
April 21, 2023
How We Sped Up Serverless Cold Starts with Prisma by 9x


Cold starts are a huge roadblock for a fast user experience with serverless applications — but also inherently unavoidable. Let's explore what contributes to cold starts and how we made every serverless app built using Prisma ORM even faster.

Table of contents
- Enabling developers to reap the benefits of Serverless & Edge
- The dreaded cold start 🥶
- How Prisma contributes to a cold start
- Improved startup performance by 9x
- Aside: Findings about TLS
- This is just the beginning
- You can help!
Enabling developers to reap the benefits of Serverless & Edge
At Prisma, we're huge believers in the premise of serverless and edge applications! These deployment paradigms have great benefits and allow developers to deploy their applications in more scalable and less costly ways. Serverless providers such as Vercel (with Next.js API routes) or AWS Lambda are great examples of this.
However, these paradigms also come with new challenges — especially when working with data!
That's why in the past months, we've increased our focus on these deployment paradigms to help developers build data-driven applications while taking advantage and reaping the benefits of serverless and edge technologies.
We are tackling this from two angles:
- Building products that solve the new challenges that come with these ecosystems (such as Accelerate, a globally distributed database cache)
- Improving the experience with Prisma ORM in serverless and edge environments
This article is about how we've improved one of the major issues developers face when building data-driven applications in serverless environments: Cold starts when using Prisma ORM.
The dreaded cold start 🥶
One of the most frequent performance issues when working in a serverless environment is long cold starts. But what is a cold start?
Unfortunately, this term carries a lot of ambiguity and is often misunderstood. Generally though, it describes the time it takes for a serverless function's environment to be instantiated and its code to be executed when the function handles its first request. While this is the basic technical explanation, there are a few specific things to keep in mind about cold starts.
They are inherently unavoidable
A cold start is an unavoidable reality when working in a serverless environment. The primary "win" of serverless is that your application can scale up to infinity when traffic increases and down to zero when not in use. Without that capability, serverless would not be... serverless!
If there are no requests for some time, all running environments are shut down — which is great because that also means you incur no costs. But it also means there are no functions left to instantly respond to incoming requests. They have to first be started again, which takes a little bit of time.
They have a real-world impact
Cold starts do not only have technical implications, but also create real-world problems for the businesses deploying serverless functions.
Providing the best experience possible for your users is of the utmost importance and slow startup performance could steer users away.
Peer Richelsen from Cal.com recently turned to Twitter after realizing their application was suffering from long cold starts:
Ultimately, the goal of a developer working in a serverless environment should be to keep their cold start times as short as possible as long cold starts can result in bad experiences for their users.
They are more complex than you might think
Although the above explanation of cold starts is pretty straightforward, it is important to understand that different factors contribute to a cold start. We'll explain in the next couple of sections what actually happens when a serverless function is first spawned and executed.
Note: Keep in mind, this is a general overview of how a serverless function is instantiated and invoked. The specific details of that process may vary depending on your cloud provider and configuration (we mostly use AWS Lambda as a reference).
We are going to use this simple serverless function as an example to explain these steps:
Step 1: Spinning up the environment
When a function receives a request but no instances of it are currently available, your cloud provider initializes the execution environment where it will run your serverless function. Multiple steps happen during this phase:
- The virtual environment is created with the CPU and memory resources you have allocated to your serverless function.
- Your code is downloaded as an archive and extracted into the new environment's file system. (If you're using AWS Lambda, any associated Lambda layers are downloaded as well.)
- The runtime (i.e. the language-specific environment your function runs in) is initialized. If your function is written in JavaScript, this will be the Node.js runtime.
Afterwards, the function is still not ready to process a request. The virtual environment is ready and all of the code is in place, but no code has been processed by the runtime yet. Before the handler can be invoked, the application must be initialized as described in the next step.
Note: These details of the startup of your function are not configurable and are handled by your cloud provider. You don't have much of a say in how this works.
Step 2: Starting the application
Generally, the application code exists in two different scopes:
- Code outside the handler function
- Code inside the handler function
In this step, your cloud provider executes the code that is outside the handler. The code inside the handler will be executed in the next step.
AWS Lambda logs the following when running the function from above:
You can see how the outer console.log("Executed when the application starts up!") is executed even before the actual START RequestId is logged by AWS Lambda. If there were any imports, constructor calls or other code - that would also be executed at this time.
(On a warm start request to your function, this line will not be logged any more at all. The code outside the handler is only executed once during a cold start.)
Step 3: Executing application code
In the final part of the startup process, the handler function is executed. It receives the incoming HTTP request (i.e. request headers, body, etc...) and runs the logic you have implemented.
The AWS Lambda log from the previous step continues:
With that, the cold start of your function has concluded and the execution environment is ready to handle further requests.
Aside: AWS Lambda logs the time it took to execute the code inside the handler as
Duration, which occurs in step 3.Init Durationis both the start of the environment and starting the application, so steps 1 and 2.
How Prisma contributes to a cold start
With that understanding of what a cold start is and the steps that are taken to initialize a serverless function, we will now take a look at where Prisma plays a role in that startup time.
-
Prisma Client is a Node.js module that is external to your function's code, and as such requires time and resources to be loaded into the execution environment's memory: The whole function archive needs to be downloaded from some storage, and then extracted into the file system. This is true for all Node.js modules, however it does add to the cold start and increases the more dependencies are used in a project - and Prisma can be one of those.
-
Once the code is loaded into memory, it also has to be imported into your handler's file and must be interpreted by the Node.js interpreter. For Prisma Client, that usually means calling
const { PrismaClient } = require('@prisma/client'). -
When Prisma Client is instantiated with
const prisma = new PrismaClient(), the Prisma Query Engine has to be loaded and generates things such as input types and functions that allow the client to operate correctly. It uses the internal Schema Builder to do this. -
Finally, once the virtual environment is ready to run your function's initial invocation, the handler will begin to execute your code. Any Prisma queries in that code, like
await prisma.user.findMany(), will first initiate a connection to your database if one wasn't already opened by explicitly callingawait prisma.$connect(), and then execute the query and return the data to your application.
With this understanding, we can proceed to explain how we improved Prisma's impact on cold start.
Improved startup performance by 9x
Over the past couple of months, we increased our engineering efforts on addressing these cold start problems and are proud to say we have made magnificent strides 🎉
In general, we have been following the "Make it work, make it right, make it fast" philosophy while building Prisma ORM. After having launched Prisma ORM for production in 2020, adding support for multiple databases and implementing an extensive set of features, we're finally focusing on improving its performance.
To illustrate our progress, consider the graphs below. The first one represents the cold start duration of an app with an comparatively large Prisma schema (with 500 models) before we began our efforts to improve it:
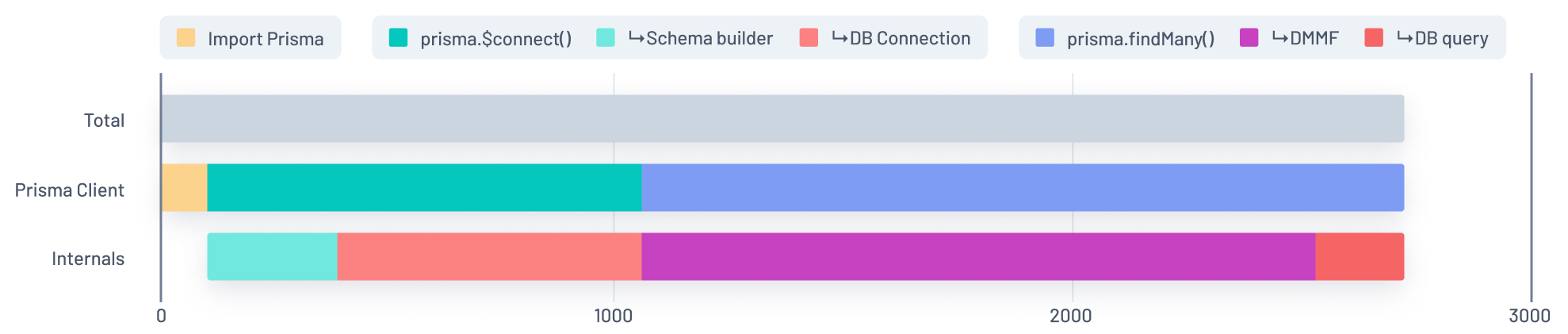 Before
Before
This next graph is a peek at what the numbers currently look like after our recent efforts on performance enhancements:
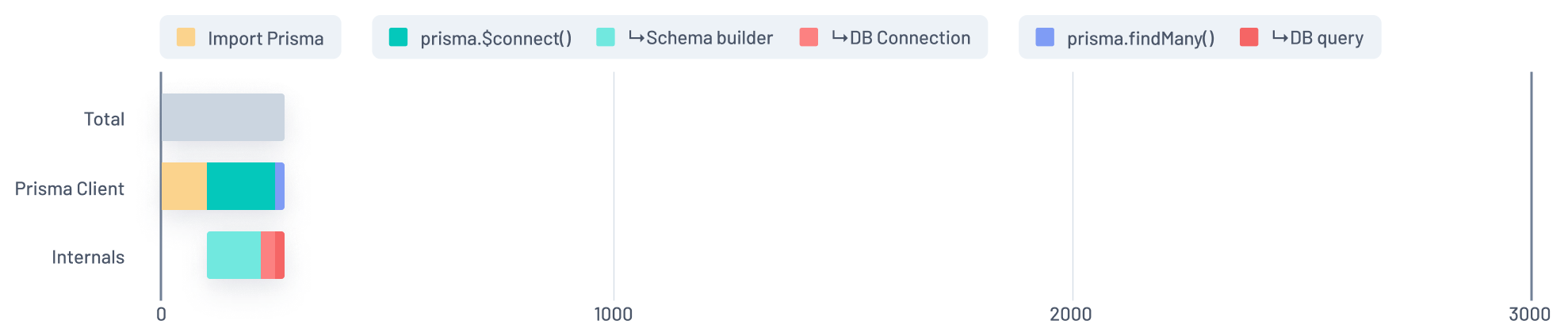 After
After
We won't sugar-coat the situation here, Prisma's startup time used to leave a lot to be desired and people have rightfully called us out for it.
As you can see, we are now left with a much shorter cold start though. The strides forward here came in the form of enhancements to our codebase, findings about how serverless functions behave and applying best practices. The next sections will describe these in more detail.
A new JSON-based wire protocol
The graph below is the same before graph shown above:
Before
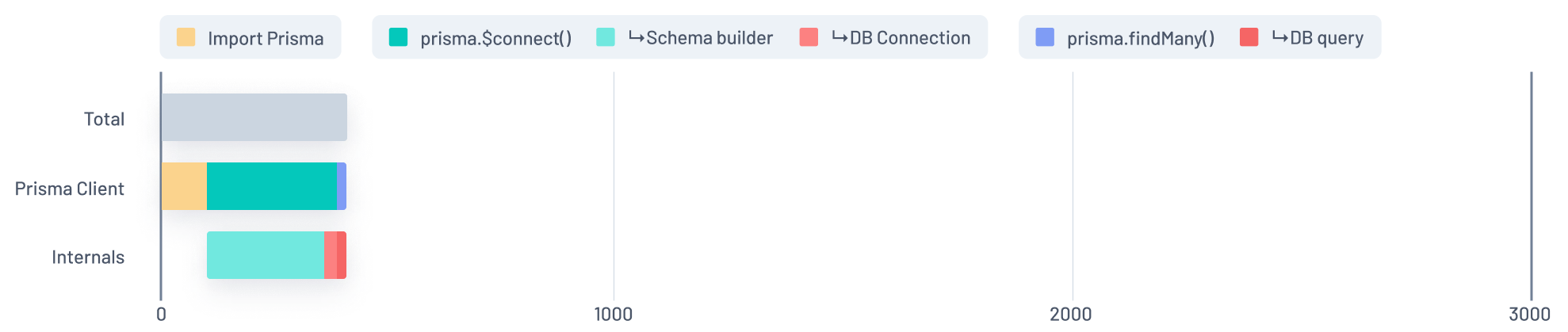
In this graph, the Blue section of the Prisma Client bar represents the time spent running a findMany query during a function's initial invocation. That time is split into two chunks in the Internals bar: Purple and Red.
We quickly realized this graph did not make much sense. The majority of the time taken to run the query was spent... not running the query!
This Purple segment, which accounts for the majority of the findMany query segment, represents the time spent parsing what we call the DMMF (Data Model Meta Format), which is an internal structure used to validate queries that are sent to Prisma's query engine.
The Red segment represents the time spent actually running the query.
The root problem here was that Prisma Client used a GraphQL-like language as a wire protocol to communicate with the query engine. GraphQL comes with a set of limitations that forces the Prisma Client to use the DMMF (which can get in the ballpark of megabytes of JSON) to serialize queries.
If you have been with Prisma for a long time, you might remember that Prisma 1 was a much more GraphQL-focused tool. When rebuilding Prisma as Prisma 2, fully focused on being a plain database ORM, we kept this part of our architecture without questioning it - and without measuring its performance impact.
 Serhii's revelation
Serhii's revelation
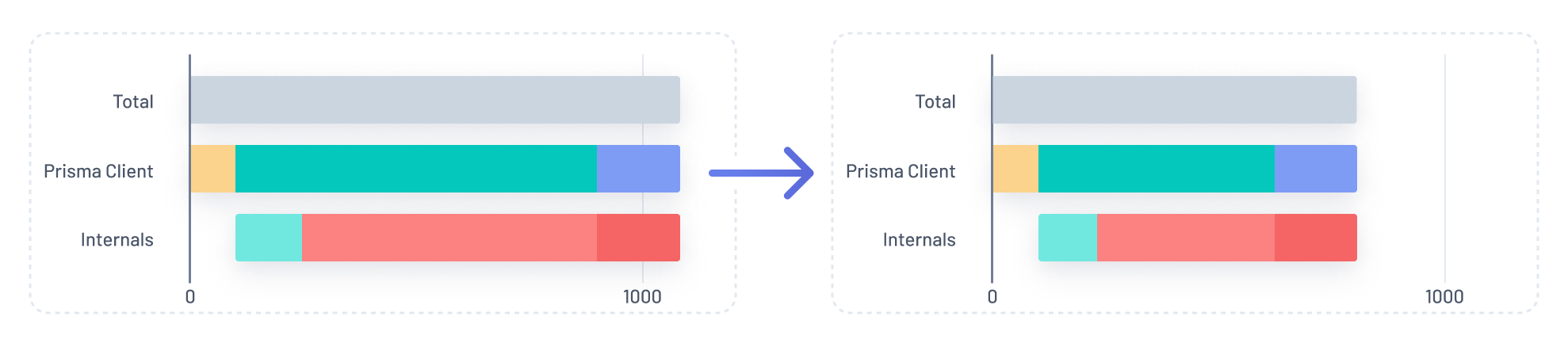
The solution we came up with was to redesign the wire protocol from the ground up in plain JSON, which makes the communication between Prisma Client and the query engine a lot more efficient because it no longer requires the DMMF to serialize messages.
After redesigning the wire protocol, we effectively removed the entire Purple segment from the graph, leaving us with the following:
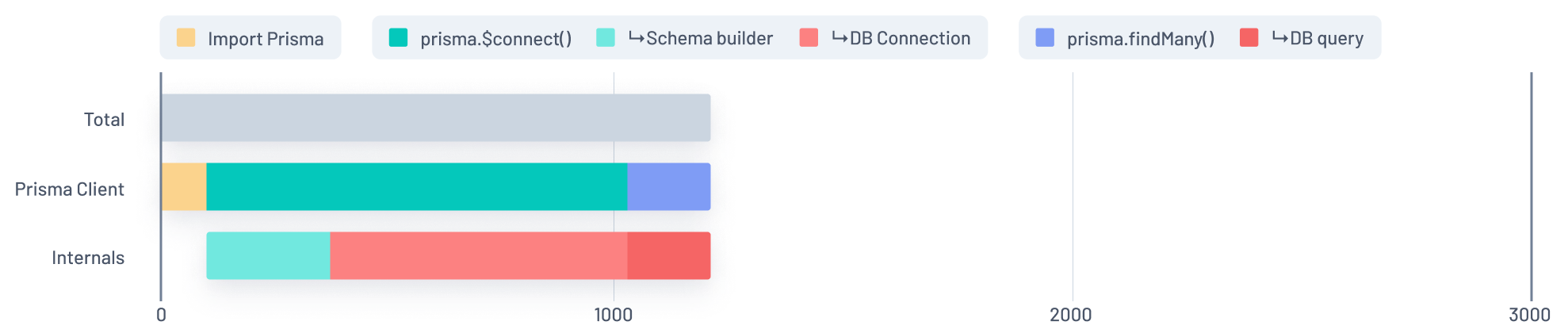 With JSON protocol
With JSON protocol
Note: You can check out pull requests prisma-engines#3624 and prisma#17911 with the actual changes made if you are interested.
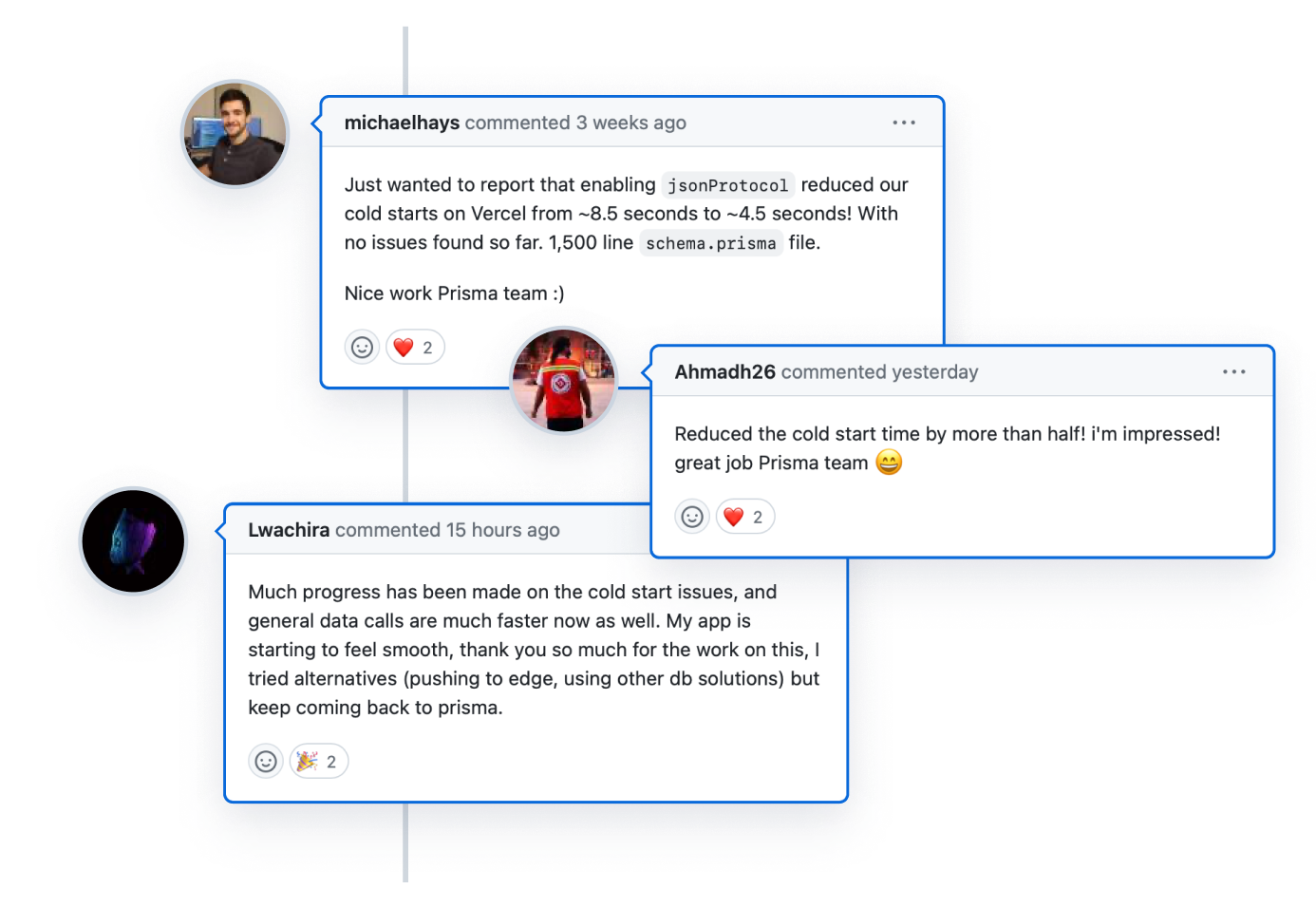
Check out this amazing feedback on GitHub from users who tried out the new JSON-based wire protocol:
Note: The JSON-based wire protocol is currently in Preview. Once it's ready for production, it will become the default for how Prisma Client communicates with the query engine. Please give it a try and submit any feedback to help speed up the process of making this feature generally available.
Host your function in the same region as your database
After our switch to JSON protocol, the big distracting Purple section was gone from the graph and we could focus on the remaining:
With JSON protocol
We clearly noticed the Light Red and Red sections as the next big candidates. These represent the communication with the actual database that Prisma triggers.
Anytime you host an application or function that needs access to a traditional relational database, you will need to initiate a connection to that database. This takes time and comes with latency. The same is true for any query you execute.
The goal is to keep that time and latency to an absolute minimum. The best way to do this at the moment is to ensure your application or function is deployed in the same geographical region as your database server.
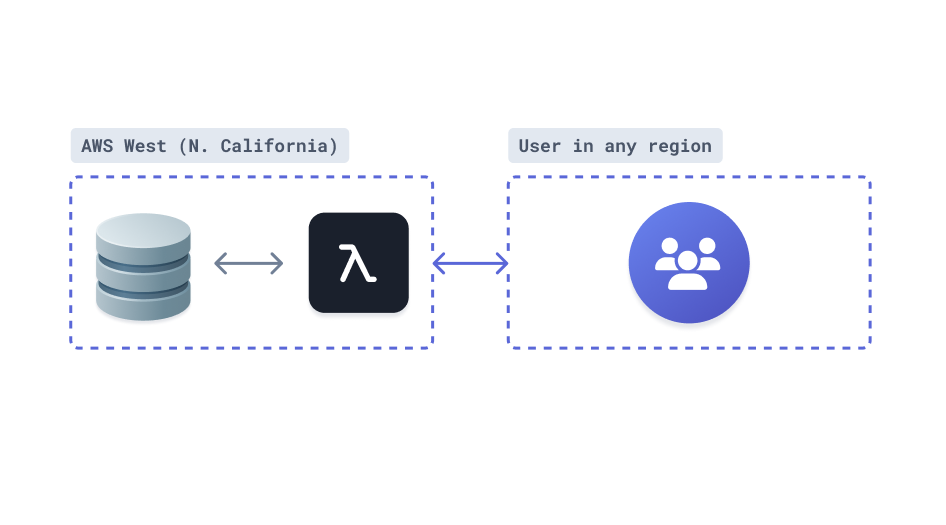
The shorter the distance your request has to travel to reach the database server, the faster that connection will be established. This is a very important thing to keep in mind when deploying serverless applications, as the negative impact that results from not doing this can be significant.
Not doing so can affect the time it takes to:
- Complete a TLS handshake
- Secure a connection with the database
- Execute your queries
All those factors are activated during a cold start, and hence contribute to the impact using a database with Prisma can have on your application's cold start.
We, embarrasingly, noticed that we had done the first few runs of our tests with a serverless function at AWS Lambda in eu-central-1, and a RDS PostgreSQL instance hosted in us-east-1. We quickly fixed that, and the "after" measurement clearly shows the tremendous impact this can have on your database latency, both for the creation of the connection, but also for any query that is executed:
 With database in same region as function
With database in same region as function
Using a database that is not as close as possible to your function will directly increase the duration of your cold start, but also incur the same cost any time a query will be executed later during handling of warm requests.
Optimized internal schema building
In the graph shown previously, you may have noticed that only two of the three segments on the Internals bar are directly related to the database. The other segment, "Schema builder", shown in Teal, is not. This was an indicator to us that this segment was an area for potential improvement:
With database in same region as function
The Green segment of the Prisma Client bar represents the time spent while Prisma Client runs its $connect function to establish a connection with the database. This segment is divided into two chunks in the Internals bar: Teal and Light Red.
The Light Red segment represents the time spent actually creating the database connection and the Teal segment shows the time Prisma's query engine spends reading your Prisma schema, then using it to generate the schema it uses to validate incoming Prisma Client queries.
The way those items were previously generated was not as optimized as they could have been. In order to shorten that segment, we tackled the performance issues we could find there.
More specifically, we found ways to remove an expensive piece of code that transformed the internal Prisma Schema when the query engine was started before building the query schema.
We also now generate the strings for the name of many types in the query schema lazily. That made a measurable difference.
Along with that change, we also found ways to to optimize the code within the Schema Builder to improve memory layout, which lead to significant performance (run time) improvements.
Note: Check out the following example pull requests if you are interested in the specifics about the memory-allocation related fixes we made: #3828, #3823
After applying these changes, the request from before looked like the following:
With Schema Builder enhancements
Notice the Teal segment is significantly shorter. This is a huge win, however there is still a Teal segment there, which means time is being spent doing things that are not related to the database. We have already identified potential enhancements that will bring this segment near to (if not completely down to) zero.
Various small wins
Along the way, we also found many smaller inefficiencies that we were able to improve. There were a lot of these, so we won't go over each one, but a good example is an optimization we made to our platform detection routine used to search for the OpenSSL library on Linux environments (the pull request for that enhancement can be found here).
This enhancement shaves ~10-20ms off the cold start on average. While that doesn't seem like much, the accumulation of this enhancement and other small enhancements we made add up to another good chunk of saved time.
Aside: Findings about TLS
Another finding we had during this initiative that is worth noting is that adding security to your database connection via TLS can have a lot of impact on the cold start time when your database is hosted in a different region than your serverless function.
A TLS handshake requires a round trip to and from your database. This is extremely fast when your database is hosted in the same region as your function, but can be very slow if they are far apart.
Prisma Client enables TLS by default, as it is the more secure way to connect to your database. Because of this, some developers whose databases are not in the same region as their function may find an increased cold start time caused by that TLS handshake.
The graph below shows the different cold start times with TLS enabled (first) and disabled (via setting sslmode=disable in the connection string):
The TLS overhead shown above is negligible if your database is hosted in the same region as your function.
Some other database clients and ORMs in the Node ecosystem disable TLS by default for PostgreSQL databases. When comparing the performance of Prisma ORM to them, this can unfortunately lead to performance impressions that are caused by this difference in out-of-the-box security.
We recommend moving your database and functions into the same region rather than potentially compromising security to get a performance boost. This will keep your database secure and result in an even quicker cold start.
This is just the beginning
While we made incredible progress over the last couple of months, we're only just getting started.
We want to:
- Optimize the Schema Builder (the Teal segment of the graphs) to be close to or actually 0 by potentially doing some of that work lazily or during query validation.
- Optimize the loading of Prisma (the Yellow segment of the graphs), which represents the time it takes to load Prisma, as well and make it as small as possible.
- Apply all of the above learnings to other databases besides PostgreSQL.
- The big one: Look at the performance of Prisma Client queries and optimize how long these take, both with little and a lot of data.
You can expect updates to this blog post (when we further improve the cold start performance), or even another blog post in the coming weeks or months as we progress on our journey to improve Prisma ORM's performance.
You can help!
This goal to make the Prisma experience on serverless as smooth as we can is a very ambitious one. While we have a fantastic team dedicated to improving the startup performance of serverless functions using Prisma Client, we also realize we have a massive community of developers eager to contribute where they can to this initiative.
We invite you to help improve the performance of Prisma Client, specifically in the context of serverless startup times.
There are many ways you can contribute to this goal of providing a world-class ORM that is accessible in serverless environments and on the edge:
- Submit issues you find when working with Prisma on serverless.
- Have an idea how we might improve? Start a discussion!
- Try out the
jsonProtocolpreview feature and provide feedback.
Prisma ORM is an open source project, and as such we fully understand the importance of community feedback and participation. We love feedback, critiques, questions and anything that might help push Prisma forward for the good of every developer.
Don’t miss the next post!
Sign up for the Prisma Newsletter