Engines
From a technical perspective, Prisma Client consists of three major components:
- JavaScript client library
- TypeScript type definitions
- A query engine
All of these components are located in the generated .prisma/client folder after you ran prisma generate.
This page covers relevant technical details about the query engine.
As of v6.7.0, Prisma ORM has the queryCompiler Preview feature.
When enabled, your Prisma Client will be generated without a Rust-based query engine binary:
generator client {
provider = "prisma-client-js"
previewFeatures = ["queryCompiler", "driverAdapters"]
}
Note that the driver adapters Preview feature is required alongside queryCompiler.
You can learn more about the change on our blog.
Prisma engines
At the core of each module, there typically is a Prisma engine that implements the core set of functionality. Engines are implemented in Rust and expose a low-level API that is used by the higher-level interfaces.
A Prisma engine is the direct interface to the database, any higher-level interfaces always communicate with the database through the engine-layer.
As an example, Prisma Client connects to the query engine in order to read and write data in a database:
Using custom engine libraries or binaries
By default, all engine files are automatically downloaded into the node_modules/@prisma/engines folder when you install or update prisma, the Prisma CLI package. The query engine is also copied to the generated Prisma Client when you call prisma generate.
You might want to use a custom library or binary file if:
- Automated download of engine files is not possible.
- You have created your own engine library or binary for testing purposes, or for an OS that is not officially supported.
Use the following environment variables to specify custom locations for your binaries:
PRISMA_QUERY_ENGINE_LIBRARY(Query engine, library)PRISMA_QUERY_ENGINE_BINARY(Query engine, binary)PRISMA_SCHEMA_ENGINE_BINARY(Schema engine)PRISMA_MIGRATION_ENGINE_BINARY(Migration engine)PRISMA_INTROSPECTION_ENGINE_BINARY(Introspection engine)
Setting the environment variable
You can define environment variables globally on your machine or in the .env file.
a) The .env file
Add the environment variable to the .env file.
- Linux, Unix, macOS
- Windows
PRISMA_QUERY_ENGINE_BINARY=custom/my-query-engine-unix
PRISMA_QUERY_ENGINE_BINARY=c:\custom\path\my-query-engine-binary.exe
Note: It is possible to use an
.envfile in a location outside theprismafolder.
b) Global environment variable
Run the following command to set the environment variable globally (in this example, PRISMA_QUERY_ENGINE_BINARY):
- Linux, Unix, macOS
- Windows
export PRISMA_QUERY_ENGINE_BINARY=/custom/my-query-engine-unix
set PRISMA_QUERY_ENGINE_BINARY=c:\custom\my-query-engine-windows.exe
Test your environment variable
Run the following command to output the paths to all binaries:
npx prisma -v
The output shows that the query engine path comes from the PRISMA_QUERY_ENGINE_BINARY environment variable:
- Linux, Unix, macOS
- Windows
Current platform : darwin
Query Engine : query-engine d6ff7119649922b84e413b3b69660e2f49e2ddf3 (at /custom/my-query-engine-unix)
Migration Engine : migration-engine-cli d6ff7119649922b84e413b3b69660e2f49e2ddf3 (at /myproject/node_modules/@prisma/engines/migration-engine-unix)
Introspection Engine : introspection-core d6ff7119649922b84e413b3b69660e2f49e2ddf3 (at /myproject/node_modules/@prisma/engines/introspection-engine-unix)
Current platform : windows
Query Engine : query-engine d6ff7119649922b84e413b3b69660e2f49e2ddf3 (at c:\custom\my-query-engine-windows.exe)
Migration Engine : migration-engine-cli d6ff7119649922b84e413b3b69660e2f49e2ddf3 (at c:\myproject\node_modules\@prisma\engines\migration-engine-windows.exe)
Introspection Engine : introspection-core d6ff7119649922b84e413b3b69660e2f49e2ddf3 (at c:\myproject\node_modules\@prisma\engines\introspection-engine-windows.exe)
Hosting engines
The PRISMA_ENGINES_MIRROR environment variable allows you to host engine files via a private server, AWS bucket or other cloud storage.
This can be useful if you have a custom OS that requires custom-built engines.
PRISMA_ENGINES_MIRROR=https://my-aws-bucket
The query engine file
The query engine file is different for each operating system. It is named query-engine-PLATFORM or libquery_engine-PLATFORM where PLATFORM corresponds to the name of a compile target. Query engine file extensions depend on the platform as well. As an example, if the query engine must run on a Darwin operating system such as macOS Intel, it is called libquery_engine-darwin.dylib.node or query-engine-darwin. You can find an overview of all supported platforms here.
The query engine file is downloaded into the runtime directory of the generated Prisma Client when prisma generate is called.
Note that the query engine is implemented in Rust. The source code is located in the prisma-engines repository.
The query engine at runtime
By default, Prisma Client loads the query engine as a Node-API library. You can alternatively configure Prisma to use the query engine compiled as an executable binary, which is run as a sidecar process alongside your application. The Node-API library approach is recommended since it reduces the communication overhead between Prisma Client and the query engine.

The query engine is started when the first Prisma Client query is invoked or when the $connect() method is called on your PrismaClient instance. Once the query engine is started, it creates a connection pool and manages the physical connections to the database. From that point onwards, Prisma Client is ready to send queries to the database (e.g. findUnique(), findMany, create, ...).
The query engine is stopped and the database connections are closed when $disconnect() is invoked.
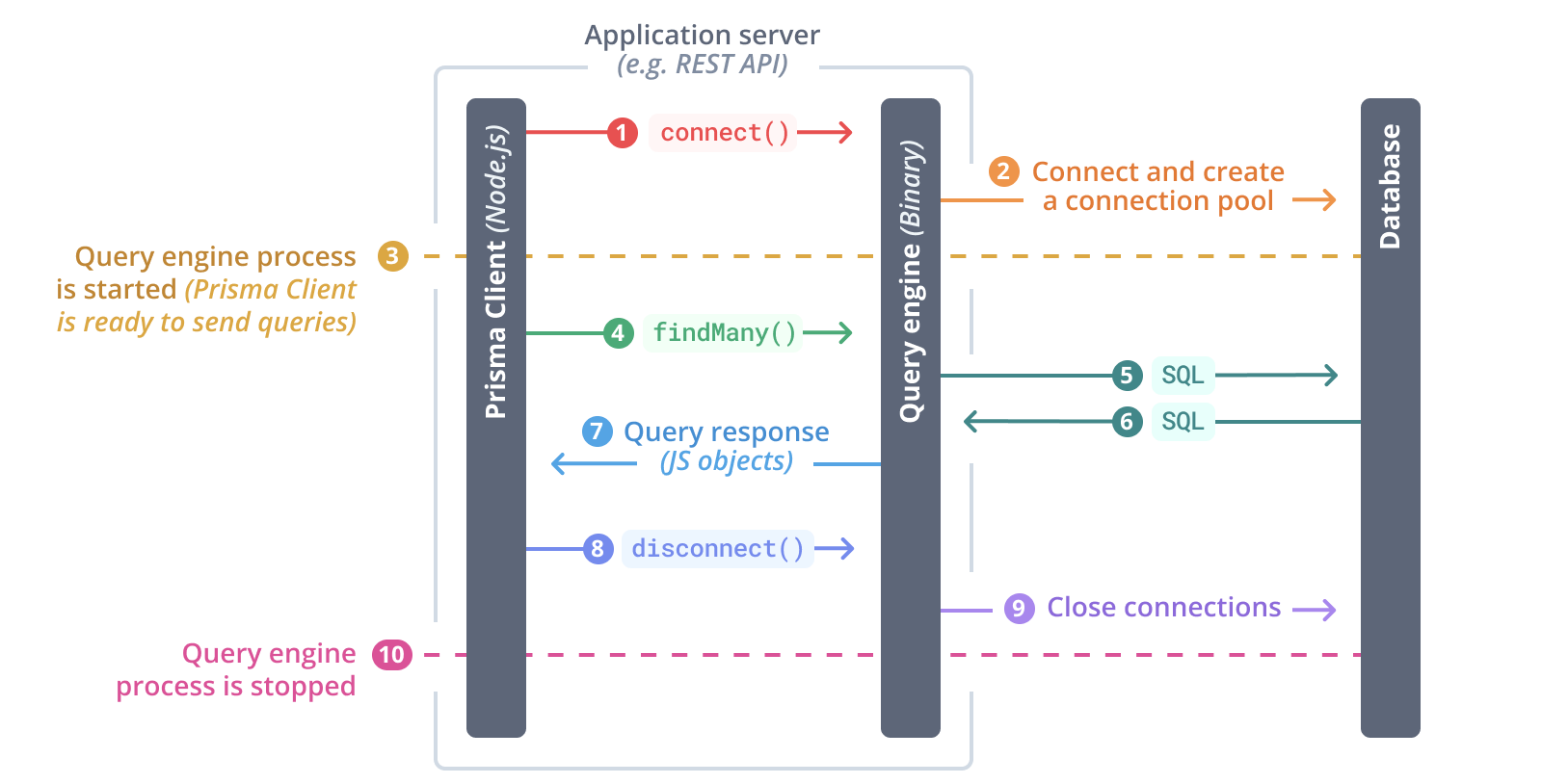
The following diagram depicts a "typical flow":
$connect()is invoked on Prisma Client- The query engine is started
- The query engine establishes connections to the database and creates connection pool
- Prisma Client is now ready to send queries to the database
- Prisma Client sends a
findMany()query to the query engine - The query engine translates the query into SQL and sends it to the database
- The query engine receives the SQL response from the database
- The query engine returns the result as plain old JavaScript objects to Prisma Client
$disconnect()is invoked on Prisma Client- The query engine closes the database connections
- The query engine is stopped
Responsibilities of the query engine
The query engine has the following responsibilities in an application that uses Prisma Client:
- manage physical database connections in connection pool
- receive incoming queries from the Prisma Client Node.js process
- generate SQL queries
- send SQL queries to the database
- process responses from the database and send them back to Prisma Client
Debugging the query engine
You can access the logs of the query engine by setting the DEBUG environment variable to engine:
export DEBUG="engine"
You can also get more visibility into the SQL queries that are generated by the query engine by setting the query log level in Prisma Client:
const prisma = new PrismaClient({
log: ['query'],
})
Learn more about Debugging and Logging.
Configuring the query engine
Defining the query engine type for Prisma Client
As described above the default query engine is a Node-API library that is loaded into Prisma Client, but there is also an alternative implementation as an executable binary that runs in its own process. You can configure the query engine type by providing the engineType property to the Prisma Client generator:
generator client {
provider = "prisma-client-js"
engineType = "binary"
}
Valid values for engineType are binary and library. You can also use the environment variable PRISMA_CLIENT_ENGINE_TYPE instead.
- Until Prisma 3.x the default and only engine type available was
binary, so there was no way to configure the engine type to be used by Prisma Client and Prisma CLI. - From versions 2.20.0 to 3.x the
libraryengine type was available and used by default by activating the preview feature flag "nApi" or using thePRISMA_FORCE_NAPI=trueenvironment variable.
Defining the query engine type for Prisma CLI
Prisma CLI also uses its own query engine for its own needs. You can configure it to use the binary version of the query engine by defining the environment variable PRISMA_CLI_QUERY_ENGINE_TYPE=binary.