database using that connection. With serverless this is not possible.

As applications scale up and multiple functions handle requests, each function will create a connection pool to the database. This will easily exhaust the database's connection limits.
We at Prisma want to fix these problems
We believe all of the problems illustrated above can be fixed, and our goal is to tackle them in an easily accessible and usable way.
Just as serverless allows developers to not worry as much about their infrastructure and focus on their code, we want developers to not have to worry about their data needs when working in a serverless setting.
Data Proxy
Our first attack on these problems came in the form of our Data Proxy. The goal of this product is to eliminate the connection pooling problem by proxying the connection from Prisma ORM to the database with a connection pooler. This provides an HTTP-based proxy, as TCP is not usable in most serverless and edge runtimes.
Data Proxy also runs Prisma's query engine, allowing developers to remove that dependency, which can be rather large, from the bundled artifacts that get deployed.
The result is a clean way to handle connection pooling while also significantly decreasing the size of the developer's serverless function.
Accelerate
To tackle some of the latency problems when deploying functions to the edge, we turned to caching. Caching, however, is not something that is easily set up and maintained on a global scale.
That's why we built Accelerate. This product aims to allow developers to define caching strategies within their serverless and edge functions on a per-query basis. That cache is automatically distributed globally across Cloudflare's edge network so it is close and available to every user.
Note: Watch this episode of What's New In Prisma to hear one of our engineers talk about Accelerate.
The result is that no matter how distributed an application is, using Accelerate allows the developer to eliminate long-distance network requests and serve up their data quickly.
On the horizon
Along with Prisma Accelerate, we are working on several other products that aim to solve the problem of data access on serverless and at the edge.
We have identified many data access needs that only become more complicated when a serverless environment comes into play. We think these complications can be remedied, allowing developers to focus on building their applications while we at Prisma handle those difficult pieces.
We have taken a lot of inspiration from an article written by Shawn Wang (aka @swyx) titled The Self Provisioning Runtime. Specifically, from this quote:
"If the Platonic ideal of Developer Experience is a world where you 'Just Write Business Logic', the logical endgame is a language+infrastructure combination that figures out everything else." (@swyx)
For Prisma, that means providing services that allow developers to access and interact with their data however they need to without having to worry about the infrastructure required to do so.
TL;DR
To quickly recap what was said above, we at Prisma believe software deployment and infrastructure have evolved in a positive direction over the years.
As we get closer and closer to a world where developers can focus completely on their code and allow a cloud provider to "figure out" how to best deploy it, we find ourselves with new problems to consider.
We are focusing our attention on addressing those that are related to data access, have already built and released two products focused on these problems, and have several products in the pipeline that will further democratize data access from a serverless or edge function.
If you want to keep up with what we are doing here at Prisma, be sure to follow us on X/Twitter.
These are exciting times at Prisma, and exciting times to be a developer. We hope you will follow along on our journey to make data access easy!
Keep reading

Price the Work, Not the Workflow
Agents can ship, preview, test, and retry in loops. Infrastructure pricing should charge for the work an app performs, not the workflow around it.


App Hosting and Compute Platforms for AI Agents in 2026
A field guide to the 2026 wave of app-hosting and compute platforms (Prisma Compute, Neon, Cloudflare Containers, Hosting.com, Unkey, and Insforge) and how close each gets to one coherent stack for agents.

Build your next app with Prisma
Start free. Scale when you’re ready.