Overcoming Database Challenges in Serverless & Edge Applications

Adapting data-driven applications to Serverless and Edge deployments can be trickier than it seems. In this article, we'll take an in-depth look at common challenges and potential solutions for developers who deploy their applications to ephemeral environments.
Table of contents
A note on terminology
We’ll be talking a lot about “serverless” and “deploying at the edge” a lot. While the definition of these is not set in stone, we have a great primer on these technologies and how we view them at Prisma.
In short, “serverless” will be shorthand for a stateless, Function-as-a-Service offering while “edge” will refer to any means by which a developer can locate business logic closer to end users.
Serverless deployments and you
Function-as-a-Service (FaaS) offerings have become an increasingly popular way to deploy data-driven workloads. Serverless deployments offer increased scaling and reduced costs while not requiring many changes in a developer's day to day.
This being said, while serverless deployments offer compelling benefits, they also come with specific challenges. When a connection to a persistent data store is required, you may find some difficulties in introducing stateful behaviors to your stateless environment.
Let's dive in and learn how to effectively utilize serverless functions while avoiding common pitfalls.
Common serverless drawbacks
Putting aside differences in underlying runtimes all serverless functions share the same challenge: they are ephemeral deployments. Existing function instances can be shut down at any time, while new instances can be created without any knowledge of previous processing.
This can be very detrimental to a service that requires access to a non-ephemeral data store. For example, consider what would happen if:
- a function is shut down in the middle of a transaction?
- a scaling policy causes ten thousand new functions to connect to the database?
- a long running query (or queries) keeps a function invocation running for far longer than the average?
When developing an application for a serverless environments it's always important to assume that these kind of issues can and will happen.
Avoiding serverless headaches
To show how issues may come up, let's see a simple example. The following AWS Lambda is a simple Node.js handler that accepts an ID, queries a database for an item with that ID, and then returns the resulting object.
import { Handler } from 'aws-lambda';
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
export const handler: Handler = async (event) => {
const itemId: string = event.itemId ?? '0';
return await prisma.item.findUnique({
where: {
id: itemId,
},
});
};In a non-serverless environment this function wouldn't have any performance implications, but in a serverless environment this function could cause serious harm to your application (and your wallet!) without some protections.
For example, if this app saw a massive increase in usage you could see your database quickly run out of connections. This could lead to slower response times and timeouts which could slow your effective processing rate to a crawl.
To avoid this parallelization issue, let's look at three easy configuration changes you could make to your application. These changes are ordered from least impactful/least difficult to most impactful/most difficult.
Change the client connection pool size
Most ORMs, including Prisma, have a way to modify the number of connections that the client keeps open with the underlying database (known as a connection pool). By default, the number of connections in the pool can vary but generally fall between two and ten connections.
If you refer to our example above, even accounting for a large number of connections could be off by an order of magnitude if each function keeps ten connections open!
In most cases, setting the pool size to a maximum of 1 will keep your app running while also guaranteeing that the number of connections coming from your functions will never exceed the number of concurrently running functions. If you’re still seeing database connections run amok, you should ...
Set concurrency limits
Most cloud platforms have the ability to limit the amount of concurrency your serverless functions have. This gives you protection at the infrastructure level on how parallelizable your work can be. Now that you've set the connection pool size for each function invocation, the concurrency limit will allow you to plan for a specific number of open connections with your data store!
Most cloud providers recommend starting with a low concurrency (say five to ten) and then increasing to handle additional peak load. With these settings, you'll now have an idea of a minimum and maximum number of connections open and guarantees that you won't go beyond those values. For AWS Lambda, be sure to check out the docs for reserved concurrency to learn more about this configuration.
However, as your application grows in popularity you may find that your bottleneck is still connections to your database, especially if other parts of your environment also rely on it. In these cases, it may become necessary to pool connections to the database through a proxy.
Pool database connections
Thankfully, connection pooling works with serverless functions in the same way it works for other applications! PgBouncer is a simple option for PostgreSQL databases. You can configure PgBouncer to connect to your database, change applications to connect to your PgBouncer instance instead of your database, and connections will be pooled!
Further configuration can then be done between PgBouncer and your database which has the added benefit of keeping your serverless functions stateless and focused on serving business logic.
Options also exist for other database engines, like ProxySQL for MySQL. Additionally, managed solutions like Prisma Data Plaform give you the ability to bring your own database and add additional features on top of it.
Note: Some ORMs and database proxies are not compatible. Be sure to check the documentation for your libraries to determine which option is right for you.
Bring your compute to the edge
Now that your serverless functions are protected against out of control scaling, let's take a look at computing at the edge!
First and foremost, while edge environments and serverless deployments can exist without one another, for the sake of this article will we be specifically looking at the overlap between edge and serverless. Some of these tips will be useful in any edge context, while others will only be relevant to FaaS offerings.
To best optimize our edge-based workloads, we will take the lessons learned from serverless computing and add onto them. The benefit with deploying serverless functions globally is that your end users, regardless of where they are located, have the opportunity for their requests to be handled in data centers close to them! For example, a user in Japan can have their request for a web page processed in Tokyo, rather than Los Angeles.
On top of this, it's probable that you've already had some exposure to edge computing, albeit in a limited way. Content Delivery Networks (CDNs) are a way of caching content in various data centers. Edge computing is taking that thought and applying it to business logic.
Edge computing considerations
Assuming you've taken scaling considerations to heart, you might be wondering what other challenges may exist for these new edge deployments?
For some applications, there are no additional challenges! Static sites, for example, are an excellent use case for edge functions. Your pages can be generated at build or deploy time and then be served at the edge, decreasing latency and increasing reliability.
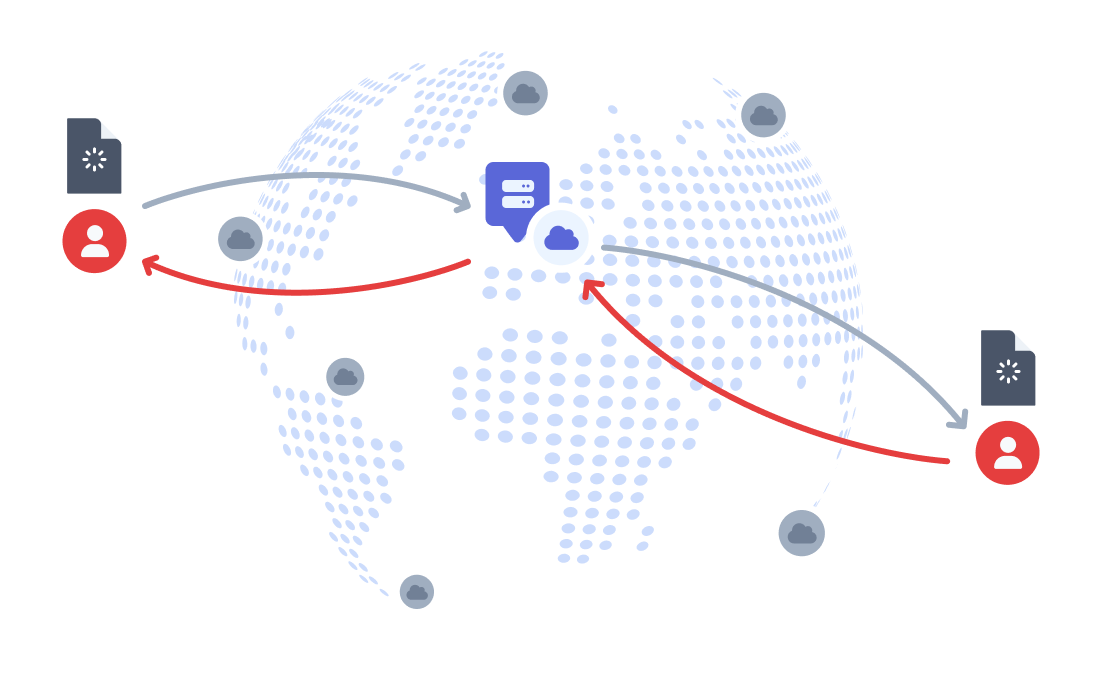
For data-driven apps, however, there's a somewhat obvious flaw: if your business logic is at the edge, it still needs to communicate with your centrally located database.
In some cases, you could still see latency improvements, but the majority of your latency would be pushed from connections between the client and business logic, to connections between business logic and data store.
In worst-case scenarios, you could have business logic in a different region attempting to access your database, making your latency problem even worse!
This is compounded by limitations that exist within edge functions themselves. Since the goal of edge computing is distributing a large amount of compute globally, some trade-offs are necessary to guarantee performance. In most cases the considerations boil down to:
- Code must be ran in a true isolated environment.
- Code must abide by more restrictive resource limitations.
- Code may not have access to the full suite of Node APIs (e.g.
fs,eval,fetch). - Code may not open stateful connections (TCP) or may only have a set number of connections open.
Edge computing solutions
Luckily, the edge computing ecosystem is growing quickly. Companies like Vercel and Netlify have edge solutions and in turn have multiple solutions for applications backed by data stores. Unlike the serverless solutions above, these solutions can be very complex and depend heavily on your specific implementation. Be sure to assess each option carefully to fit your needs.
Proxy connections via HTTP
While not ideal, adding an additional proxy layer between your business logic and database can help keep your existing infrastructure while changing as little as possible. In this case, you can use an option similar to the ones discussed in connection pooling above.
Amazon RDS Proxy and Prisma Accelerate are two options that are more "plug and play" in nature. With a bit more effort, there are some drivers that utilize websockets in order to connect from an application to a database via a proxy.
One problem that can fall out of this approach is that your functions and database should be as close together as possible. This somewhat defeats the purpose of edge functions, but implementations like Vercel Edge Functions offer ways to specify a region for your deployment. At some point you will find that as your app becomes more and more popular, replicating data across regions may be a prudent decision.
Move to a global datastore
In cases where data is being accessed world-wide, at least one global datastore is critical for good performance. Luckily, there are already a number of good solutions with many more on the way! Cloud providers like AWS have options for their products, like DynamoDB Global Tables and Aurora global databases, but there are also database-specific companies that offer multi-region capabilities!
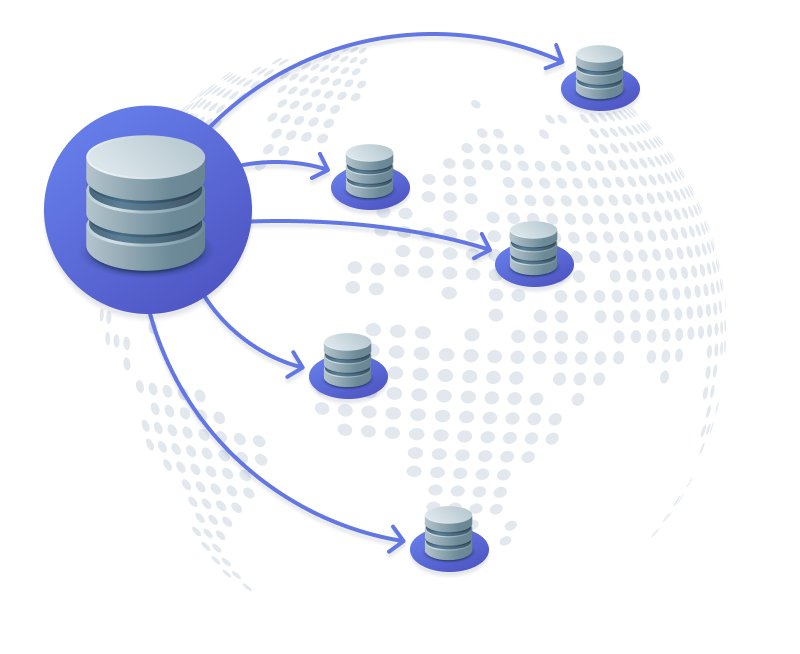
Companies like Cockroach Labs and Fauna are great options for taking your data and replicating it through multiple regions to increase your performance. However, you should still be aware of tradeoffs, as data will need to eventually become consistent or replicated across all regions. This could be handled asynchronously, which could lead to stale data in some regions, or synchronously, where read operations will be lightning fast, but writes may still experience increased latency. After exhausting all previous options, your team will need to dive deeper into your needs and understand where data is needed.
Consider "edge-first" options
Instead of globally replicating all data, it may be necessary to move your data to different data stores depending on where it is used. In the case of configuration data related to the functions themselves, an option like Vercel Edge Config distributes configuration along with your functions leading to significantly reduced read times.
Note: Prisma also offers Accelerate, a global database cache that could assist in colocating data with your business logic!
Co-located configuration, when combined with a globally accessible database (and additional regional specific databases) leads to serverless, edge deployed solution that nets many benefits for your end users while mitigating issues surrounding scale and round trip time.
Wrapping up
When it comes to serverless and edge, there are many clear benefits. Reduced infrastructure costs, increased scalability, increased availability... these environments are worth exploring. However, if it was just that easy then all applications would already be both serverless and ran on the edge.
While applications without a backing data store can be transitioned without too much effort, applications that require a database connection will require a bit more attention to be deployed effectively.
At the end of the day, edge and serverless computing are more tools in a software engineer's tool belt. As an engineering organization you must first understand the work necessary to move your stateful application to a stateless environment. In some cases, it might not be the right move! In other cases, these deployment strategies are an excellent choice and you can get great benefits while expending a little extra time to make sure that your application is serverless-ready.
Note: At Prisma, we're excited about the new paradigms of serverless and edge deployments! To learn what we're building to make it easier for developers to build data-driven applications in these new environments, check out Accelerate and Prisma Postgres and follow us on X/Twitter.
Keep reading

How to Make Your Docs Agent-Ready
Coding agents fail silently on truncated indexes, broken links, and missing metadata. What we fixed in the Prisma docs, and how to audit yours.


Ship risky schema changes with per-branch databases
Prisma Compute gives every branch its own Prisma Postgres database. Rehearse expand-and-contract migrations in isolation before they touch production.

Build your next app with Prisma
Start free. Scale when you’re ready.