Database access on the Edge with Next.js, Vercel & Prisma Accelerate

The Edge enables application deployment across the globe. This article explores what Edge environments are, the challenges that arise when working in Edge environments and how to access databases on the Edge using Prisma Accelerate.
What is the Edge?
Traditionally, applications would be deployed to a single region or data center, in either a virtual machine, Platform as a Service (PaaS) like Heroku, or Functions as a Service (FaaS) like AWS Lambda. While this deployment pattern worked fine, the problem this created was that a user located on the other side of the globe would experience slightly longer response times.
We — developers — attempted to fix this with the JAMstack architecture, where static assets, such as HTML, CSS, JavaScript, and images, would be distributed across the globe in a Content Delivery Network (CDN). This improved loading times — the Time to First Byte (TTFB) — of web applications, but if the application required dynamic data, e.g., from an API or database, the application needed to make another request for the data. This also worked fine. However, the side effect was that we also distributed loading spinners across the web.
We took this a step further and introduced Edge computing such as Vercel's Edge Network. The Edge is a form of serverless compute that allows running server-side code geographically close to its end users.
Edge computing works similarly to serverless functions, without the cold starts because they have a smaller runtime. This is great because web apps would perform better, but it comes at a cost: A smaller runtime on the Edge means that you don't have the exact same capabilities as you would have in regular Node.js runtime used in serverless functions.
Edge functions can easily exhaust database connections
Edge functions are stateless, meaning they lack persistent state between requests. This architecture clashes with the stateful nature of traditional relational databases, where each request requires a new database connection.
With every request to the application, a new database connection is established, adding substantial overhead to queries and potentially hindering application performance as it scales. Moreover, during traffic spikes, the database is at risk of running out of database connections, leading to downtimes.
You can learn more about the challenges of database access in Edge environments, which is similar to serverless environments, in this article.
Database access on the Edge with Prisma Accelerate
Prisma Accelerate offers a connection pooler for your database, that reuses database connections and allows you to interact with your database over HTTP.
The connection pool of Accelerate ensures optimal performance by efficiently reusing database connections for serverless and edge applications (i.e. applications using Vercel Edge Functions or Cloudflare Workers).
In addition to providing connection pooling by default, Prisma Accelerate also offers a global edge cache. You can drastically improve the performance of your applications by opting-in and caching your query results in-line with your Prisma queries. You can learn more about caching with Accelerate here.
Do single-region databases and the Edge fit together?
Edge computing is a fairly young, yet very promising technology that has the potential to drastically speed up applications in the future. The ecosystem around the Edge is still evolving and best practices for globally distributed applications are yet to be figured out.
At Prisma, we are excited about the developments in the Edge ecosystem and want to help move it forward! However, connecting to a single-region database as shown in this article is probably not the best idea for real-world applications today.
To reduce large roundtrips from edge functions to a single-region database, you can use a global cache, which allows you to store your data closer to your edge apps. Prisma Accelerate offers a global cache, which you can easily opt-in to drastically improve the performance of your edge apps. As a best practice, we still recommend to generally deploy your database as closely as possible to your API server to minimize latency in response times.
While the architecture shown in this article might not cater to real-world use cases yet, we are excited about the possibilities that are opening up in this space and want to make sure Prisma can help solve the problems related to database access on the Edge in the future!
Here's a video from Jeff Delaney, Fireship, on whether "edge" computing is faster.
Demo: Database access on the Edge
Let's now take a look how to access a database from Vercel's Edge functions using Prisma Accelerate.
You can find the live demo of the application here and the completed project on GitHub.
The demo application that is used here is a random quote generator built with Next.js and styled with TailwindCSS. The application will take advantage of Next.js' Edge server rendering and Edge API routes to fetch data from a remote PostgreSQL database on every page refresh.
The final state of application you will be working on will resemble this:
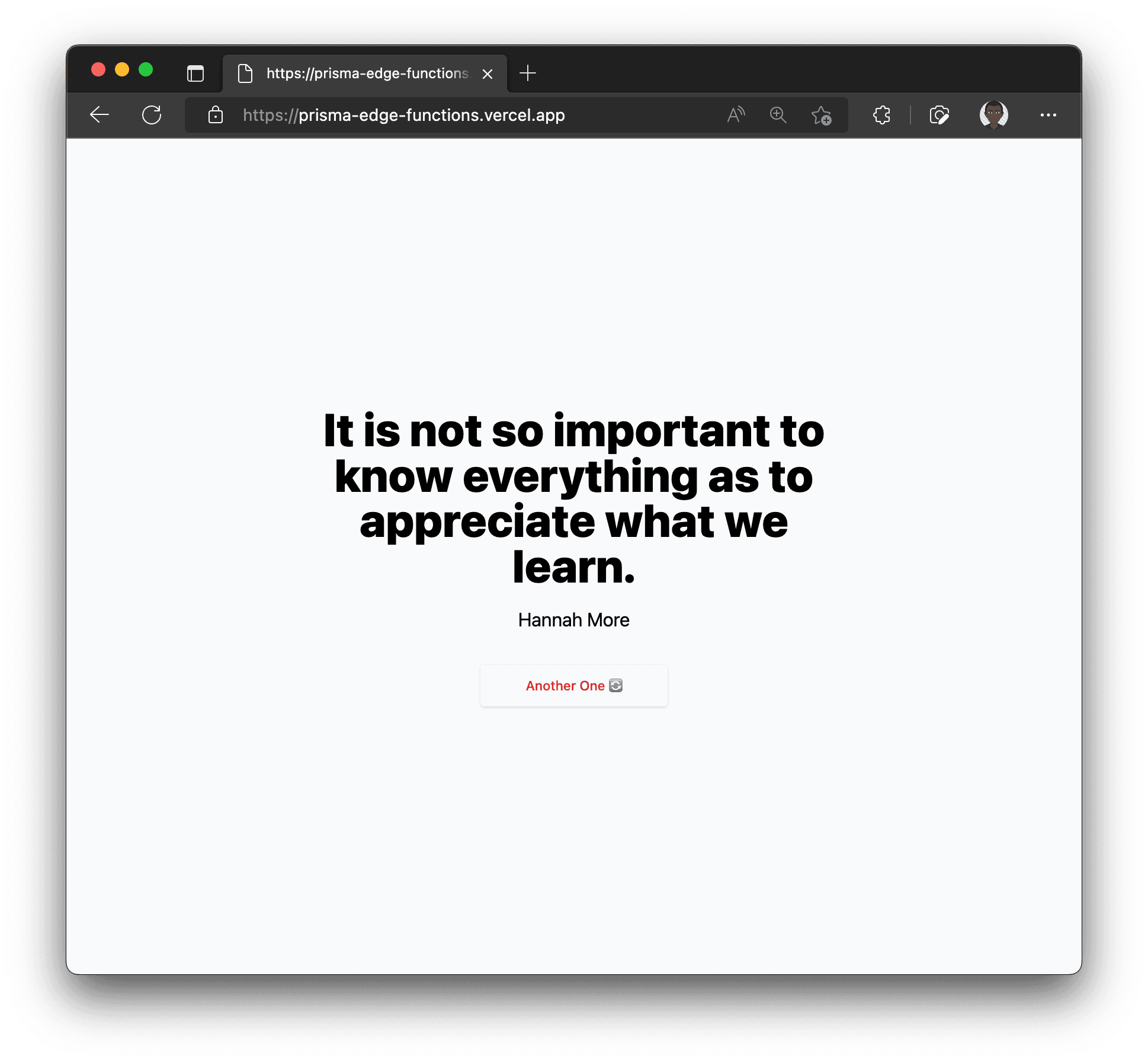
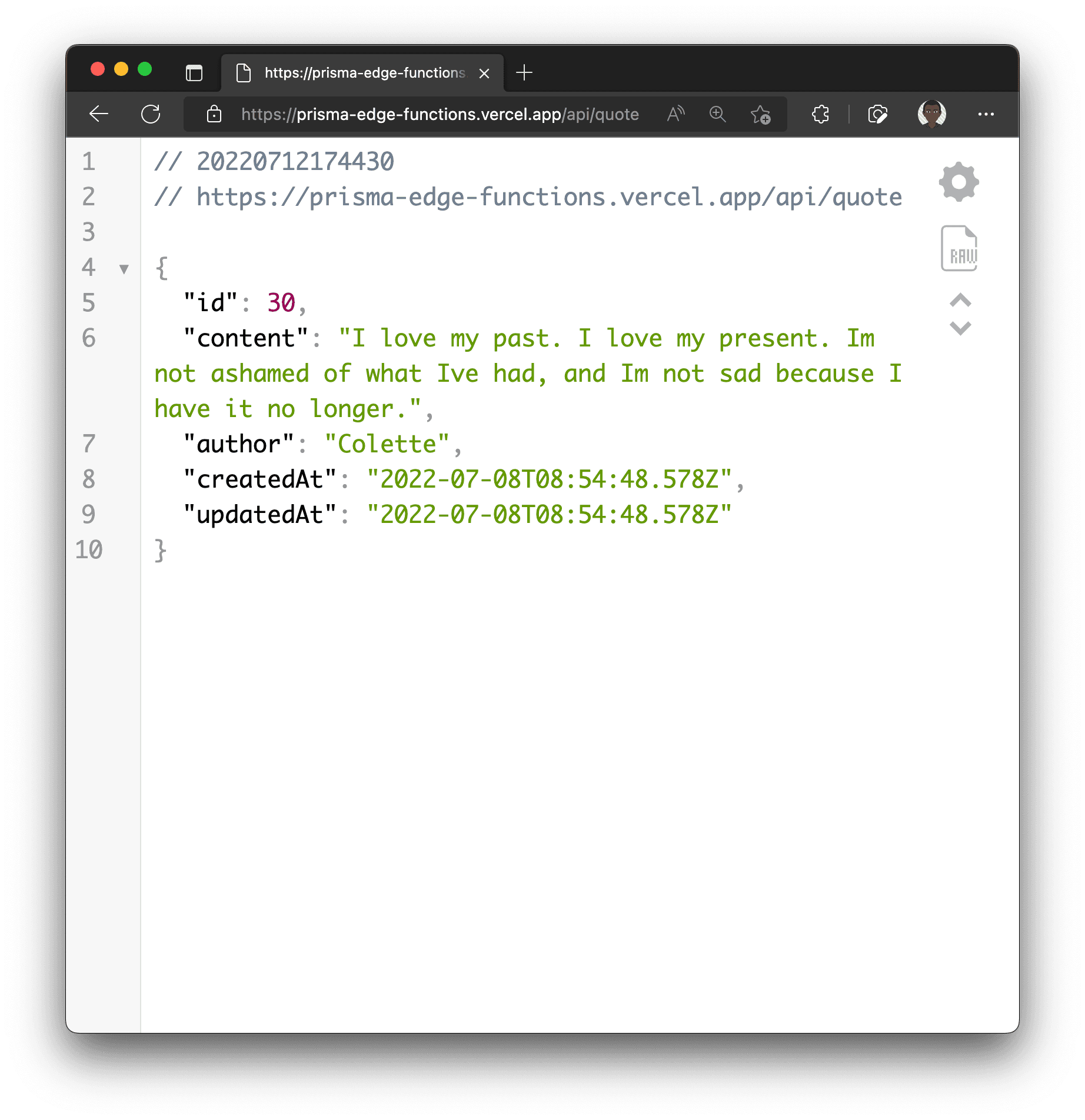
The application contains a single model called Quote with the following fields:
// schema.prisma
model Quote {
id Int @id @default(autoincrement())
content String
author String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}Prerequisites
To successfully follow along, you will need:
- Node.js
- A cloud-hosted PostgreSQL database (set up a free PostgreSQL database on Supabase or on Neon)
- A GitHub account to host your application code
- A Prisma Data Platform account to provision a Prisma Accelerate project
- A Vercel account to deploy the app
Clone application
Navigate to your directory of choice and run the following command to set up a new Next.js project:
npx create-next-app --example https://github.com/prisma/prisma-edge-functions/tree/starter prisma-edge-functionsNavigate into the directory:
cd prisma-edge-functionsThe page and API Route are also configured to use Vercel’s Edge Runtime with the following configuration in both files:
export const config = {
runtime: 'experimental-edge',
}Set up the database
You can use a free PostgreSQL database hosted on Supabase or Neon.
Once you’ve set up the database, update the .env file at the root of your project with the database’s connection string:
# .env
DATABASE_URL="postgresql://USER:PASSWORD@HOST:PORT/DATABASE"With the DATABASE_URL environment variable set, apply the existing Prisma schema to your database schema using the prisma migrate dev command. The prisma migrate dev command will apply any pending migration in the /prisma/migrations folder against your database.
npx prisma migrate devNext, populate the database with sample data. The project contains a seed script in the ./prisma/seed.ts file and sample data in ./prisma/data.json. The sample data includes 178 quotes.
npx prisma db seedYou should see the following output:
Environment variables loaded from .env
Running seed command `ts-node prisma/seed.ts` ...
[Elevator Music Cue] 🎸
Done 🎉
🌱 The seed command has been executed.Set up Prisma Accelerate
Navigate to GitHub and create a private repository:
Next, initialize your repository and push your changes to GitHub:
git init
git remote add origin https://github.com/<username>/prisma-edge-functions
git add .
git commit -m "initial commit"
git push -u origin mainNote: Replace the
<username>placeholder value with your GitHub username before pasting the value on your terminal.
Once you’ve set up your repository, navigate to the Platform Console and sign up for a free account if you don’t have one yet.
After signing up:
-
Create a new project by clicking the New project button
-
Fill out your Project’s name and then click the Create Project button
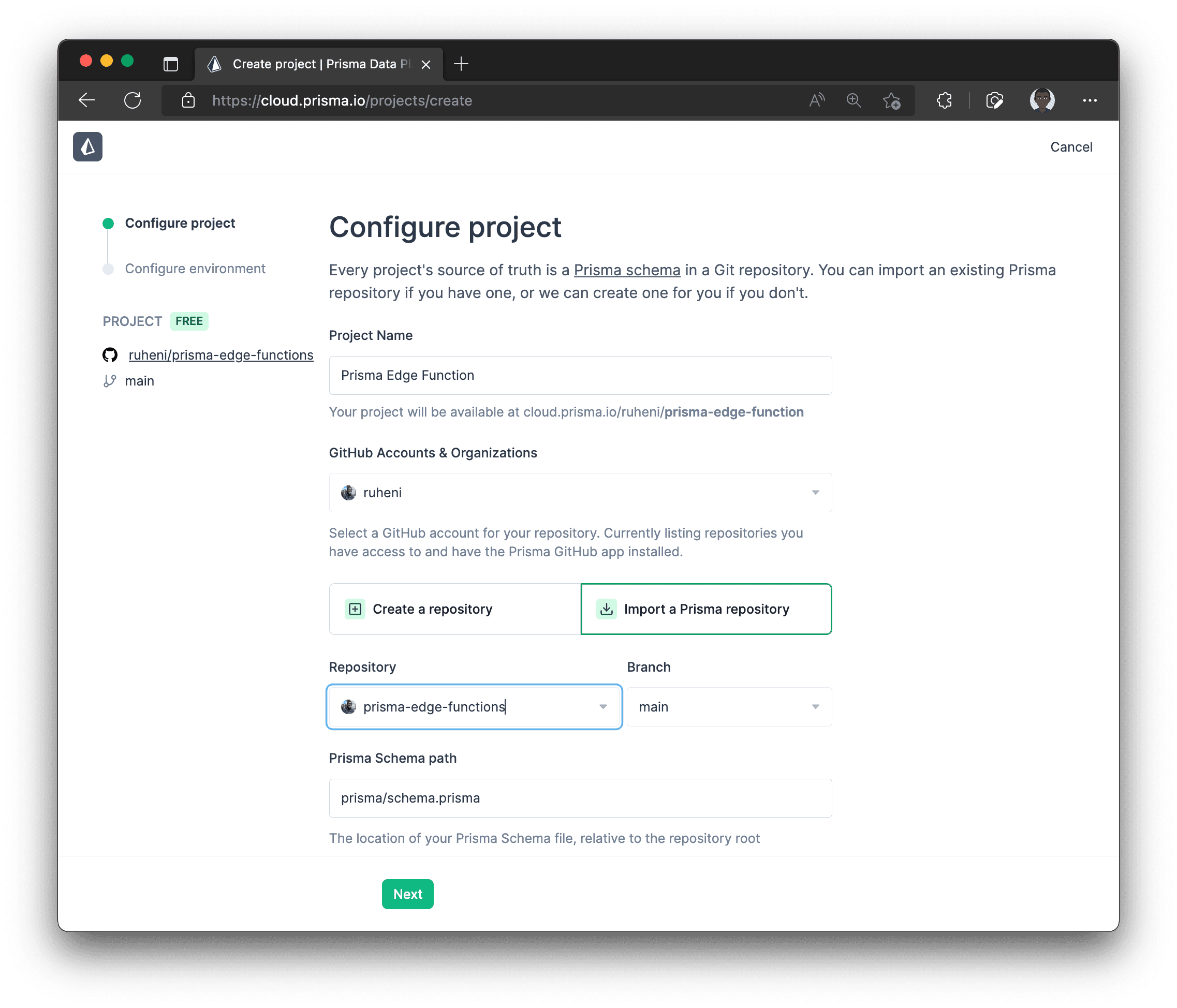
-
Enable Accelerate by clicking the Enable Accelerate button
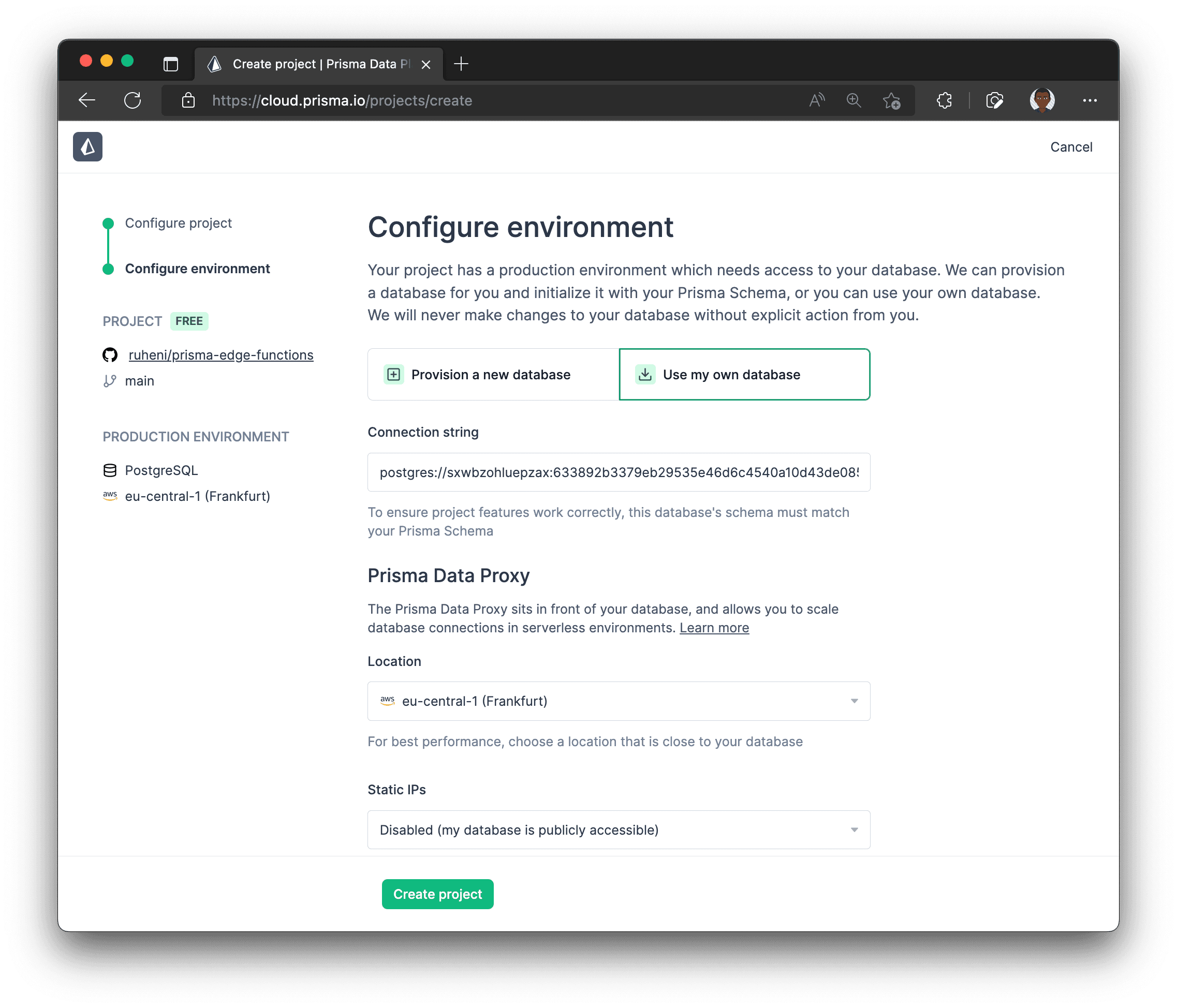
-
Add your database connection string to the Database connection string field and select a region close to your database from the Region drop-down
-
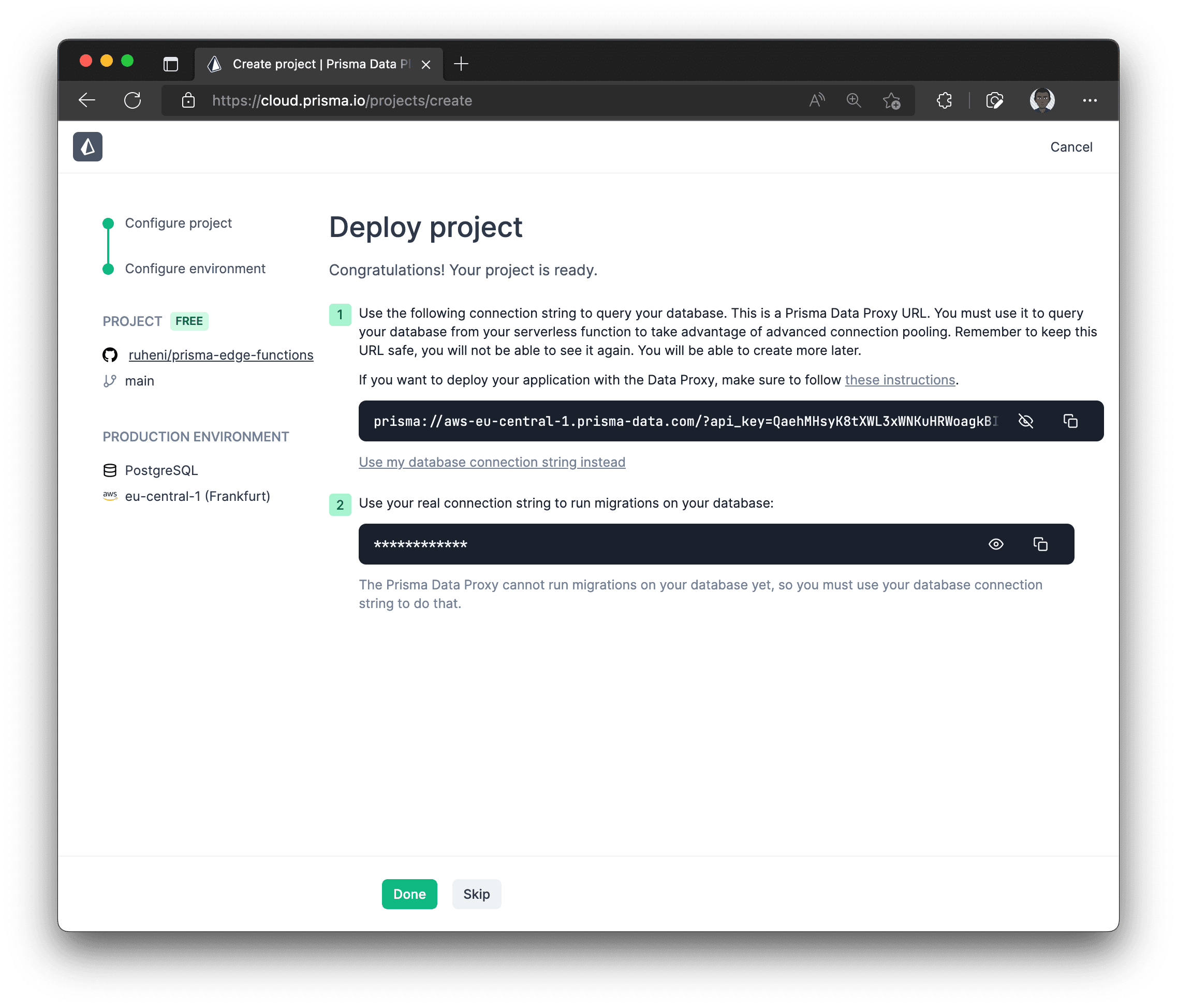
Generate an Accelerate connection string by clicking the Generate API key button
-
Copy the generated Accelerate connection string
Accelerate has been successfully setup 🎉!
Update your application code
Back in your project, rename the existing DATABASE_URL to MIGRATE_DATABASE_URL and paste the Prisma Accelerate URL into your .env file as the new DATABASE_URL:
DATABASE_URL="prisma://accelerate.prisma-data.net/?api_key=__API_KEY__"
MIGRATE_DATABASE_URL="postgresql://USER:PASSWORD@HOST:PORT/DATABASE"The
MIGRATE_DATABASE_URLvariable will be used to apply any pending migrations during the build process. Thepackage.jsonfile uses thevercel-buildhook script to runprisma migrate deploy && next build
Then install the Prisma Accelerate client extension:
npm i @prisma/extension-accelerateNext, generate Prisma Client that will connect through Prisma Accelerate using HTTP:
npx prisma generate --no-engineThen, navigate to lib/prisma and update Prisma Client’s import from @prisma/client to @prisma/client/edge to be make it compatible with edge environments:
// lib/prisma.ts
-import { PrismaClient } from "@prisma/client";
+import { PrismaClient } from "@prisma/client/edge";
+import { withAccelerate } from "@prisma/extension-accelerate";
import { PrismaClient } from '@prisma/client'
const prismaClientSingleton = () => {
- return new PrismaClient()
+ return new PrismaClient().$extends(withAccelerate())
}
declare global {
var prisma: undefined | ReturnType<typeof prismaClientSingleton>
}
const prisma = globalThis.prisma ?? prismaClientSingleton()
export default prisma
if (process.env.NODE_ENV !== 'production') globalThis.prisma = prismaTest the application locally
Now that setup is done, you can start up your application locally:
npm run devNavigate to http://localhost:3000, and this is what it might look like at the moment.
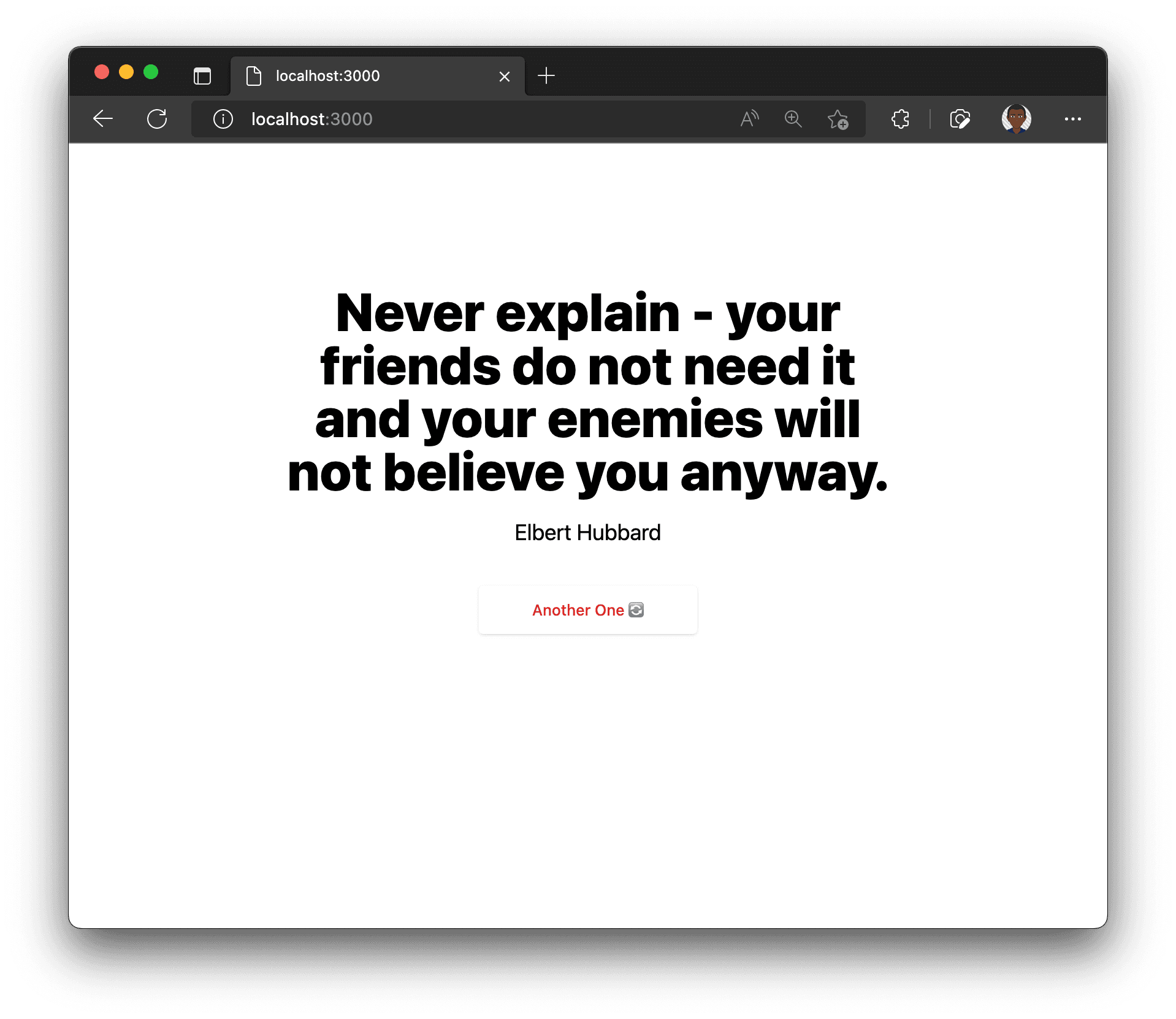
The quote you will see might be different because the quote is selected randomly. You can hit Another one 🔄 to refresh the page with a new quote.
You can also navigate to http://localhost:3000/api/quote to get a random quote in JSON format.
Deploy the application
Commit the existing changes to version control and push them to GitHub.
git add .
git commit -m "update prisma client"
git pushNavigate to Vercel and import your GitHub repository.
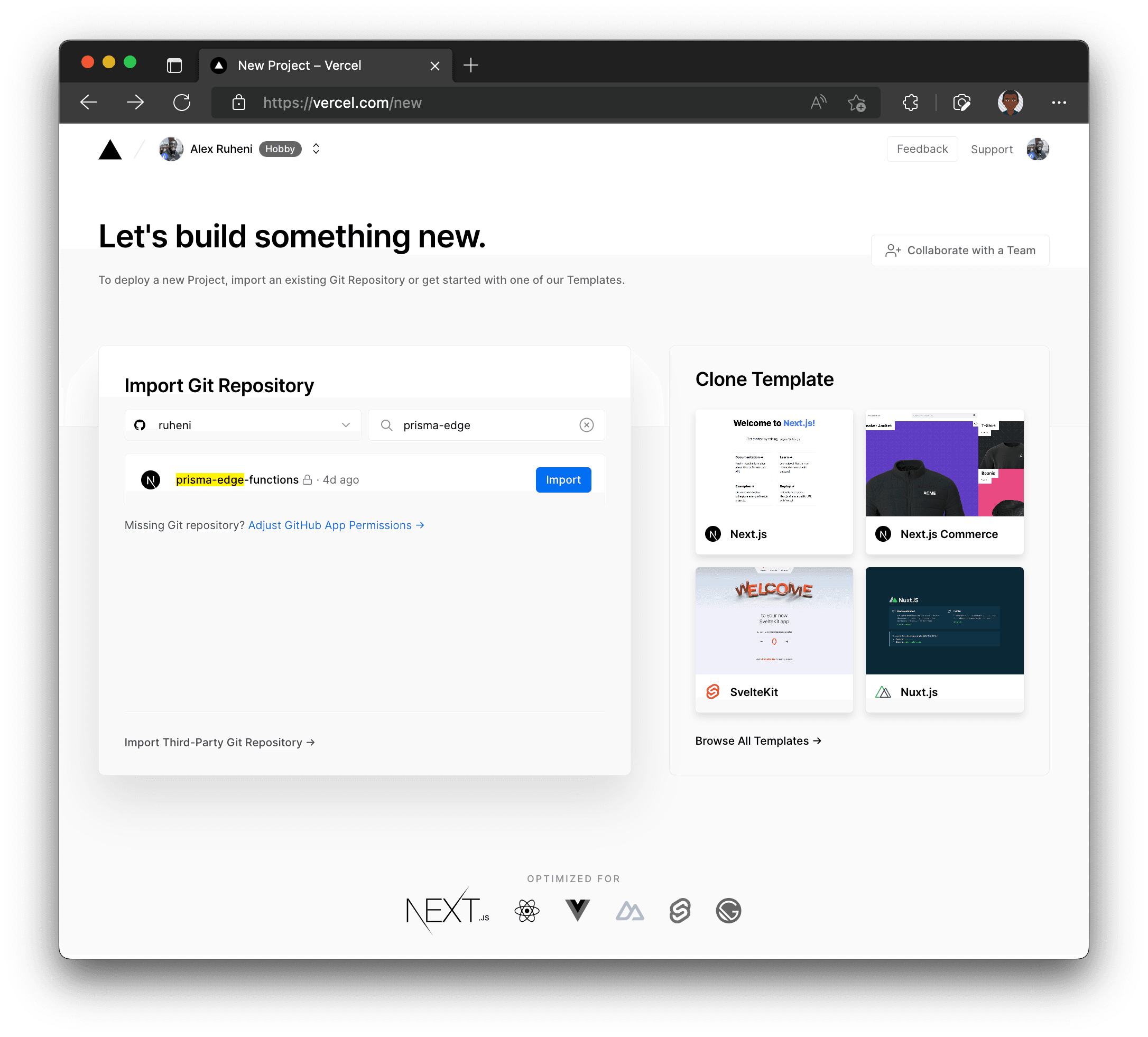
Give your project a name and open up the Environment Variables toggle and fill out the following environment variables:
MIGRATE_DATABASE_URL: the database’s connection stringDATABASE_URL: the Prisma Accelerate connection stringPRISMA_GENERATE_NO_ENGINE:true
The
PRISMA_GENERATE_NO_ENGINEcan be set to a truthy value to generate a Prisma Client without an included query engine in order to reduce deployed application size when paired with Prisma Accelerate.
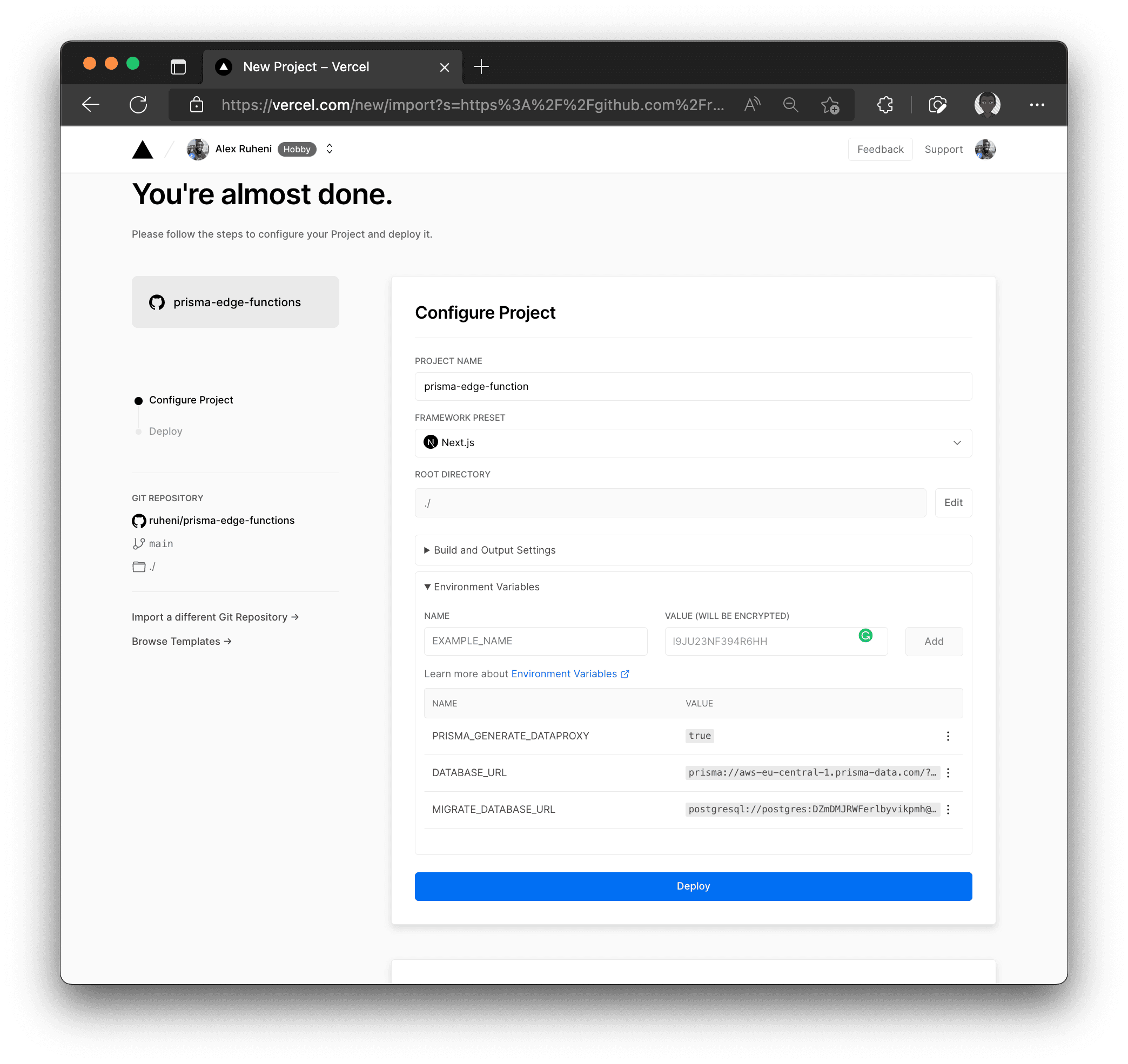
Finally, click Deploy to kick off the build:
Congratulations
Once the build is successful, you should see the following:
Click the Visit button to view the deployed version of the application.
Back on the Vercel dashboard in the Overview tab, click View Function Logs. Next, select the “index” function. You will see that your application’s runtime is Edge and the Region is Global.
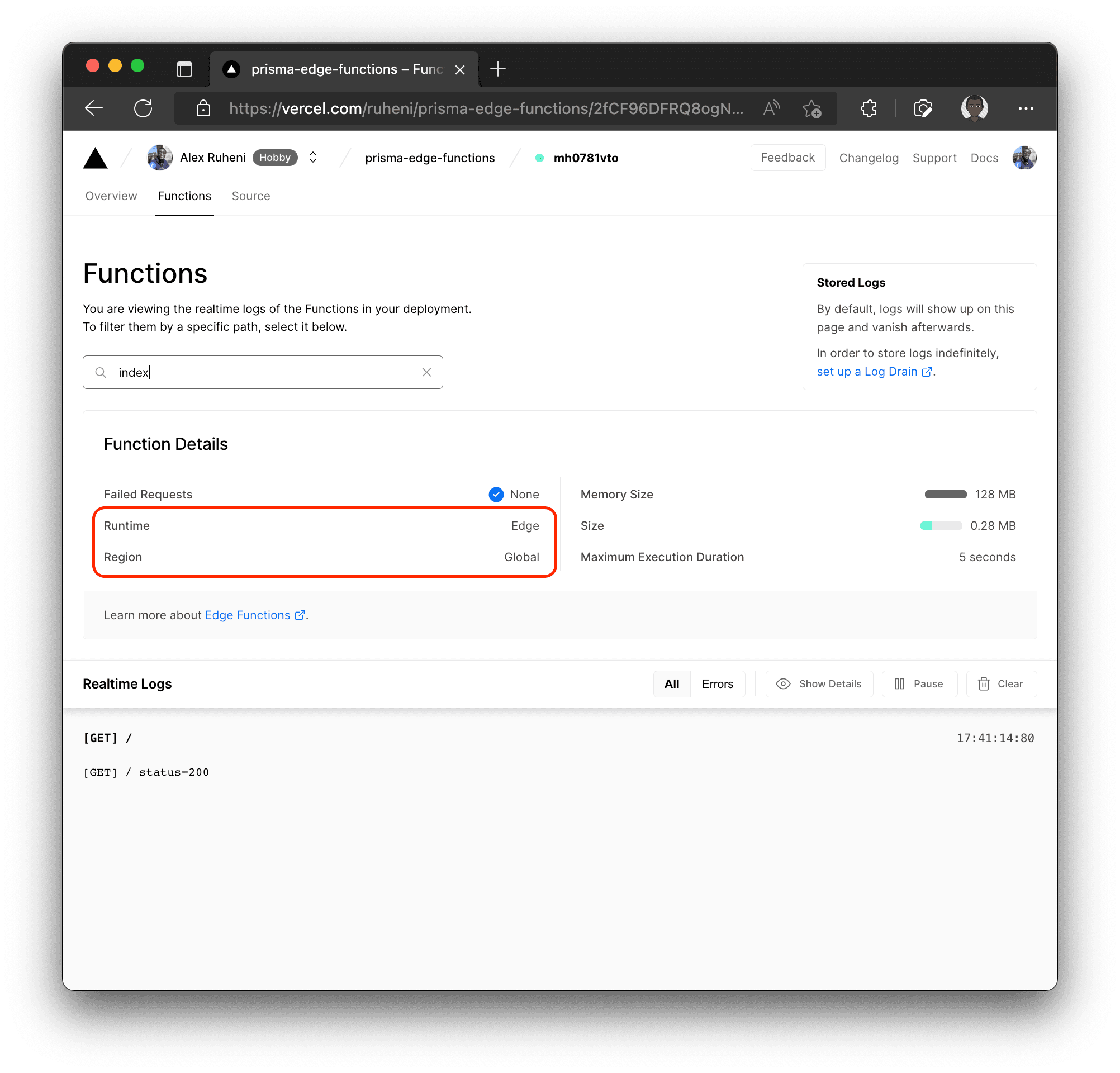
Refresh the page in your application, and back on Vercel, you will see the request’s status logged.
Congratulations! 🎉
Conclusion
The Edge enables instant application deployment across the globe, changing how developers think about application development and deployment.
Prisma Accelerate is one tool that enables developers to build and ship web apps requiring database access on the Edge.
The Edge is still in its early stages, with a few drawbacks. However, it's exciting to see how building web apps on the Edge will look.
Keep reading

You Don't Need Elasticsearch, Postgres Already Has Full-Text Search
Build full-text search with tsvector, GIN indexes, and pg_trgm typo tolerance on Prisma Postgres. For most apps, no Elasticsearch cluster required.


Extending Prisma Next with Typed Postgres ltree
Use PostgreSQL ltree in Prisma Next with prisma-ltree: typed path columns plus ancestor and descendant queries.

Build your next app with Prisma
Start free. Scale when you’re ready.