Deploy to Vercel
This guide takes you through the steps to set up and deploy a serverless application that uses Prisma to Vercel.
Vercel is a cloud platform that hosts static sites, serverless, and edge functions. You can integrate a Vercel project with a GitHub repository to allow you to deploy automatically when you make new commits.
We created an example application using Next.js you can use as a reference when deploying an application using Prisma to Vercel.
While our examples use Next.js, you can deploy other applications to Vercel. See Using Express with Vercel and Nuxt on Vercel as examples of other options.
Generate Prisma ORM during build
Vercel will automatically cache dependencies on deployment. For most applications, this will not cause any issues. However, for Prisma ORM, it may result in an outdated version of Prisma Client on a change in your Prisma schema. To avoid this issue, add prisma generate to the postinstall script of your application:
{
...
"scripts" {
"postinstall": "prisma generate"
}
...
}
This will re-generate Prisma Client at build time so that your deployment always has an up-to-date client.
If you see prisma: command not found errors during your deployment to Vercel, you are missing prisma in your dependencies. By default, prisma is a dev dependency and may need to be moved to be a standard dependency.
Another option to avoid an outdated Prisma Client is to use a custom output path and check your client into version control. This way each deployment is guaranteed to include the correct Prisma Client.
generator client {
provider = "prisma-client-js"
output = "./generated/client"
}
Add a separate database for preview deployments
By default, your application will have a single production environment associated with the main git branch of your repository. If you open a pull request to change your application, Vercel creates a new preview environment.
Vercel uses the DATABASE_URL environment variable you define when you import the project for both the production and preview environments. This causes problems if you create a pull request with a database schema migration because the pull request will change the schema of the production database.
To prevent this, use a second hosted database to handle preview deployments. Once you have that connection string, you can add a DATABASE_URL for your preview environment using the Vercel dashboard:
-
Click the Settings tab of your Vercel project.
-
Click Environment variables.
-
Add an environment variable with a key of
DATABASE_URLand select only the Preview environment option: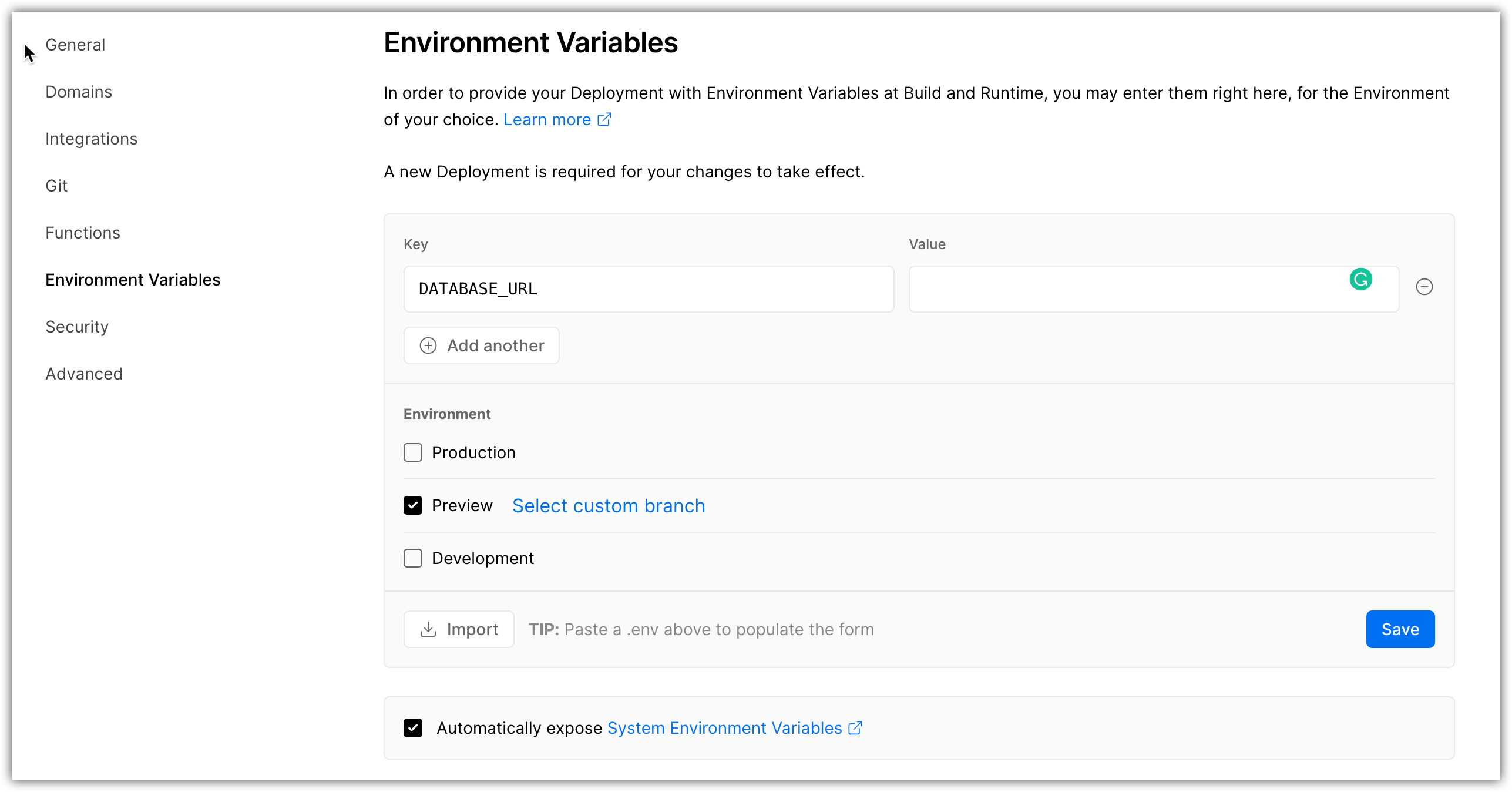
-
Set the value to the connection string of your second database:
postgresql://dbUsername:dbPassword@myhost:5432/mydb -
Click Save.
Connection pooling
When you use a Function-as-a-Service provider, like Vercel Serverless functions, every invocation may result in a new connection to your database. This can cause your database to quickly run out of open connections and cause your application to stall. For this reason, pooling connections to your database is essential.
You can use Accelerate for connection pooling, to reduce your Prisma Client bundle size, and to avoid cold starts.
For more information on connection management for serverless environments, refer to our connection management guide.