Prisma 2.0: Confidence and productivity for your database

Accessing databases in Node.js and TypeScript can feel brittle and painful. Prisma removes the pain with an auto-generated and type-safe query builder that's tailored to your data! Try it out!
Contents
- The problem: Working with databases is difficult
- The solution: Prisma makes databases easy
- What you can build with Prisma
- A strong ecosystem growing around Prisma
- Getting started with Prisma
- A huge thank you to our community 💚
The problem: Working with databases is difficult
The existing landscape of database access libraries ranges from sending raw SQL strings to higher-level abstractions like SQL query builders and ORMs. Each of these approaches come with their own problems and pitfalls. Overall, there's a lack of best practices for application developers who work with databases in Node.js and TypeScript.
The jungle of existing tools and lack of best practices have two main consequences:
- Developers aren't productive because the existing tools don't fit their needs
- Developers aren't confident that they're doing the "right thing"
The solution: Prisma makes databases easy
Prisma is an open source database toolkit. It replaces traditional ORMs and makes database access easy with an auto-generated and type-safe query builder for Node.js and TypeScript.
Prisma currently supports PostgreSQL, MySQL and SQLite databases – with more planned. Please create new GitHub issues or subscribe to existing ones (e.g. for MongoDB or DynamoDB) if you'd like to see support for specific databases.
After running the Preview and Beta versions of Prisma 2.0 for almost a year and gathering lots of helpful feedback from our community, we are excited to launch Prisma Client for General Availability 🎉
Prisma Client: Modern database access for Node.js and TypeScript
Prisma Client provides an entirely new way for developers to access a database with two main goals in mind:
- Boost productivity by letting developers query data in natural and familiar ways
- Increase confidence with type-safety, auto-completion and a robust query API
How Prisma Client boosts productivity and raises confidence
In this section, we'll take a closer look at how Prisma Client enables developers to build applications faster while writing more resilient and robust code.
Here's an overview of the benefits you get from Prisma Client:
- Thinking in objects: A natural and familiar query API
- Working intuitively with relations
- Auto-completion for database queries
- Fully type-safe database queries
- A declarative and human-readable database schema
- A single source of truth for database and application models
Thinking in objects: A natural and familiar query API
One of the biggest benefits of Prisma Client is the level of abstraction it provides. It allows developers to think of their data in objects (instead of SQL), reducing the cognitive and practical overhead of mapping relational to object-oriented data.
Although Prisma Client returns data as objects, it's not an ORM and therefore doesn't suffer from common problems often caused by the object-relational impedance mismatch.
Prisma doesn't map classes to tables and there are no complex model instances or hidden performance pitfalls (e.g. due to lazy loading) as often seen in traditional ORMs. Prisma Client provides a query API for your database schema with a focus on structural typing and natural querying (in that sense, it gets closest to the data mapper pattern of traditional ORMs).
As an example, assume you have these User and Post tables:
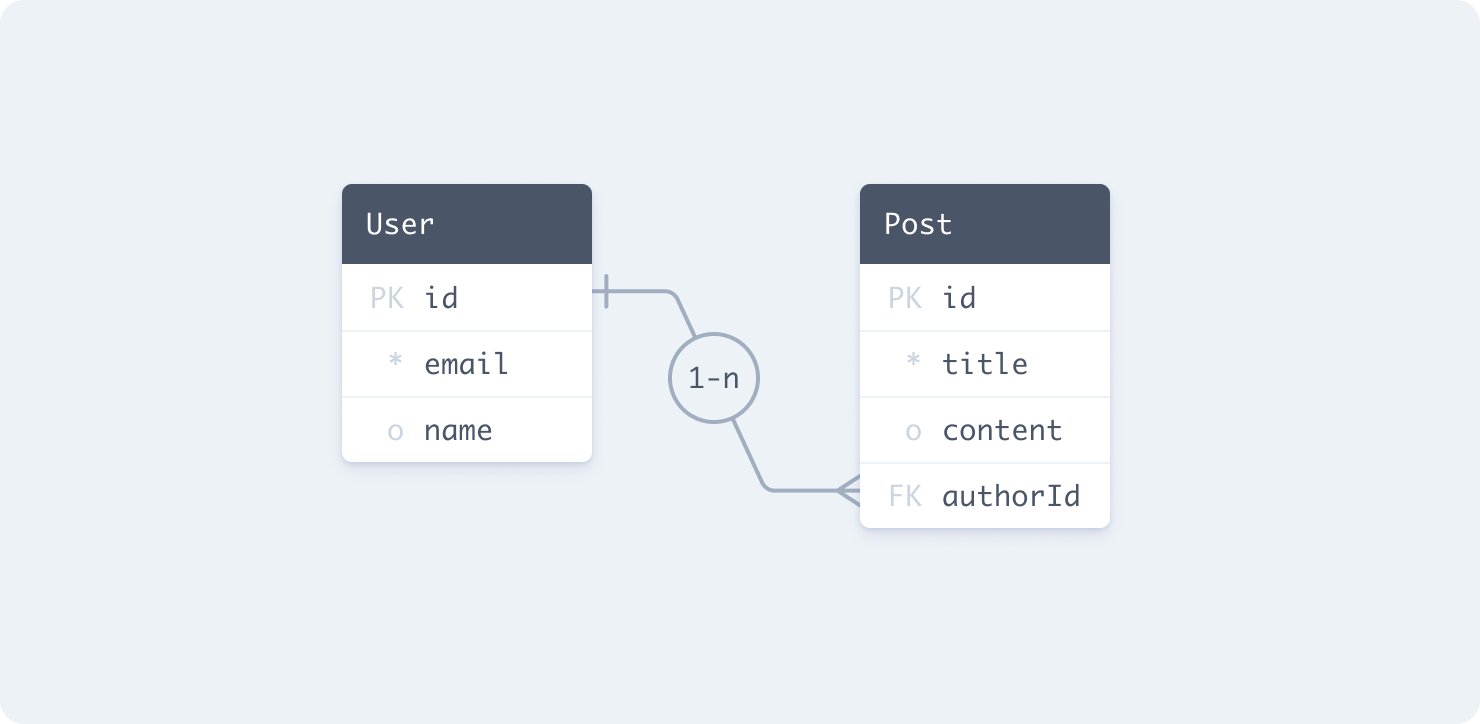
CREATE TABLE "User" (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL UNIQUE,
name TEXT
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
title VARCHAR(25) NOT NULL,
content TEXT,
"authorId" INTEGER NOT NULL,
FOREIGN KEY ("authorId") REFERENCES "User"(id)
);With Prisma Client, you can formulate queries like the following to read and write data in these tables:
const postsByAuthor = await prisma.post.findMany({
where: {
author: { id: 42 }
},
})[{
id: 1,
title: "Follow Prisma on Twitter"
authorId: 42,
}, {
id: 2,
title: "Join us online for Prisma Day 2020"
authorId: 42,
}]As you can see, the resulting postsByAuthor contains an array of plain JavaScript objects (if you're using TypeScript, these objects will be strongly typed).
Note: The
authorfield is a virtual relation field that connects thePostto theUsertable in the Prisma Client API. Since it's not directly represented in the database, it can be named in any way you like.
You can also easily include the relations of a model, in this case, you could also retrieve the information about the "author" of the return posts:
const postsByAuthorWithAuthorInfo = await prisma.post.findMany({
where: {
author: { id: 42 }
},
include: {
author: true,
}
})[{
id: 1,
title: "Follow Prisma on Twitter",
content: null,
authorId: 42,
author: {
id: 42,
email: "alice@prisma.io",
name: "Alice"
}
}, {
id: 2,
title: "Join us online for Prisma Day 2020",
content: null,
authorId: 42,
author: {
id: 42,
email: "alice@prisma.io",
name: "Alice"
}
}]Note again that the objects in postsByAuthorWithAuthorInfo are fully typed when using TypeScript, so accessing a non-existing property on the author of a post, in this case, would throw a compiler error.
Working intuitively with relations
Accessing related data (meaning, data from tables that are connected via foreign keys) can be especially tricky with existing database tools. This is mostly due to the fundamental mismatch of how these relations are represented in relational databases and object-oriented languages:
- Relational: Data is typically normalized (flat) and uses foreign keys to link across entities. The entities then need to be JOINed to manifest the actual relationships.
- Object-oriented: Objects can be deeply nested structures where you can traverse relationships simply by using dot notation.
Prisma Client lets you intuitively read and write nested data:
const result = await prisma.user.findMany({
include: {
posts: {
select: {
id: true,
title: true
}
}
}
})const result = await prisma.user.create({
data: {
name: "Alice",
email: "alice@prisma.io",
posts: {
create: {
title: "Hello World"
}
}
}
})const result = await prisma.user
.findOne({ where: { id: 42 }})
.posts()const result = await prisma.user
.findOne({
where: { email: 'alice@prisma.io' },
})
.posts({
where: {
title: {
startsWith: 'Hello',
},
},
})Note again that in all of the above cases, the result will be fully typed if you're using TypeScript!
A declarative and human-readable database schema
Reading definitions of tables and other database structures using SQL (e.g. CREATE TABLE User, ALTER TABLE User ADD COLUMN email) can feel noisy. Prisma introduces a declarative version of your database schema known as the Prisma schema.
The Prisma schema is generated by introspecting your database and serves as the foundation for the query API of Prisma Client. As an example, this is the equivalent version of the above User and Post definitions:
model User {
id Int @default(autoincrement()) @id
email String @unique
name String?
posts Post[]
}
model Post {
id Int @default(autoincrement()) @id
title String
content String?
author User @relation(fields: [authorId], references: [id])
authorId Int
}CREATE TABLE "User" (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL UNIQUE,
name TEXT
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
title VARCHAR(25) NOT NULL,
content TEXT,
"authorId" INTEGER NOT NULL,
FOREIGN KEY ("authorId") REFERENCES "User"(id)
);Note: We are also working on a tool for database migrations called Prisma Migrate. With Prisma Migrate, the introspection-based workflow is "reversed" and you can map your declarative Prisma schema to the database; Prisma Migrate will generate the required SQL statements and execute them against the database.
Auto-completion for database queries
Auto-completion is an immensely powerful feature that enables developers to explore an API in their editors instead of looking up reference docs. Because Prisma Client is generated from your database schema, the query API will feel very familiar to you.
Having auto-completion available largely contributes to greater productivity because you can "learn the API as you use it". Auto-completion also increases confidence because you can be sure that the suggested API operations will work.
Fully type-safe database queries
Prisma Client guarantees full type-safety for all database queries, even when only a subset of a model's properties are retrieved or relations are loaded using include.
Consider again the User and Post tables from the example before, Prisma generates the following TypeScript types to represent the data from these tables in your application:
type User = {
id: number
email: string
name: string | null
}
type Post = {
id: number
authorId: number | null
title: string | null
content: string | null
}Any plain CRUD query sent by Prisma Client will return a response of objects that are typed accordingly. However, consider again the query from above where include was used to fetch a relation:
const postsByAuthorWithAuthorInfo = await prisma.post.findMany({
where: {
author: { id: 42 }
},
include: {
author: true,
}
})[{
id: 1,
title: "Follow Prisma on Twitter",
content: null,
authorId: 42,
author: {
id: 42,
email: "alice@prisma.io",
name: "Alice"
}
}, {
id: 2,
title: "Join us online for Prisma Day 2020",
content: null,
authorId: 42,
author: {
id: 42,
email: "alice@prisma.io",
name: "Alice"
}
}]The objects inside postsByAuthorWithAuthorInfo don't match the generated Post type because they carry the additional author object. In that case, Prisma Client still provides full type-safety and is able to statically type the result! Here's what the type looks like:
const postsByAuthorWithAuthorInfo: (Post & {
author: User | null;
})[]Thanks to this, the TypeScript compiler will catch cases where you're accessing properties that don't exist. For example, this would be illegal:
// caught by the TypeScript compiler because `firstName` doesn't exist
postsByAuthorWithAuthorInfo[0].author.firstNameA single source of truth for database and application models
Database tools often have the problem of needing to synchronize changes that are made to data models between application code and the database. For example, after having changed a database table, developers often need to manually adjust the respective model in their application code and scan the codebase for usages of the table to update it.
This makes database schema migrations and code refactorings scary because there's no guarantee the two layers remain in sync after the change!
Prisma Client takes a different approach to this problem. Instead of manually synchronizing changes between application code and database, Prisma Client's query API is generated based on your database schema.
With that approach, you can simply re-generate Prisma Client after a database schema change and the changes will automatically be synchronized to your Prisma Client query API. Thanks to auto-completion and type-safety, updating your application code to the new queries will be a lot faster than with any other approach.
What you can build with Prisma
The main use case for Prisma is building server-side applications that need to persist data in a database.
Since the Preview phase of Prisma 2.0, we have seen developers build a wide range of applications, from social networking apps to e-commerce shops, to productivity tools and marketplaces. We are excited to see what you're building with Prisma!
This is the fastest I’ve developed in my career, by far. Prisma has dramatically reduced implementation time, while increasing confidence in my code. I’ve also been able to say yes to a lot of new incremental features; it now takes half a day to implement something that used to take two or three.
 Sean Emmer, CTO at Pearly
Sean Emmer, CTO at Pearly REST, GraphQL, Thrift, gRPC and more
Server-side applications typically expose an API that's consumed by frontend (e.g. web or mobile) or other apps. Prisma Client is compatible with all existing API technologies, such as REST, GraphQL, Thrift, or gRPC.

Prisma works with various deployment models
Prisma Client can be used in traditional monolithic servers, microservice architectures, and serverless deployments. Read the docs page about deployment to learn more.
A strong ecosystem growing around Prisma
Despite Prisma's young age, we are very proud and excited about the emerging ecosystem and a variety of tools we see growing around it.
The next generation of fullstack frameworks is based on Prisma
The Node.js ecosystem is known for lots of different frameworks that try to streamline workflows and prescribe certain conventions. We are extremely humbled that many framework authors decide to use Prisma as their data layer of choice.
The new RedwoodJS framework by GitHub co-founder Tom Preston-Werner seeks to become the "Ruby on Rails" equivalent for Node.js. RedwoodJS is based on React and GraphQL and comes with a baked-in deployment model for serverless functions.
Another framework with increasing anticipation and excitement in the community is Blitz.js. Blitz is build on top of Next.js and takes a fundamentally different approach compared to Redwood. Its goal is to completely eliminate the API server and "bring back the simplicity of server rendered frameworks".
Build type safe GraphQL servers with Nexus and the Prisma plugin
At Prisma, we're huge fans of GraphQL and believe in its bright future. That's why we founded the Prisma Labs team which dedicates its time to work on open source tools in the GraphQL ecosystem.
It is currently focused on building Nexus, a delightful application framework for developing GraphQL servers. As opposed to Redwood, Nexus is a backend-only GraphQL framework and has no opinions on how you access the GraphQL API from the frontend.
Using the Prisma plugin for Nexus, you can expose Prisma models in your GraphQL API without the overhead of implementing the typical CRUD boilerplate that's needed when connecting GraphQL resolvers to a database.
model User {
id Int @default(autoincrement()) @id
email String @unique
name String?
posts Post[]
}
model Post {
id Int @default(autoincrement()) @id
title String
content String?
author User @relation(fields: [authorId], references: [id])
authorId Int
}import { schema } from 'nexus'
schema.queryType({
definition(t) {
t.crud.user()
t.crud.users({
ordering: true,
})
t.crud.post()
t.crud.posts({
filtering: true,
})
},
})
schema.mutationType({
definition(t) {
t.crud.createOneUser()
t.crud.createOnePost()
t.crud.deleteOneUser()
t.crud.deleteOnePost()
},
})
schema.objectType({
name: 'User',
definition(t) {
t.model.id()
t.model.email()
t.model.name()
t.model.posts()
},
})
schema.objectType({
name: 'Post',
definition(t) {
t.model.id()
t.model.title()
t.model.content()
t.model.author()
},
})scalar DateTime
input DateTimeFilter {
equals: DateTime
gt: DateTime
gte: DateTime
in: [DateTime!]
lt: DateTime
lte: DateTime
not: DateTime
notIn: [DateTime!]
}
type Mutation {
createOnePost(
data: PostCreateInput!
): Post!
createOneUser(
data: UserCreateInput!
): User!
deleteOnePost(
where: PostWhereUniqueInput!
): Post
deleteOneUser(
where: UserWhereUniqueInput!
): User
}
enum OrderByArg {
asc
desc
}
type Post {
author(
after: String
before: String
first: Int
last: Int
skip: Int
): [User!]!
id: ID!
}
input PostCreateInput {
author: UserCreateManyWithoutAuthorInput
id: ID
}
input PostCreateManyWithoutPostsInput {
connect: [PostWhereUniqueInput!]
create: [PostCreateWithoutAuthorInput!]
}
input PostCreateWithoutAuthorInput {
id: ID
}
input PostFilter {
every: PostWhereInput
none: PostWhereInput
some: PostWhereInput
}
input PostWhereInput {
AND: [PostWhereInput!]
author: UserFilter
id: StringFilter
NOT: [PostWhereInput!]
OR: [PostWhereInput!]
}
input PostWhereUniqueInput {
id: ID
}
type Query {
post(
where: PostWhereUniqueInput!
): Post
posts(
after: String
before: String
first: Int
last: Int
skip: Int
where: PostWhereInput
): [Post!]!
user(
where: UserWhereUniqueInput!
): User
users(
after: String
before: String
first: Int
last: Int
orderBy: UserOrderByInput
skip: Int
): [User!]!
}
input StringFilter {
contains: String
endsWith: String
equals: String
gt: String
gte: String
in: [String!]
lt: String
lte: String
not: String
notIn: [String!]
startsWith: String
}
type User {
birthDate: DateTime!
email: String!
id: ID!
posts(
after: String
before: String
first: Int
last: Int
skip: Int
): [Post!]!
}
input UserCreateInput {
birthDate: DateTime!
email: String!
id: ID
posts: PostCreateManyWithoutPostsInput
}
input UserCreateManyWithoutAuthorInput {
connect: [UserWhereUniqueInput!]
create: [UserCreateWithoutPostsInput!]
}
input UserCreateWithoutPostsInput {
birthDate: DateTime!
email: String!
id: ID
}
input UserFilter {
every: UserWhereInput
none: UserWhereInput
some: UserWhereInput
}
input UserOrderByInput {
birthDate: OrderByArg
email: OrderByArg
id: OrderByArg
}
input UserWhereInput {
AND: [UserWhereInput!]
birthDate: DateTimeFilter
email: StringFilter
id: StringFilter
NOT: [UserWhereInput!]
OR: [UserWhereInput!]
posts: PostFilter
}
input UserWhereUniqueInput {
email: String
id: ID
}Thanks to that plugin, there's almost no boilerplate needed to expose full CRUD operations, including filters, pagination, and ordering capabilities, for Prisma models.
Getting started with Prisma
There are various ways for getting started with Prisma:
A huge thank you to our community 💚
We've been overwhelmed by the positive response to the Beta release in March and are excited to share today's General Availability with everyone! A huge thank you to everyone who has accompanied us on this journey!
Share what you are building on Slack and awesome-prisma
If you're new to Prisma, we'd love to see you around in our Slack! In case you're already using Prisma, let everyone know by posting what you build in the #showcase channel.
We're proud of our community of content creators who created lots of awesome articles and videos about Prisma! For an overview of the best Prisma resources, check out the awesome-prisma repo. And don't forget to create a PR with anything that's missing!
Join us at Prisma Day on June 25th and 26th for workshops and talks
After the successful premiere last year, we are excited to host another edition of Prisma Day on June 25th (workshops) and 26th (talks).
This year, we are going remote and are inviting everyone to join us for amazing talks around modern application development, best practices for database workflows and everything Prisma!