Why Prisma ORM?
On this page, you'll learn about the motivation for Prisma ORM and how it compares to other database tools like traditional ORMs and SQL query builders.
Working with relational databases is a major bottleneck in application development. Debugging SQL queries or complex ORM objects often consume hours of development time.
Prisma ORM makes it easy for developers to reason about their database queries by providing a clean and type-safe API for submitting database queries which returns plain old JavaScript objects.
TLDR
Prisma ORM's main goal is to make application developers more productive when working with databases. Here are a few examples of how Prisma ORM achieves this:
- Thinking in objects instead of mapping relational data
- Queries not classes to avoid complex model objects
- Single source of truth for database and application models
- Healthy constraints that prevent common pitfalls and anti-patterns
- An abstraction that makes the right thing easy ("pit of success")
- Type-safe database queries that can be validated at compile time
- Less boilerplate so developers can focus on the important parts of their app
- Auto-completion in code editors instead of needing to look up documentation
The remaining parts of this page discuss how Prisma ORM compares to existing database tools.
Problems with SQL, traditional ORMs and other database tools
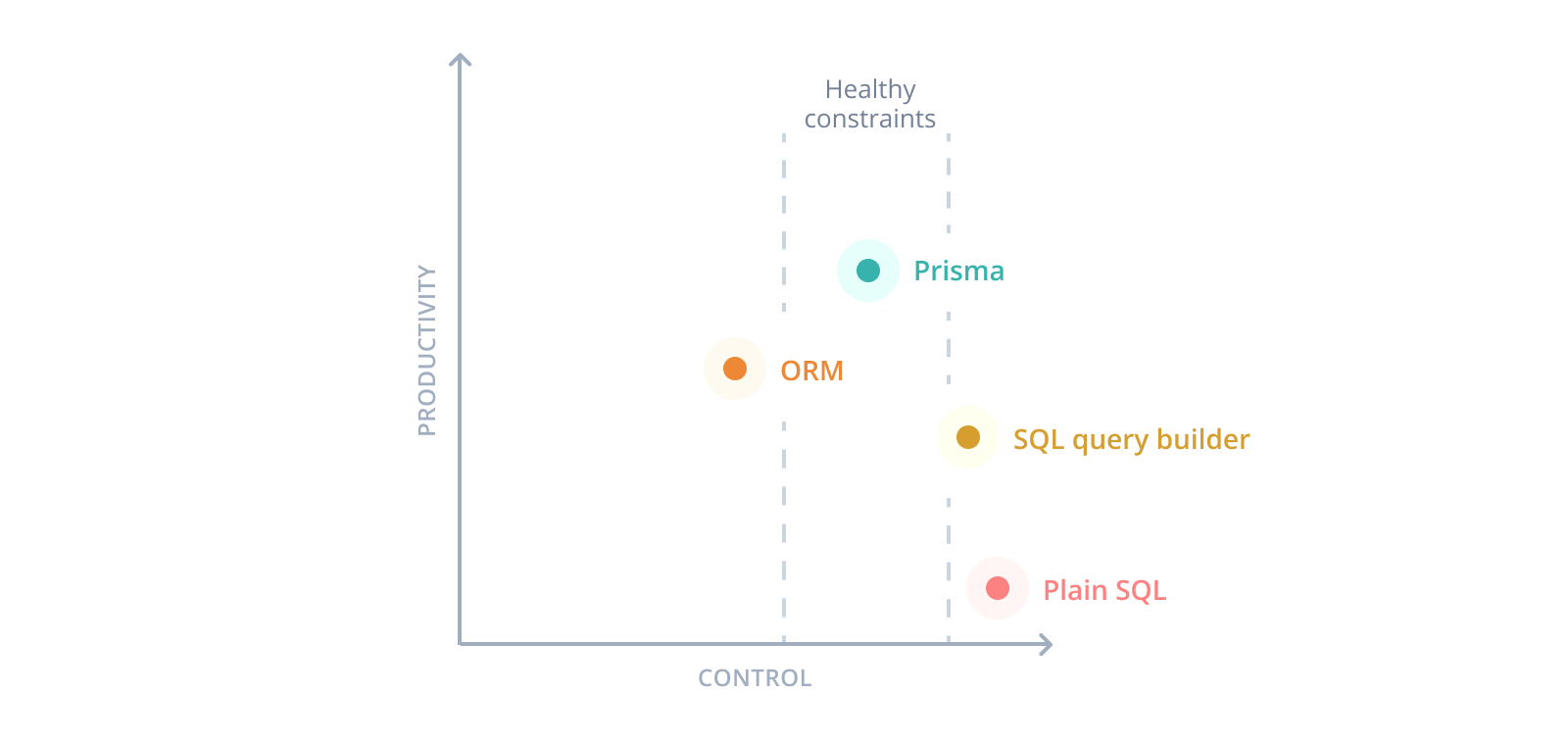
The main problem with the database tools that currently exist in the Node.js and TypeScript ecosystem is that they require a major tradeoff between productivity and control.
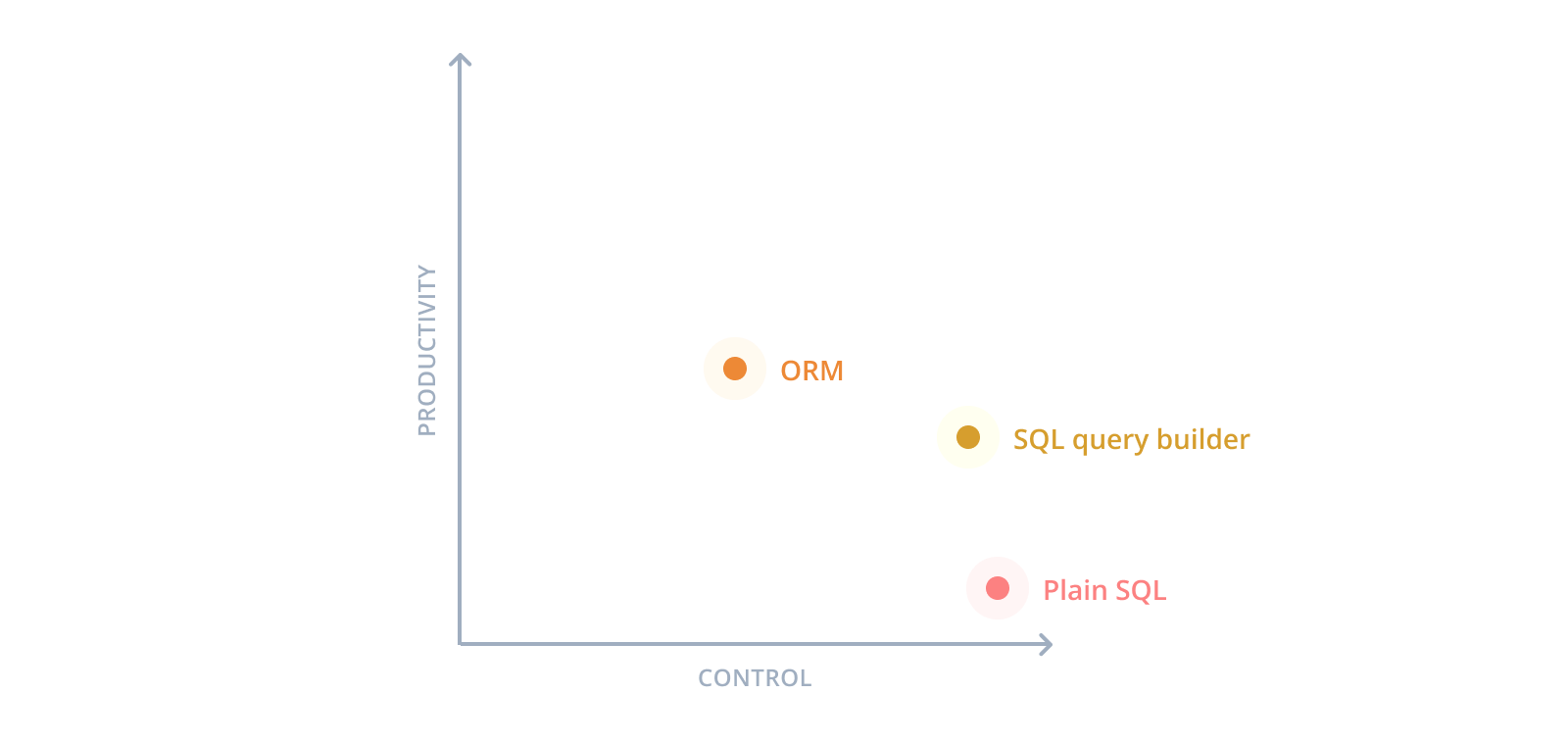
Raw SQL: Full control, low productivity
With raw SQL (e.g. using the native pg or mysql Node.js database drivers) you have full control over your database operations. However, productivity suffers as sending plain SQL strings to the database is cumbersome and comes with a lot of overhead (manual connection handling, repetitive boilerplate, ...).
Another major issue with this approach is that you don't get any type safety for your query results. Of course, you can type the results manually but this is a huge amount of work and requires major refactorings each time you change your database schema or queries to keep the typings in sync.
Furthermore, submitting SQL queries as plain strings means you don't get any autocompletion in your editors.
SQL query builders: High control, medium productivity
A common solution that retains a high level of control and provides better productivity is to use a SQL query builder (e.g. knex.js). These sort of tools provide a programmatic abstraction to construct SQL queries.
The biggest drawback with SQL query builders is that application developers still need to think about their data in terms of SQL. This incurs a cognitive and practical cost of translating relational data into objects. Another issue is that it's too easy to shoot yourself in the foot if you don't know exactly what you're doing in your SQL queries.
Traditional ORMs: Less control, better productivity
Traditional ORMs abstract away from SQL by letting you define your application models as classes, these classes are mapped to tables in the database.
"Object relational mappers" (ORMs) exist to bridge the gap between the programmers' friend (the object), and the database's primitive (the relation). The reasons for these differing models are as much cultural as functional: programmers like objects because they encapsulate the state of a single thing in a running program. Databases like relations because they better suit whole-dataset constraints and efficient access patterns for the entire dataset.
You can then read and write data by calling methods on the instances of your model classes.
This is way more convenient and comes closer to the mental model developers have when thinking about their data. So, what's the catch?
ORM represents a quagmire which starts well, gets more complicated as time passes, and before long entraps its users in a commitment that has no clear demarcation point, no clear win conditions, and no clear exit strategy.
As an application developer, the mental model you have for your data is that of an object. The mental model for data in SQL on the other hand are tables.
The divide between these two different representations of data is often referred to as the object-relational impedance mismatch. The object-relational impedance mismatch also is a major reason why many developers don't like working with traditional ORMs.
As an example, consider how data is organized and relationships are handled with each approach:
- Relational databases: Data is typically normalized (flat) and uses foreign keys to link across entities. The entities then need to be JOINed to manifest the actual relationships.
- Object-oriented: Objects can be deeply nested structures where you can traverse relationships simply by using dot notation.
This alludes to one of the major pitfalls with traditional ORMs: While they make it seem that you can simply traverse relationships using familiar dot notation, under the hood the ORM generates SQL JOINs which are expensive and have the potential to drastically slow down your application (one symptom of this is the n+1 problem).
To conclude: The appeal of traditional ORMs is the premise of abstracting away the relational model and thinking about your data purely in terms of objects. While the premise is great, it's based on the wrong assumption that relational data can easily be mapped to objects which leads to lots of complications and pitfalls.
Application developers should care about data – not SQL
Despite being developed in the 1970s(!), SQL has stood the test of time in an impressive manner. However, with the advancement and modernization of developers tools, it's worth asking if SQL really is the best abstraction for application developers to work with?
After all, developers should only care about the data they need to implement a feature and not spend time figuring out complicated SQL queries or massaging query results to fit their needs.
There's another argument to be made against SQL in application development. The power of SQL can be a blessing if you know exactly what you're doing, but its complexity can be a curse. There are a lot of anti-patterns and pitfalls that even experienced SQL users struggle to anticipate, often at the cost of performance and hours of debugging time.
Developers should be able to ask for the data they need instead of having to worry about "doing the right thing" in their SQL queries. They should be using an abstraction that makes the right decisions for them. This can mean that the abstraction imposes certain "healthy" constraints that prevent developers from making mistakes.
Prisma ORM makes developers productive
Prisma ORM's main goal is to make application developers more productive when working with databases. Considering the tradeoff between productivity and control again, this is how Prisma ORM fits in: