Improving Query Performance with Indexes using Prisma: Introduction

A database index is a smaller, secondary data structure the database uses to find matching rows without scanning the whole table. Indexes are the most common way to speed up slow read queries, and they come with a cost on writes and storage. This article covers the fundamentals: what indexes are, how the database decides to use them, the main index types, and when adding one is worth it. Parts two and three of this series put the theory into practice with B-tree and hash indexes in a Prisma ORM schema.
Updated (July 2026): Revised as part of a refresh of this series. The fundamentals in this introduction are version independent; the hands-on measurements in part two were verified end-to-end on Prisma ORM 7.8 and PostgreSQL 17.
What we can learn about databases from a book library
A database is like a library. Books in a library are usually well organized, much like data in a database. Both provide great structures for storing vast amounts of information for later retrieval.
Continuing with the library analogy, libraries store large amounts of data. The more books you have, the longer the time it takes to find a book. The time taken to retrieve a book can be influenced by the strategy for storing and searching books in the library.
Storing books in smaller shelves (partitioning)
You may naively organize the books into one big shelf alphabetically according to the title, for example. One strategy for retrieving a book faster would be storing them in smaller bookshelves in alphabetical ranges.
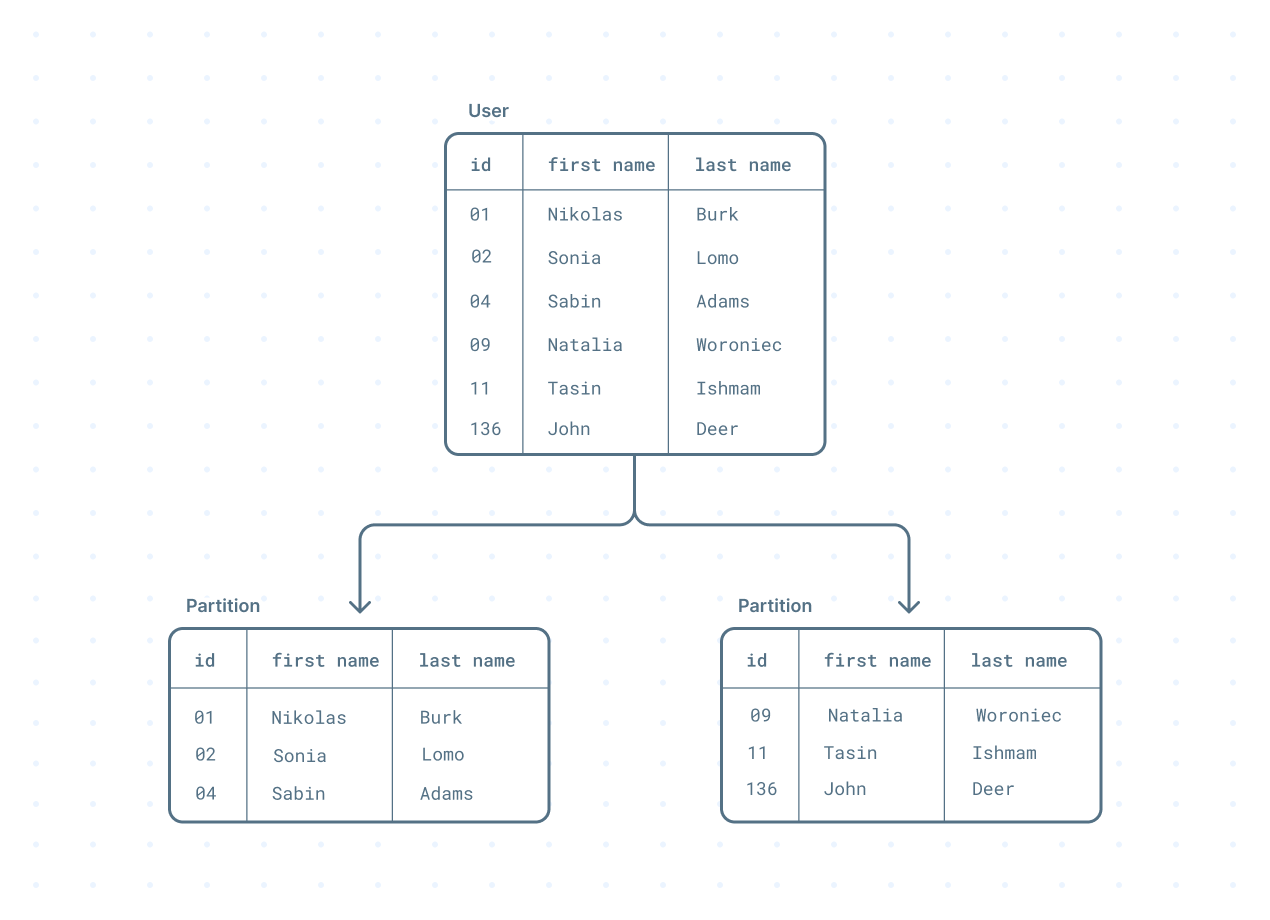
This is similar to partitioning a table in a database. A table is split into smaller chunks by a partition key which is included in a query. A partition key is the column used to split the table. The database narrows down the data to be queried using the partition key.
More people searching leads to faster searches (query parallelization)
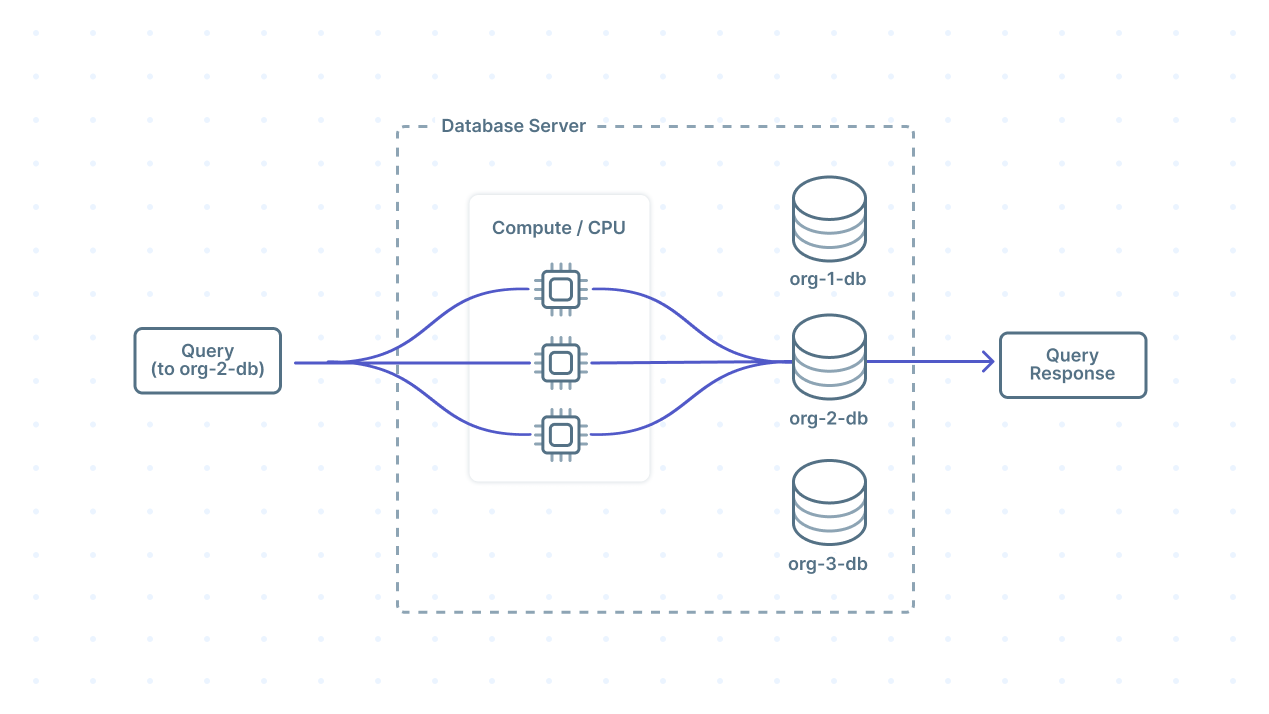
Another strategy for faster book retrieval would be to ask more people to join your search and distribute their work in a structured way. Some databases support a similar pattern where the database server can assign more compute or CPU cores to execute a query. This is known as parallel query execution.
Using a catalog to store book metadata for faster retrieval (indexes)
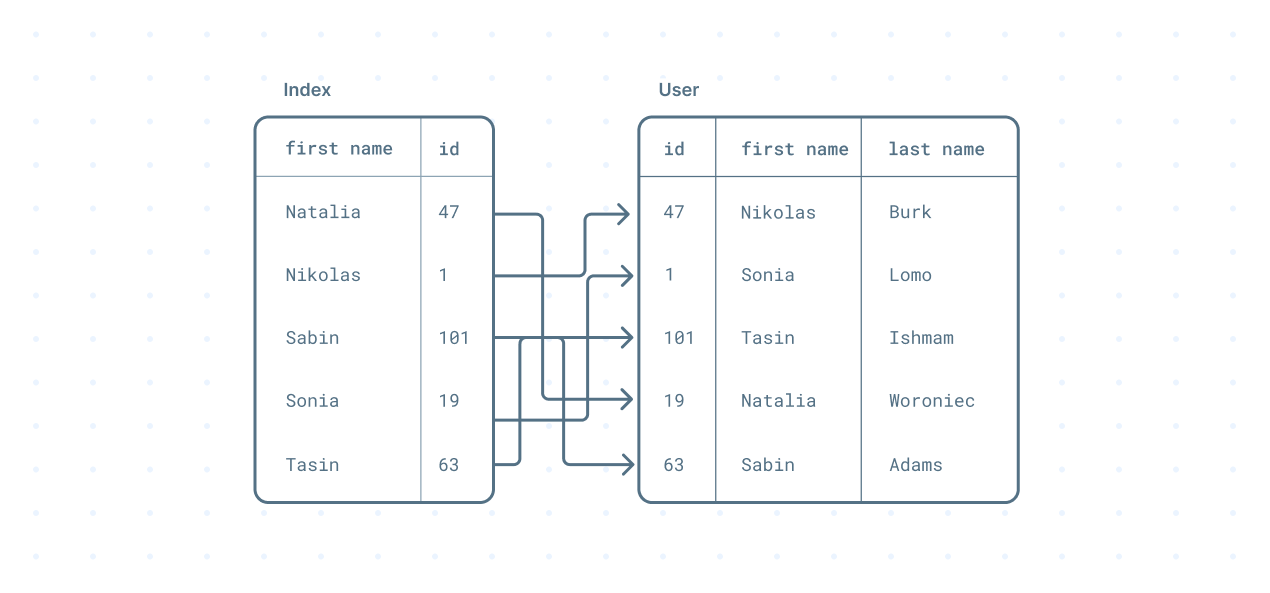
Another pattern you could use to retrieve a book is using a catalog. The catalog is an external, organized structure separate from the existing shelves containing the metadata of the books in the library. The metadata contains information such as titles, authors, subjects, publication dates, and the book's location. Databases provide similar structures called indexes.
Conclusion: You can speed up search time by reducing search scope
The common denominator for all three strategies is retrieving data faster by reducing the scope of the search.
The rest of the article will explore database indexes: what they are and how they work, benefits, cost, the anatomy of a query, and how to identify slow database queries.
What are database indexes?
A database index is a smaller, secondary data structure used by the database server to store a subset of a table's data. Indexes are commonly used to improve the read performance of a given table.
Indexes contain key-value pairs:
- key: the column(s) that will be used to create an index
- value: and a pointer to the record in the specific table
You can index more than one column in a table. For example, if you have a table called User with 3 columns:id, firstName, and lastName, you can create one index on the firstName and lastName columns.
The length of an index may be identical to the original column in the table but indexes have a smaller width.
Types of database indexes
There are different types of indexes, each one suitable for a different use case. Some of the general categories of indexes include but are not limited to:
- Index (default): a normal, non-unique index that does not enforce any constraints on your data
- Primary keys: used to uniquely identify a row in a table
- Unique indexes: used to enforce uniqueness of a value in a column, preventing duplicate values
- Full-text indexes: used on text columns and enables full-text search
There are more specialized types of indexes different databases support. Some of the other types include hash indexes, GIN indexes for PostgreSQL, and clustered indexes for SQL Server.
This series covers the two most common index types in practice: B-tree indexes in part two and hash indexes in part three, both defined directly in a Prisma schema.
Anatomy of a database query
When the database receives a query, it first creates a query plan. A query plan is a list of instructions the database needs to follow to execute a given query.
The query plan specifies how the database intends to retrieve records. The database chooses the most optimal query strategy.
You can prefix your SQL query with EXPLAIN to see information about your database's query plan. Josh Berkus, a former PostgreSQL core team member, explains the query planner in "Explaining EXPLAIN", a talk from a Prisma online meetup:
Sequential scans go through the entire table
One path the database might choose is look through each row in a table to find the records matching the filters. This is known as a sequential scan or full table scan.
If you're working with a large dataset, sequential scans will slow down your queries. The time taken to find a record is influenced by the size of your dataset. The bigger the dataset, the longer it takes to retrieve a record.
Index scans first look up metadata to find the record faster
Another path the database might choose is query the index, matching the filter with the values available in the index. The database then "consults" the original table for more data such as more columns. This is known as an index scan.
Index-only scans look up the record in the index directly
The database might also choose to return the matching records from the index without even "consulting" the original table. This is known as an index-only scan. This can happen when the columns being returned and being filtered on already exist in the index. Here's an example that could make use of an index-only scan.
SELECT "firstName" FROM "User" WHERE "firstName" = 'Jimmy';Other database providers such as PostgreSQL support other types of query plans such as bitmap heap scan and bitmap index scans. You will see a bitmap index scan in action in part two of this series.
The price you pay for faster reads
The universal consensus is that indexes are great for speeding up read performance. However, indexes come at a cost.
You will incur additional overhead for your write operations. This is because every write requires the index to be updated as well.
The other cost of indexes is that they require additional resources from the database server for maintenance. Indexes require additional storage, memory, and IO from the database server.
A general rule of thumb is to use indexes sparingly and on columns that are queried frequently. You should also select the appropriate index type based on your requirements.
Frequently asked questions
Summary and next steps
In this article, you learned what a database index is, the different types of database indexes, the anatomy of a database query, and the cost of using database indexes to optimize your queries.
In part two, you will put this into practice: declare a B-tree index with @@index in a Prisma schema, measure a query over 500,000 rows before and after with EXPLAIN ANALYZE, and watch it get about 80x faster. Because the index lives in your Prisma schema, it is declared in code, reviewed with the rest of your changes, and applied the same way in every environment, from a local Prisma Postgres database to production. Part three does the same for hash indexes.
Build your next app with Prisma
Start free. Scale when you’re ready.