Database Access in Serverless Environments with the Prisma Data Proxy


Databases connection management in serverless functions is a major issue for many developers. The Prisma Data Proxy (Early Access) solves this problem by managing a connection pool.
Update (May 2026): Prisma Data Proxy has been discontinued. If you need connection pooling for serverless Prisma ORM apps today, start with Prisma Accelerate and the current deployment docs. If you're starting a new project and want a managed Postgres database plus Prisma ORM, take a look at Prisma Postgres.
Contents
- Serverless enables fast development
- Stateful database connections don't map well to stateless serverless functions
- Connection pooling to the rescue
- Announcing the Prisma Data Proxy 🎉
- Let us know what you think
Serverless enables fast development
Serverless functions are an incredibly convenient tool that allow developers to quickly implement and deploy functionality that can then be invoked via HTTP requests.
A drastically reduced operational overhead, easy scaling thanks to the dynamic allocation of computational resources, and a consumption-based pricing model are more features of serverless functions that explain their popularity among developers.
Serverless is also integrated into frameworks like Next.js where an entire backend can be implemented via API routes. Deployed to serverless platforms like Vercel, every API route is mapped to a serverless function to handle incoming requests.
Stateful database connections don't map well to stateless serverless functions
However, as developers started to harness serverless functions for the use case of building their backends, they ran into an issue.
Accessing a database from a serverless function
Serverless functions are short-lived, ephemeral and rarely get reused. This means that as traffic spikes, the number of instances of a serverless function goes up as well.
This stateless nature of serverless functions doesn't map well to the statefulness of traditional databases that require a TCP connection between application and database server. This connection itself is kept open in memory and thus is part of the application state.
Let's quickly understand the exact issues that arise when talking to a database from serverless functions.
When a serverless function needs to access a database, it establishes a connection to it, submits a query and receives the response from the database. The response data is then delivered to the client that invoked the serverless function, the database connection is closed and the function is torn down again.
Serverless functions exhaust the connection limit
If the number of parallel function invocations is low, there are no issues. However, during traffic spikes, it can happen that a lot of parallel functions are spawned, each requiring its own database connection.
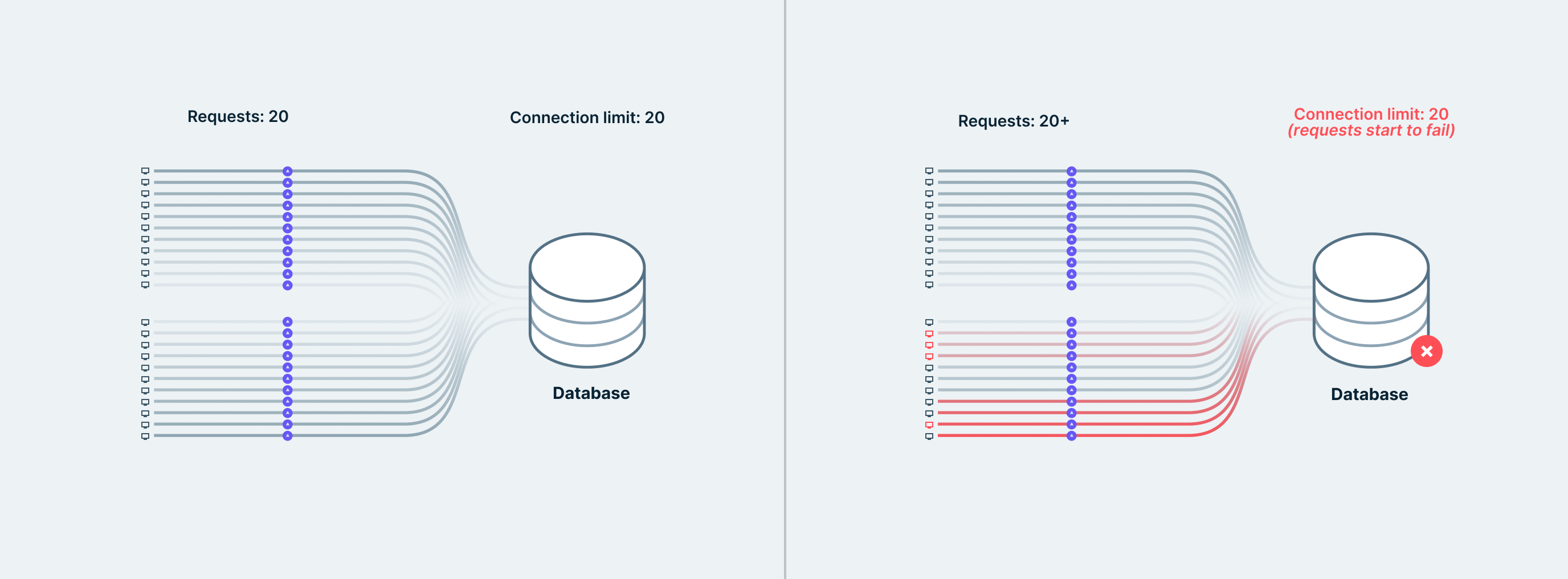
Traditional databases like PostgreSQL and MySQL typically have a database connection limit that can easily get exhausted in these situations. Once the database can't accept any new connections from newly spawned serverless functions, the requests made by the client applications start to fail.
Opening and closing a connection per request is slow
Another issue in this context is that the opening and closing of database connections is a fairly expensive operation to perform due to TLS termination and resource allocation for the connection in the database. This adds to the already existing problem of cold starts in serverless functions and slows down the execution of a request even more.
So besides the exhaustion of the database connection limit, performance can be impacted by the fact that database connections do not get reused.
Connection pooling to the rescue
The solution to the problems named above is called connection pooling. By creating a pool of database connections, it is ensured that database connections can be reused and pressure on the database is managed appropriately.
Traditional servers can maintain a connection pool
In traditional, server-based applications, managing a connection pool is not a problem because the server is able to maintain its state. In serverless functions, however, it is not possible to maintain a connection pool across incoming requests because of the stateless nature of the functions.
Serverless functions need an external connection pool
The only solution for serverless functions to get around the problem of database connection management is to introduce a proxy server in front of the database that manages a connection pool.
Existing tools like pgBouncer for PostgreSQL require notable overhead in managing an additional infrastructure component.
Announcing the Prisma Data Proxy 🎉
The Prisma Data Proxy is a proxy server for your database that manages a connection pool and ensures existing database connections are reused. This prevents incoming user requests from failing and improves the performance of your app.
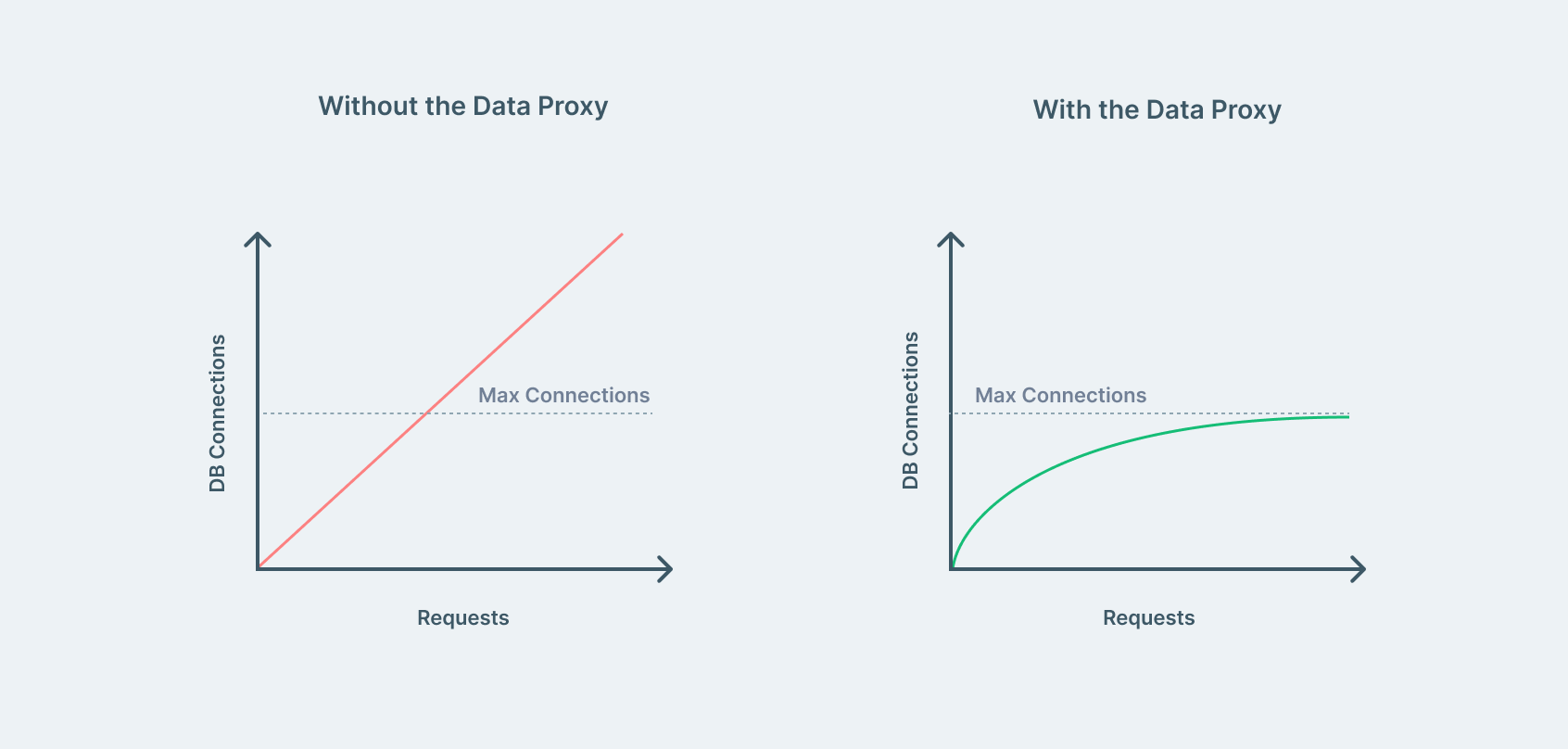
The Data Proxy integrates nicely with the Prisma ORM and can be enabled in a few simple steps via the Prisma Data Platform.
Note: The Prisma Data Proxy is currently in Early Access and not yet recommended for production use.
To learn how the Data Proxy works, check out Daniel Norman's recent talk about it:
The Data Proxy also enables entirely new use cases, such as accessing a database from limited function environments such as Cloudflare Workers. Follow the guide in our docs to learn more or watch the demo from our recent "What's new in Prisma"-livestream.
Modern alternatives
This article remains a useful explanation of why serverless workloads need connection pooling, but the product recommendation has changed.
- Use Prisma Accelerate if you want managed connection pooling and caching for Prisma ORM.
- Use Prisma Postgres if you want a managed Postgres database that works well with Prisma ORM.
- Use the current Prisma Client deployment docs for up-to-date serverless deployment guidance.
Keep reading

Deploy Prisma Apps with create-prisma
create-prisma now scaffolds Compute-ready Prisma apps with prisma.compute.ts, compute:deploy, Prisma Postgres, and Prisma Skills add-ons.


Configure Prisma Compute deploys in TypeScript
Prisma Compute now reads a typed TypeScript config file, so deploys are reproducible and monorepos work: declare one app or several, then ship the whole system with one command.
Build your next app with Prisma
Start free. Scale when you’re ready.