Improving Query Performance with Indexes using Prisma: B-Tree Index

One strategy for improving performance for your database queries is using indexes. This article will dive a deeper into B-Tree indexes: taking a look at the data structure used and improve the performance of an existing query with an index using Prisma.
Overview
- Introduction
- The data structure that powers indexes
- The time complexity of a B-tree
- When to use a B-tree index
- Working with indexes using Prisma
- Summary and next steps
Introduction
The first part of this series covered the fundamentals of database indexes: what they are, types of indexes, the anatomy of a database query, and the cost of using indexes in your database.
In this part, you will dive a little deeper into indexes: learning the data structure that makes indexes powerful, and then take a look at a concrete example where you will improve the performance of a query with an index using Prisma.
The data structure that powers indexes
Database indexes are smaller secondary data structure used by the database to store a subset of a table's data. They're collections of key-value pairs:
- key: the column(s) that will be used to create an index
- value: a pointer to the record in the specific table
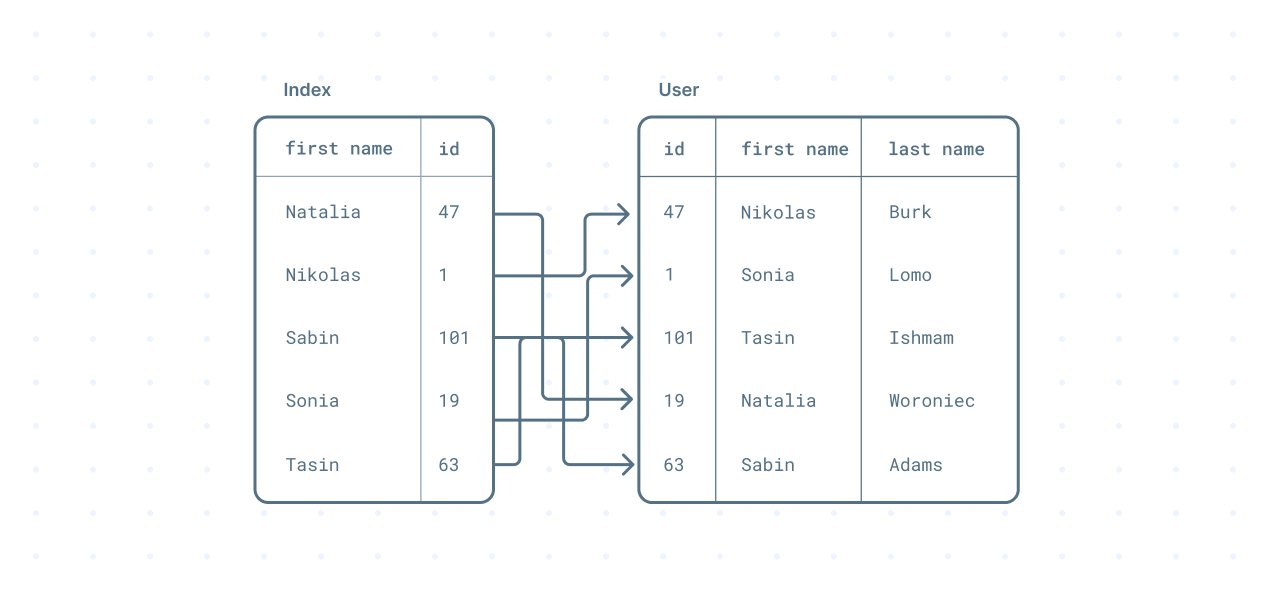
However, the data structures used to define an index are more sophisticated, making them as fast as they are.
The default data structures used when defining an index is the B-Tree. B-trees are self-balancing tree data structures that maintain sorted data. Every update to the tree (an insert, update, or delete) rebalances the tree. This Fullstack Academy video that provides a great conceptual overview of the B-tree data structure.
In a database context, every write to an indexed column updates the associated index.
The time complexity of a B-tree
A sequential scan has a linear time complexity (O(n)). This means the time taken to retrieve a record has a linear relationship to the number of records you have.
If you're unfamiliar with the concept of Big O notation, take a look at What is Big O notation.
B-trees, on the other hand, have a logarithmic time complexity (O log(n)). It means that as your data grows in size, the cost of retrieving a record grows at a significantly slower rate.
Database providers, such as PostgreSQL and MySQL, have different implementations of the B-tree which are a little more intricate.
When to use a B-tree index
B-tree indexes work with equality (=) or range comparison (<, <=,>, >=) operators. This means that if you're using any of the operators when querying your data, a B-tree index would be the right choice.
In some special situations, the database can utilize a B-tree index using string comparison operators such as LIKE.
Working with indexes using Prisma
With the theory out of the way, let's take a look at a concrete example. We'll examine an example query that's relatively slow and improve its performance with an index using Prisma.
Prerequisites
Assumed knowledge
To follow along, the following knowledge will be assumed:
- Some familiarity with JavaScript/TypeScript
- Some experience working with REST APIs
- A basic understanding of working with Git
Development environment
You will also be expected to have the following tools set up in your development environment:
- Node.js
- Git
- Docker or MySQL
- Prisma VS Code extension (optional): intellisense and syntax highlighting for Prisma
- REST Client VS Code extension (optional): sending HTTP requests on VS Code
Note:
If you don't have Docker or MySQL installed, you can set up a free database on Railway.
This tutorial uses MySQL on Docker because it allows disabling query caching. This option setting is only used to showcase the speed of a database query without the database cache getting in the way. You can find this option under the
commandproperty in thedocker-compose.ymlfile.
Clone the repository and install dependencies
Navigate to your directory of choice and clone the repository:
git clone git@github.com:ruheni/prisma-indexes.gitChange the directory to the cloned repository and install dependencies:
cd prisma-indexes
npm installNext, rename the .env.example file to .env.
mv .env.example .envren .env.example .envProject walkthrough
The sample project is a minimal REST API built with TypeScript and Fastify.
The project contains the following file structure:
prisma-indexes
├── .github/workflows
│ │ └── test.yaml
│ └── renovate.json
├── node_modules
├── prisma
│ ├── migrations/
│ ├── schema.prisma
│ └── seed.ts
├── src
│ └── index.ts
├── README.md
├── .env
├── .gitignore
├── docker-compose.yml
├── package-lock.json
├── package.json
├── requests.http
└── tsconfig.jsonThe notable files and directories for this project are:
- The
prismafolder containing:- The
schema.prismafile that defines the database schema - The
migrationsdirectory that contains the database migrations history - The
seed.tsfile that contains a script to seed your development database
- The
- The
srcdirectory:- The
index.tsfile defines a REST API using Fastify. It contains one endpoint called/usersand accepts one optional query parameter —firstName
- The
- The
docker-compose.ymlfile defining the MySQL database docker image - The
.envfile containing your database connection string
The application contains a single model in the Prisma schema called User with the following fields:
// prisma/schema.prisma
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String
}The src/index.ts file contains primitive logging middleware to measure the time taken by a Prisma query:
// src/index.ts
prisma.$use(async (params, next) => {
const before = Date.now()
const result = await next(params)
const after = Date.now()
logger.info(`Query took ${after - before}ms`)
return result
})You can use the logged data to determine which Prisma queries are slow. You can use the logs to gauge queries that could require some performance improvements.
src/index.ts also logs Prisma query events and parameters to the terminal. The query event and parameters contains the SQL query and parameters that Prisma executes against your database.
const prisma = new PrismaClient({
log: [{ emit: "event", level: "query", },],
})
prisma.$on("query", async (e) => {
logger.info(`Query: ${e.query}`)
logger.info(`Params: ${e.params}`)
});The SQL queries (with filled in parameters) can be copied and prefixed with EXPLAIN to view the query plan the database will provide.
Create and seed the database
Start up the MySQL database with docker:
docker-compose up -dNext, apply the existing database migration in prisma/migrations:
npx prisma migrate devThe above command will:
- Create a new database called
users-db(inferred from the connection string defined in the.envfile) - Create a
Usertable as defined by the model inprisma/schema.prisma. - Trigger the seeding script defined in
package.json. The seeding step is triggered because it's run against a new database.
The seed file in prisma/seed.ts file will populate the database with half a million user records.
Start up the application server:
npm run devMake an API request
The cloned repository contains a requests.http file that contains sample requests to http://localhost:3000/users that can be used by the installed REST Client VS Code extension. The requests contain different firstName query parameters.
Ensure you've installed the REST Client VS Code extension for this step.
You can also use other API testing tools such as Postman, Insomnia or your preferred tool of choice.
Click the Send Request button right above the request to make the request.
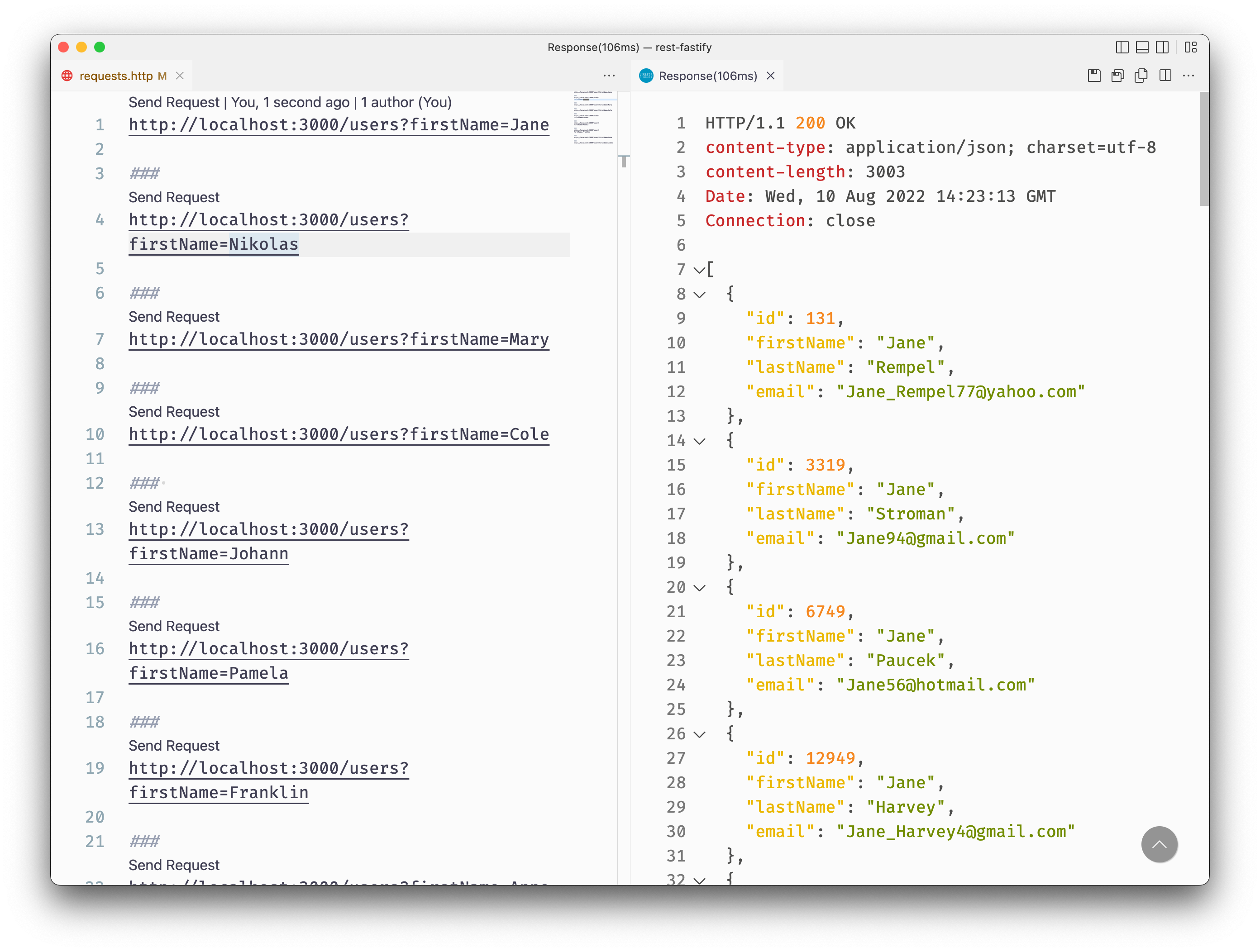
VS Code will open an editor tab on the right side of the window with the responses.
You should also see information logged on the terminal.
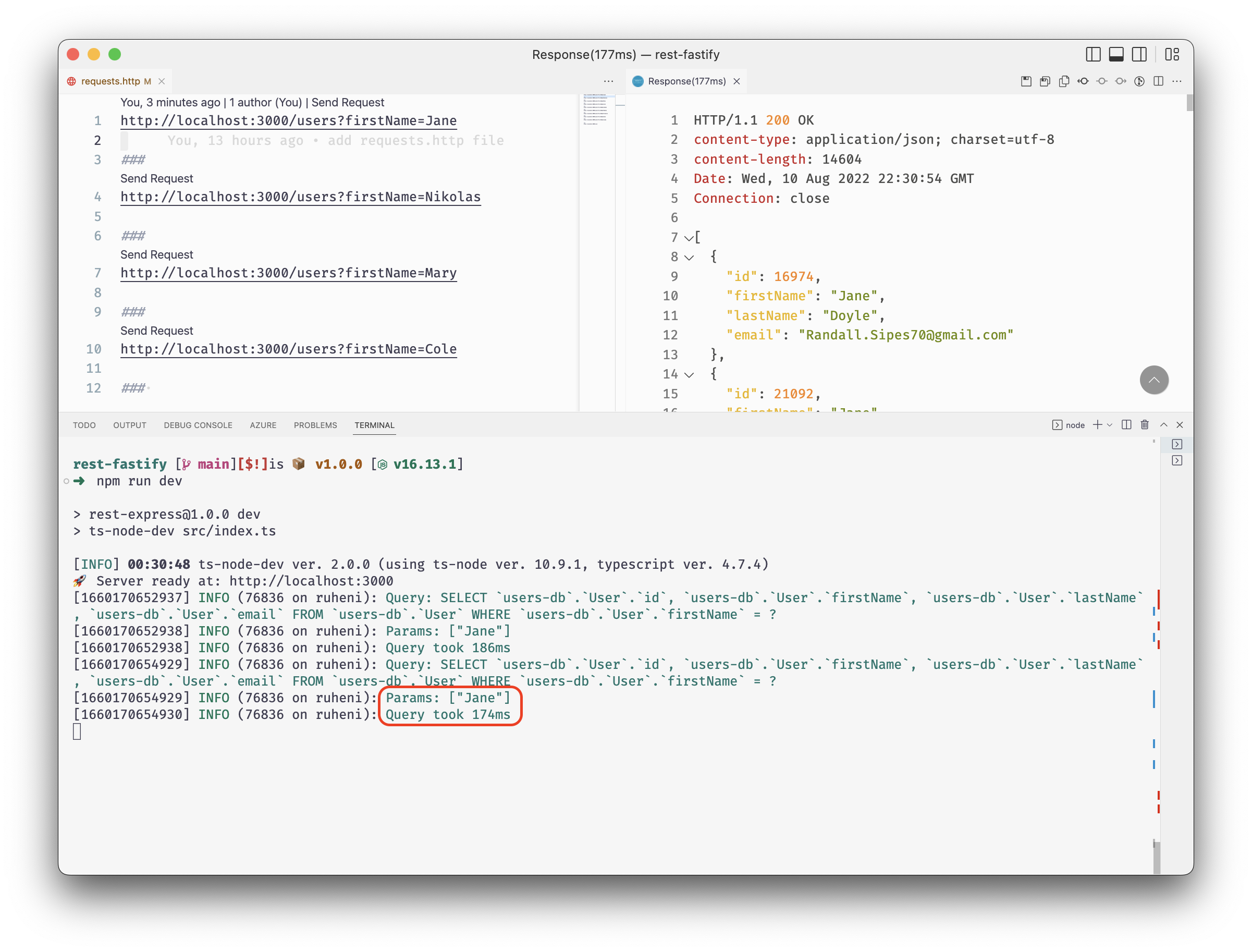
In the screenshot above, the query took 174ms to be executed. The sample data 174ms might not sound like much because the existing dataset is fairly small — roughly 31 MB.
The queries currently have a linear time complexity. If you increase the data set's size, the response time will also increase.
Improve query performance with an index
You can add an index to a field in the Prisma schema using the @@index() attribute function. @@index() accepts multiple arguments such as:
fields: a list of fields to be indexedmap: the name of the index created in the database
@@index supports more arguments. You can learn more in the Prisma Schema API Reference.
Update the User model by adding an index to the firstName field:
diff
// prisma/schema.prisma
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String
+ @@index(fields: [firstName])
}After making the change, create and run another migration to update the database schema with the index:
npx prisma migrate dev --name add-indexNext, navigate to the requests.http file again and send the requests to /users.
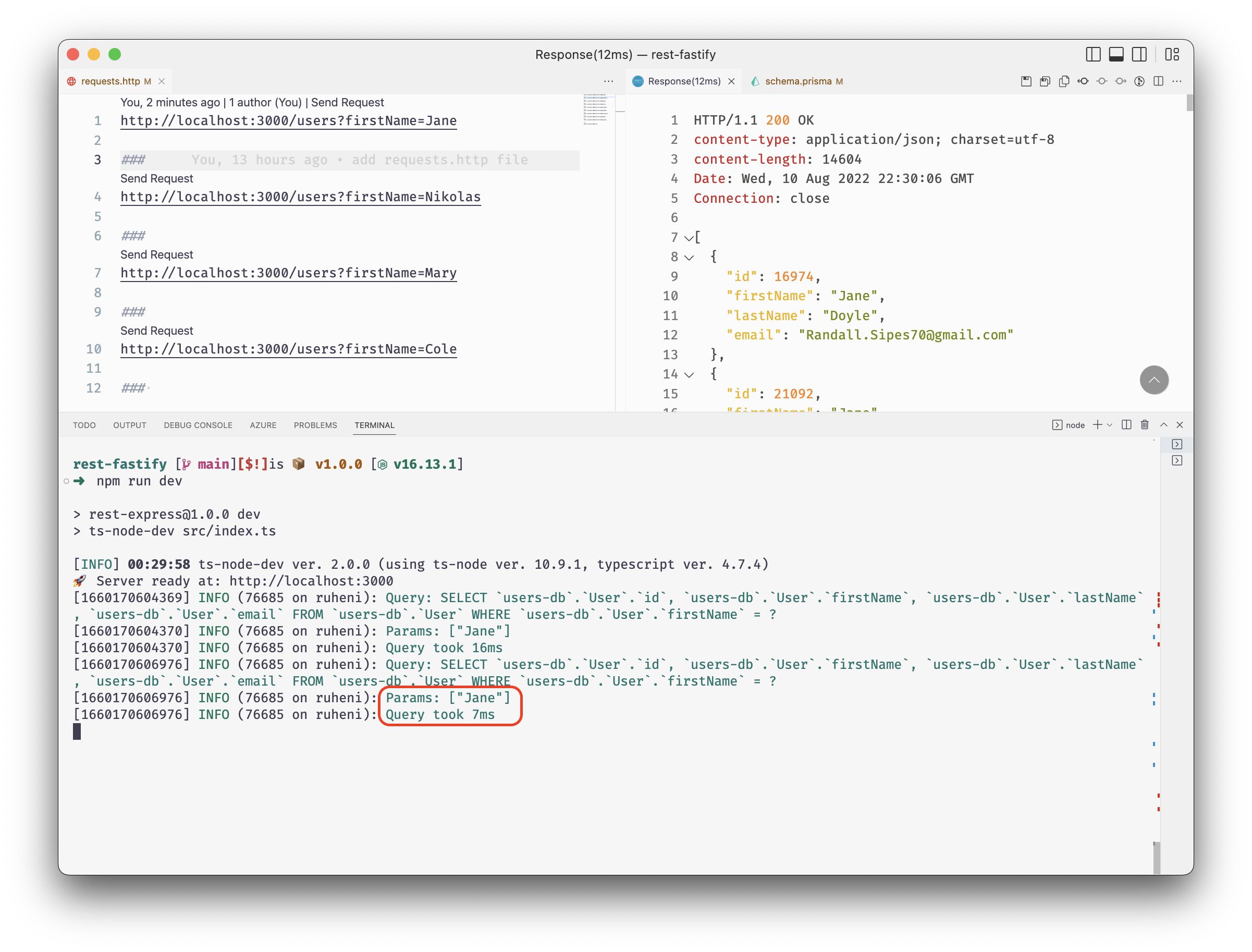
You will notice a significant improvement in response times. In my case, the response time was cut down to 8ms.
Your queries now have a logarithmic time complexity and search time is more scalable than it initially was.
Bonus: Add an index to multiple fields
You can also add an index on multiple columns. Update the fields argument by adding the lastName field.
diff
// prisma/schema.prisma
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String
+ @@index(fields: [firstName, lastName])
}Run a migration to apply the index in the database:
npx prisma migrate dev --name add-lastname-to-indexYou can take this a step further by sorting the firstName column in the index in descending order.
diff
// prisma/schema.prisma
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String
+ @@index(fields: [firstName(sort: "Desc"), lastName])
}Re-run a migration to apply the sort order to the index:
npx prisma migrate dev --name add-sort-orderSummary and next steps
In this part, you learned what the structure of indexes look like, and significantly improved a query's response time by merely adding an index to the field.
You also learned how you can add indexes to multiple columns, and how to define the indexes sort order.
In the next article, you will learn how to work with Hash indexes in your application using Prisma.
Build your next app with Prisma
Start free. Scale when you’re ready.