Improving Query Performance with Indexes using Prisma: Hash Indexes

A hash index is a PostgreSQL index type built for one job: equality lookups. It maps each value to a bucket with a hash function, so the database can jump straight to the matching rows for = comparisons. In this article you will see how hash indexes work, when to choose one over the default B-tree, and then measure the effect directly: an equality query over 500,000 rows drops from roughly 64ms to under 2ms after adding @@index(type: Hash) to a Prisma ORM schema. Every command and number in this walkthrough was verified on Prisma ORM 7.8 and PostgreSQL 17.
Updated (July 2026): Fully revised for Prisma ORM 7: the walkthrough now uses the
prisma-clientgenerator, a driver adapter, and a local Prisma Postgres database, and every command and number was re-run end-to-end on Prisma ORM 7.8 and PostgreSQL 17.
Introduction
In this part of the series, you will learn what hash indexes are, how they work, and when to use them, and then dive into a concrete example of how you can improve the performance of a query with a hash index using Prisma ORM.
If you want to learn more about the fundamentals of database indexes, check out the first part. Part two covers B-tree indexes and builds the project this article continues from.
Hash tables: the data structure that powers hash indexes
Hash indexes use the hash table data structure. Hash tables (also known as hash maps) allow fast data retrieval in almost constant time (O(1)), meaning the retrieval time of a record won't be affected by the size of the data being searched. (Big O notation describes how an algorithm's cost grows with input size; O(1) means the cost stays flat.)
PostgreSQL's hash index is composed of "buckets" or "slots" into which index entries are placed.
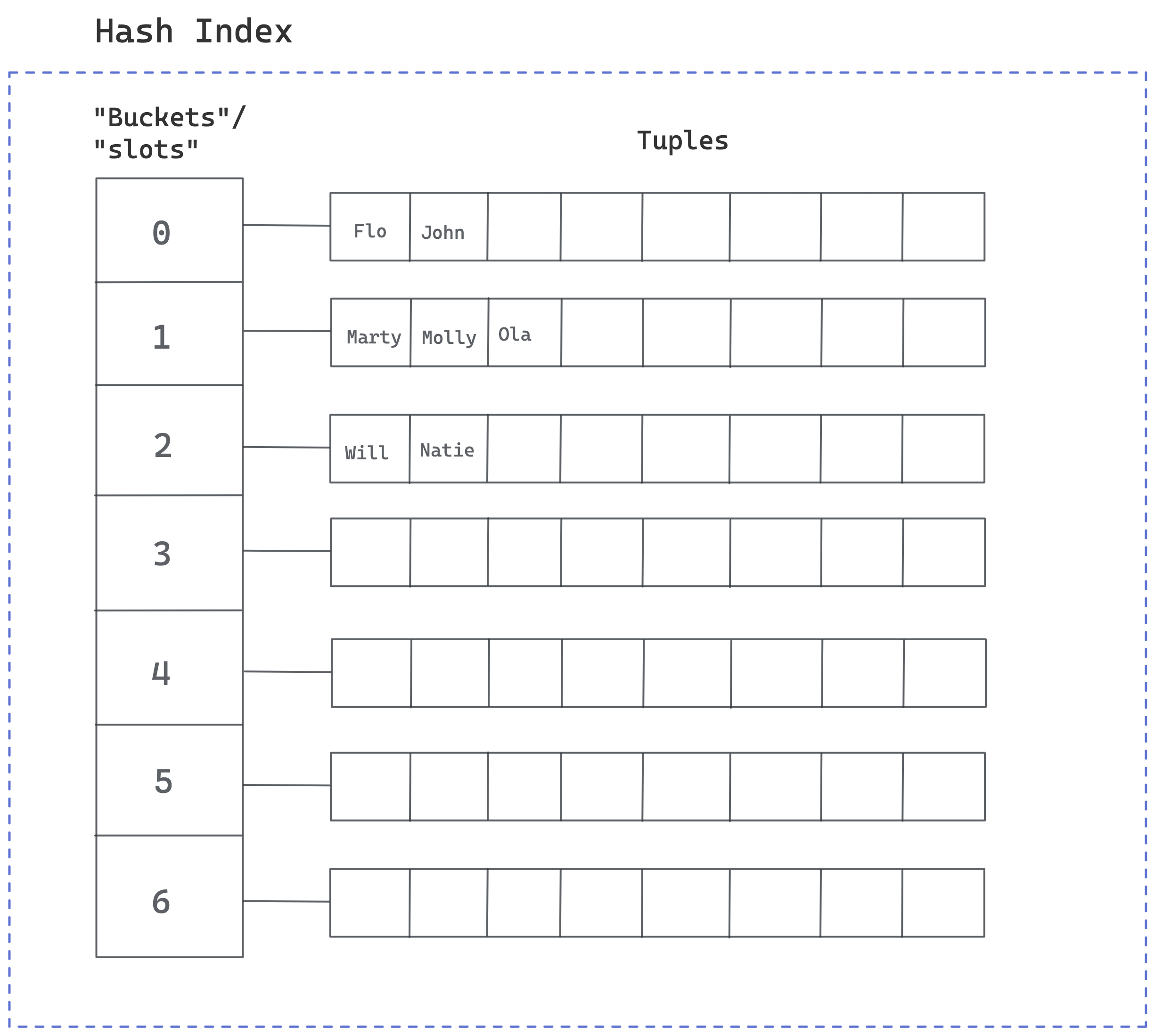
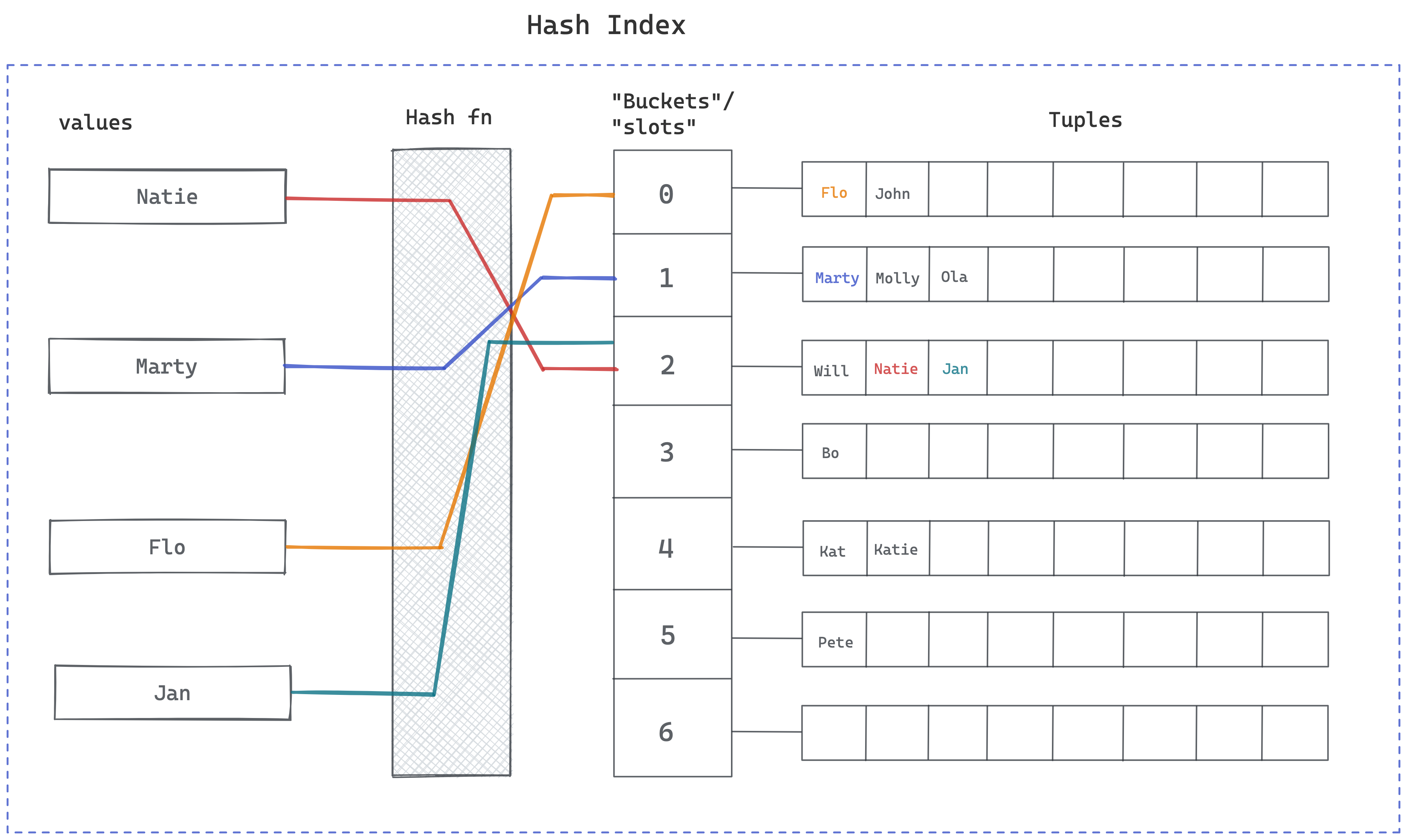
PostgreSQL uses a hash function when storing a value to the index:
- The hash function maps the indexed value to a 32-bit integer, the hash code.
- The bucket number is derived from that hash code, and the index entry is stored in that bucket.
Hash function: a function that maps data of arbitrary size to fixed-size values.
Hash code: the output of a hash function.
When retrieving a record using a hash index, the database applies the hash function to the value to determine the bucket that might contain the value. After determining the bucket, the database searches the bucket's entries to find the records that match your query.
If you're interested in reading about PostgreSQL's implementation of the hash index, you can read further here.
When to use a hash index
Hash indexes only work with the equality (=) operator. They are a solid choice when your queries filter a column exclusively with =, for example:
SELECT * FROM "User" WHERE "lastName" = 'Wick';If you intend to use range operators (<, <=,>, >=) when filtering your data, use a B-tree index instead. You can refer to part 2 to learn more about B-tree indexes.
While a hash index might be a good choice for speeding up equality queries, it comes with some limitations. Hash indexes:
- Cannot be used to index multiple columns
- Cannot be used to create sorted indexes
- Cannot be used to enforce unique constraints
How to add a hash index with Prisma ORM
With the theory out of the way, let's measure a hash index against real data.
Set up the project
This walkthrough continues from the project built in part two: a small Prisma ORM 7 project with a User model, a local Prisma Postgres database started with npx prisma dev, 500,000 seeded users, and a src/measure.ts script that times queries with a client extension and prints the query plan with EXPLAIN ANALYZE. If you haven't built it, follow the setup sections in part two; it takes about five minutes.
The User model, including the B-tree index on firstName from part two, looks like this:
// prisma/schema.prisma
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String
@@index([firstName])
}Measure the slow query
This time you will query by lastName, which has no index. Point the measurement script at it (or adapt src/measure.ts from part two by replacing firstName with lastName):
// src/measure.ts (excerpt)
const sample = await prisma.user.findFirst({ select: { lastName: true } })
const name = sample!.lastName
const users = await prisma.user.findMany({ where: { lastName: name } })
const plan = await prisma.$queryRawUnsafe<{ 'QUERY PLAN': string }[]>(
`EXPLAIN ANALYZE SELECT * FROM "User" WHERE "lastName" = '${name.replace(/'/g, "''")}'`
)Run it with npx tsx src/measure.ts. Here is the output from our run (your name and exact numbers will differ):
User.findFirst took 86ms
Searching for lastName = Wolff
User.findMany took 149ms
matches: 962
User.findMany took 80ms
User.findMany took 76ms
--- EXPLAIN ANALYZE ---
Seq Scan on "User" (cost=0.00..8378.01 rows=1476 width=100) (actual time=0.039..63.396 rows=962 loops=1)
Filter: ("lastName" = 'Wolff'::text)
Rows Removed by Filter: 499038
Planning Time: 0.127 ms
Execution Time: 64.149 msPostgres scans all 500,000 rows and discards 499,038 of them to find 962 matches. Note that the B-tree index on firstName does not help here: an index only serves queries that filter on its own columns.
Improve query performance with a hash index
You can define a hash index in your Prisma schema using the @@index() attribute with two arguments:
fields: the list of fields to be indexedtype: the index access method the database should use,Hashin this case (the default isBTree)
The @@index attribute supports more arguments you can learn more about in the Prisma Schema API Reference.
Add a hash index on the lastName field:
// prisma/schema.prisma
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String
@@index([firstName])
@@index([lastName], type: Hash)
}Like the B-tree index in part two, the hash index is declared in your schema, so it ships as code and applies identically in every environment. Apply the change:
npx prisma db pushBehind the scenes, Postgres now has a hash index (you can confirm it by querying pg_indexes):
CREATE INDEX "User_lastName_idx" ON public."User" USING hash ("lastName");Run the measurement script again:
User.findFirst took 82ms
Searching for lastName = Wolff
User.findMany took 36ms
matches: 962
User.findMany took 19ms
User.findMany took 14ms
--- EXPLAIN ANALYZE ---
Bitmap Heap Scan on "User" (cost=75.38..4159.41 rows=2500 width=100) (actual time=0.268..1.298 rows=962 loops=1)
Recheck Cond: ("lastName" = 'Wolff'::text)
Heap Blocks: exact=872
-> Bitmap Index Scan on "User_lastName_idx" (cost=0.00..74.75 rows=2500 width=0) (actual time=0.121..0.121 rows=962 loops=1)
Index Cond: ("lastName" = 'Wolff'::text)
Planning Time: 0.115 ms
Execution Time: 1.567 msThe sequential scan is gone. Postgres uses the hash index to locate the matching rows directly, and execution time drops from 64.1ms to 1.6ms, roughly a 41x improvement. At the application level, the findMany call returning all 962 matching rows settles around 14 to 19ms instead of 76 to 80ms.
Congratulations! 🎉
You've learned how to reduce your database queries' response times using a hash index.
Frequently asked questions
Summary and next steps
In this part, you learned what hash indexes are, their internal structure and limitations, and how to define and use a hash index using Prisma ORM: from a 64.1ms sequential scan over 500,000 rows to a 1.6ms lookup, verified with EXPLAIN ANALYZE.
The same workflow carries to production: npx prisma init --db provisions a managed Prisma Postgres database, and the indexes you declared in your schema apply there exactly as they did locally.
If you would like to learn about the fundamentals of database indexes and B-tree indexes, refer to part 1 and part 2.
Build your next app with Prisma
Start free. Scale when you’re ready.