What's new in Prisma? (Q2/22)

Learn about everything in the Prisma ecosystem and community from April to July 2022.
Overview
- Releases & new features
- Features promoted to General Availability
- New Preview features
- New Prisma Client APIs:
findUniqueOrThrowandfindFirstOrThrow - General improvements
- Prisma Client for Data Proxy improvements
- Defaults values for scalar lists (arrays)
- Improved default support for embedded documents in MongoDB
- Explicit unique constraints for 1 relations
- Removed support for usage of
referenceson implicit m relations - Enforcing uniqueness of referenced fields in the
referencesargument in 1 and 1 relations for MySQL - Removal of undocumented support for the
typealias - Removal of the
sqliteprotocol for SQLite URLs - Better grammar for string literals
- Deprecating
rejectOnNotFound - Fix rounding errors on big numbers in SQLite
DbNull,JsonNull, andAnyNullare now objects- Prisma Studio updates
- Dropped support for Node 12
- New default sizes for statement cache
- Renaming of
@prisma/sdknpm package to@prisma/internals - Removal of the internal
schemaproperty from the generated Prisma Client - Fixed memory leaks and CPU usage in Prisma Client
- Community
- Videos, livestreams & more
- We are hiring
- What's Next
Releases & new features
Our engineers have been working hard, issuing new releases with many improvements and new features. You can stay up-to-date about all upcoming features on our roadmap.
We once shipped a regression (and fixed it quickly, of course!), a new major version, Prisma 4 coupled with breaking changes, promoted a ton of features to General Availability, released a couple of new Preview features, and improvements in the last three months.
In case you missed it, we held a livestream walking through issues you may run into while upgrading to Prisma 4 and how to fix them!
Features promoted to General Availability
Improved support for indexes
We introduced extendedIndexes in 3.5.0 and promoted it to General Availability in 4.0.0.
You can now configure indexes in your Prisma schema with the @@index attribute to define the kind of index that should be created in your database. You can configure the following indexes in your Prisma Schema:
Refer to our docs to learn how you can configure indexes in your Prisma schema and the supported indexes for the different databases.
⚠️ Breaking change: If you previously configured the index properties at the database level, refer to the upgrade guide for a detailed explanation and steps to follow.
Filtering JSON values
This feature allows you to filter rows by the data inside a Json type in your schema. From 4.0.0, this feature was marked ready for production.
The filterJson Preview feature has been around since May 2021.
const getUsers = await prisma.user.findMany({
where: {
petMeta: {
path: ['cats', 'fostering'],
array_contains: ['Fido'],
},
},
})Learn more in our documentation.
Improved raw query support
We introduced this feature in 3.14.0 and marked it production ready in 4.0.0. This change introduces two major improvements (both breaking) when working with raw queries with Prisma:
⚠️ Breaking change: To learn how you can smoothly upgrade to version 4.0.0, refer to our upgrade guide: Raw query type mapping: scalar values are now deserialized as their correct JavaScript types and Raw query mapping: PostgreSQL type-casts.
CockroachDB support
The CockroachDB connector was stabilized and moved to General Availability in 3.14.0. The connector was built in joined efforts with the team at Cockroach Labs and comes with full Prisma Client and Prisma Migrate support.
If you're upgrading from Prisma version 3.9.0+ or the PostgreSQL connector, you can now run npx prisma db pull and review the changes to your schema. To learn more about CockroachDB-specific native types we support, refer to our docs.
To learn more about the connector and how it differs from PostgreSQL, head to our documentation.
Improved Prisma Migrate DX with two new commands
We released two new Preview CLI commands in version 3.9.0 – prisma migrate diff and prisma db execute – to enable our users to create and understand migrations and build their workflows using the commands.
The commands were moved to Generally Availability in 3.13.0 and can now be used without the --preview-feature flag. 🎉
The prisma migrate diff command creates a diff of your database schema, Prisma schema file, or the migration history. All you have to do is feed the command with a schema from state and a schema to state to get an SQL script or human-readable diff.
In addition to prisma migrate diff, prisma db execute is used to execute SQL scripts against a database. You can directly run prisma migrate diff's output using prisma db execute --stdin.
Both commands are non-interactive, so it's possible to build many new workflows such as forward and backward migrations with some automation tooling. Take a look at our documentation to learn some of the popular workflows these commands unlock:
- Fixing failed migrations
- Squashing migrations
- Generating down migrations
- Command reference for
migrate diffanddb execute
Let us know what tools, automation, and scripts you build using these commands.
New Preview features
Prisma Client Metrics
We introduced Prisma Client metrics in 3.15.0 to allow you to monitor how Prisma Client interacts with your database. Metrics expose a set of counters, gauges, and histograms that can be labeled and piped into an external monitoring system like Prometheus or StatsD.
You can use metrics in your project to help diagnose how your application's number of idle and active connections changes with counters, gauges, and histograms.
To get started using metrics in your project, enable the Preview feature flag in your Prisma schema:
generator client {
provider = "prisma-client-js"
previewFeatures = ["metrics"]
}You can then get started using metrics in your project after regenerating Prisma Client:
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
const metrics = await prisma.$metrics.json()
console.log(metrics)To learn more, check out the metrics documentation. Give it a try and let us know what you think.
Ordering by first and last nulls
We also added support for choosing how to sort null values in a query in 4.1.0.
You can get started by enabling the orderByNulls Preview feature flag in your Prisma schema:
generator client {
provider = "prisma-client-js"
previewFeatures = ["orderByNulls"]
}Next, regenerate Prisma Client to get access to the new fields you can use to order null values:
await prisma.post.findMany({
orderBy: {
updatedAt: {
sort: 'asc',
nulls: 'last'
},
},
})Learn more in our documentation and don't hesitate to share your feedback in this issue.
New Prisma Client APIs: findUniqueOrThrow and findFirstOrThrow
We introduced two new APIs to Prisma Client in Prisma 4:
findUniqueOrThrow– retrieves a single record as findUnique but throws a RecordNotFound exception when no record is not foundfindFirstOrThrow– retrieves the first record in a list as findFirst but throws a RecordNotFound exception when no record is found
Here's an example of usage of the APIs:
const user = await prisma.user.findUniqueOrThrow({
where: {
email: "alice@prisma.io",
},
})
user.email // You don't need to check if the user is nullThe APIs will be convenient for scripts API routes where you're already handling exceptions and want to fail fast.
Refer to the API reference in our docs to learn how findUniqueOrThrow and findFirstOrThrow differ from findUnique and findFirst respectively.
General improvements
Prisma Client for Data Proxy improvements
The Prisma Data Proxy provides connection management and pooling for database connections for efficiently scaling database connections in serverless environments. The Prisma Client for Data Proxy provides support for connecting to the Prisma Data Proxy using HTTP.
Here's an illustration explaining the architecture of the Data Proxy in your application:
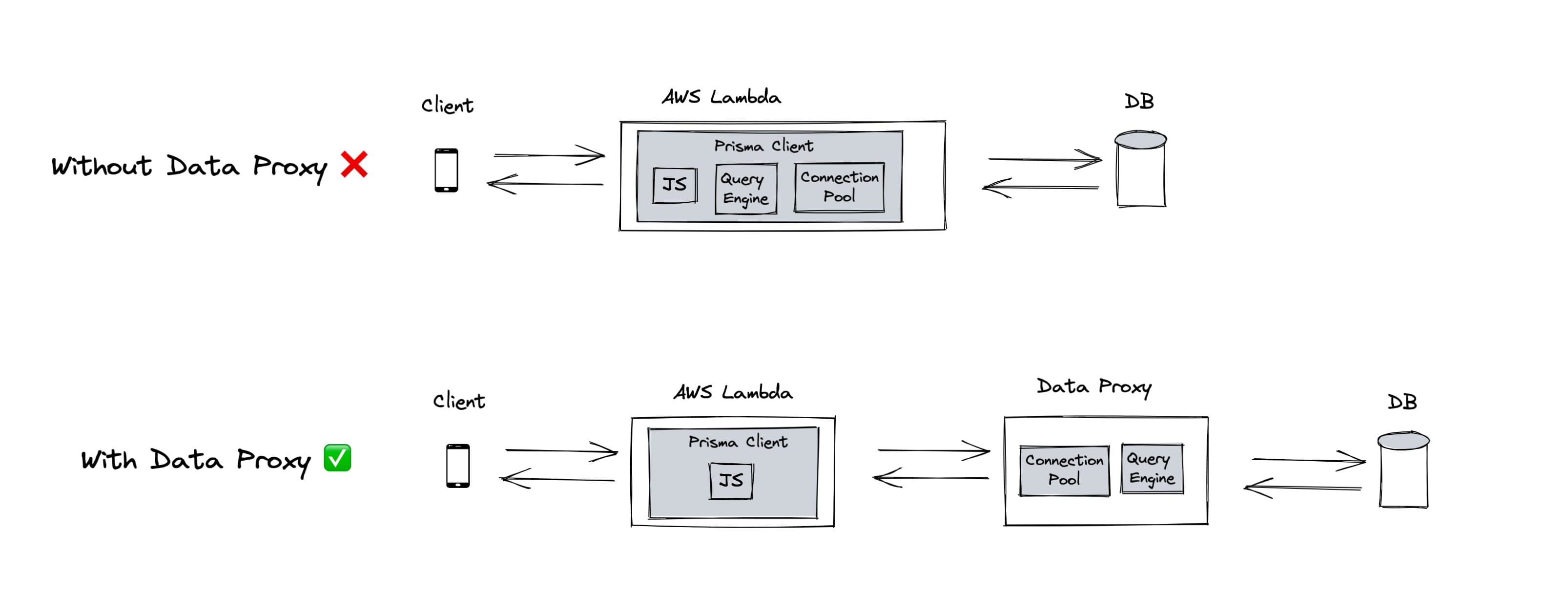
We introduced Prisma Client for Data Proxy in version 3.3.0 and we have been shipping features, fixes and improvements.
From 3.15.0, we shipped the following changes:
- Improving the Prisma Client for Data Proxy generation step.
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
- previewFeatures = ["dataProxy"]
}You can now generate Prisma Client for the Data Proxy using the --data-proxy flag:
npx prisma generate --data-proxy- Running Prisma Client using the Data Proxy in Cloudflare Workers and Edge environments.
You can now use the @prisma/client/edge instead of @prisma/client in your application.
import { PrismaClient } from '@prisma/client/edge'To learn more, check out our documentation.
Defaults values for scalar lists (arrays)
Prisma 4 now introduced support for defining default values for scalar lists (arrays) in the Prisma schema.
You can define default scalar lists as follows:
model User {
id Int @id @default(autoincrement())
posts Post[]
favoriteColors String[] @default(["red", "blue", "green"])
}To learn more about default values for scalar lists, refer to our docs.
⚠️ Breaking change: Refer to the upgrade guide for a detailed explanation and steps to follow.
Improved default support for embedded documents in MongoDB
From 4.0.0, you can now set default values on embedded documents using the @default attribute. Prisma will provide the specified default value on reads if a field is not defined in the database.
You can define default values for embedded documents in your Prisma schema as follows:
model Product {
id String @id @default(auto()) @map("_id") @db.ObjectId
name String @unique
photos Photo[]
}
type Photo {
height Int @default(200)
width Int @default(100)
url String
}Refer to our docs to learn more on default values for required fields on composite types.
⚠️ Breaking change: Refer to our upgrade guide for detailed explanation and steps when working with default fields on composite types in MongoDB from version 4.0.0.
Explicit unique constraints for 1 relations
From Prisma 4, 1
relations must be marked with the@unique attribute on the side of the relationship that contains the foreign key.
Previously, the relation fields were implicitly treated as unique under the hood. The field was also added explicitly when npx prisma format was run.
model User {
id Int @id @default(autoincrement())
profile Profile? @relation(fields: [profileId], references: [id])
profileId Int? @unique // <-- include this explicitly
}
model Profile {
id Int @id @default(autoincrement())
user User?
}⚠️ Breaking change: Refer to our upgrade path for a detailed explanation and steps to follow.
Removed support for usage of references on implicit m relations
Prisma 4 removed the usage of the references argument, which was previously optional when using m
diff
model Post {
id Int @id @default(autoincrement())
- categories Category[] @relation("my-relation", references: [id])
+ categories Category[] @relation("my-relation")
}
model Category {
id Int @id @default(autoincrement())
- posts Post[] @relation("my-relation", references: [id])
+ posts Post[] @relation("my-relation")
}This is because the only valid value for references was id, so removing this argument clarifies what can and cannot be changed.
Refer to our docs to learn more about implicit m relations.
⚠️ Breaking change: Refer to the upgrade guide for a detailed explanation and steps to follow.
Enforcing uniqueness of referenced fields in the references argument in 1 and 1 relations for MySQL
Prisma now enforces that the field on the references side of a @relation is unique when working with MySQL from 4.0.0.
To fix this, add the @unique or @id attributes to foreign key fields in your Prisma schema.
⚠️ Breaking change: To learn how to upgrade to version 4.0.0, refer to our upgrade guide.
Removal of undocumented support for the type alias
With Prisma 4, we're deprecating the type keyword for string aliasing. The type keyword will now be exclusively used to define MongoDB's embedded documents.
We encourage you to remove any usage of the type keyword from your Prisma schema for type aliasing.
Removal of the sqlite protocol for SQLite URLs
We dropped support of the sqlite:// URL prefix for SQLite from Prisma 4. We encourage you to use the file:// prefix when working with SQLite.
Better grammar for string literals
From Prisma 4, string literals in the Prisma schema need to follow the same rules as strings in JSON. That changes mostly the escaping of some special characters.
You can find more details on the specification here:
To fix this, resolve the validation errors in your Prisma schema or run npx prisma db pull to get the current values from the database.
⚠️ Breaking change: To learn how to update your existing schema, refer to the upgrade guide.
Deprecating rejectOnNotFound
We deprecated the rejectOnNotFound parameter in favor of the new findUniqueOrThrow and findFirstOrThrow Prisma Client APIs in 4.0.0.
We expect the new APIs to be easier to understand and more type-safe.
Refer to the findUniqueOrThrow and findFirstOrThrow docs to learn how you can upgrade.
Fix rounding errors on big numbers in SQLite
SQLite is a loosely-typed database. While Prisma will prevent you from inserting values larger than integers, nothing prevents SQLite from accepting big numbers. These manually inserted big numbers cause rounding errors when queried.
Prisma will now check numbers in the query's response to verify they fit within the boundaries of an integer. If a number does not fit, Prisma will throw a P2023 error:
Inconsistent column data: Conversion failed:
Value 9223372036854775807 does not fit in an INT column,
try migrating the 'int' column type to BIGINTTo learn more on rounding errors with big numbers on SQLite, refer to our docs.
DbNull, JsonNull, and AnyNull are now objects
Previously, Prisma.DbNull, Prisma.JsonNull, and Prisma.AnyNull used to be implemented using string constants. This meant their types overlapped with regular string data that could be stored in JSON fields.
We've now made them special objects instead that don't overlap with string types.
Before we resolved this in Prisma 4, DbNull was checked as a string so you could accidentally check for a null as follows:
import { PrismaClient, Prisma } from '@prisma/client'
const prisma = new PrismaClient()
const dbNull = "DbNull" // this string could come from anywhere!
await prisma.log.findMany({
data: {
meta: dbNull,
},
})Prisma 4 resolves this using constants guaranteed to be unique to prevent this kind of inconsistent queries.
You can now read, write, and filter JSON fields as follows:
import { PrismaClient, Prisma } from '@prisma/client'
const prisma = new PrismaClient()
await prisma.log.create({
data: {
meta: Prisma.DbNull,
},
})We recommend you double-check queries that use Json after upgrading to Prisma 4. Ensure that you use the Prisma.DbNull, Prisma.JsonNull, and Prisma.AnyNull constants from Prisma Client, not string literals.
Refer to the Prisma 4 upgrade guide in case you run into any type errors.
Prisma Studio updates
We've refined the experience when working with Prisma Studio with the following changes:
- An always visible panel and functionality to clear all all filters at once
- Improved relationship model view with more visible buttons
- Including a confirmation dialog before deleting records
- Adding a shortcut copy action on a cell – CMD + C on MacOS or Ctrl + C on Windows/ Linux
Dropped support for Node 12
The minimum version of Node.js Prisma will support is 14.17.x from Prisma 4.0.0. If you're using an earlier version of Node.js, you will need to update your Node.js version.
Refer to our system requirements for the minimum versions Prisma requires
New default sizes for statement cache
Before 4.0.0, we had inconsistent and large default values (500 for PostgreSQL and 1000 for MySQL) for the statement_cache_size. The new shared default value is 100.
If the new default doesn't work for you, please create an issue and use the statement_cache_size=x parameter in your connection string to override the default value.
Renaming of @prisma/sdk npm package to @prisma/internals
From 4.0.0, the internal package @prisma/sdk will be available under the new, more explicit name @prisma/internals.
We do not provide API guarantees for @prisma/internals as it might need to introduce breaking changes from time to time and does not follow semantic versioning.
This is technically not a breaking change as usage of the @prisma/sdk package is neither documented nor supported.
If you're using @prisma/sdk (now @prisma/internals), it would be helpful if you could help us understand where, how, and why you are using it by giving us feedback in this GitHub discussion. Your feedback will be valuable to us in defining a better API.
Removal of the internal schema property from the generated Prisma Client
We've removed the internal Prisma.dmmf.schema to reduce the size of Prisma Client generated and improve boot times in Prisma 4.
To access the schema property, you can use the getDmmf() method from @prisma/internals.
Fixed memory leaks and CPU usage in Prisma Client
We fixed the following issues in 4.1.0 experienced when setting up and tearing down Prisma Client while running tests:
- Prisma Client now correctly releases memory on Prisma Client instances that are no longer being used. Learn more in this GitHub issue
- Reduced CPU usage spikes when disconnecting Prisma Client instances while using Prisma Client. You can learn more in this GitHub issue
These fixes will allow you to run your tests a little faster!
Community
We wouldn't be where we are today without our amazing community of developers. Our Slack has almost 50k members and is a great place to ask questions, share feedback and initiate discussions around Prisma.
Prisma Day 2022
Prisma Day was a huge success, and we want to thank everyone who attended and helped make it a great experience! It was a two-day conference with talks and workshops by members of the Prisma community.
This was our 4th Prisma Day. We had 14 amazing talks and 4 workshops.
In case you missed the event, you can watch all the talks and workshops on our YouTube channel
Meetups
Series B funding
We raised our $40M series B funding round to build the Application Data Platform for development teams and organizations. This funding will also allow us to continue to significantly invest in the development of the open-source ORM to add new features and make the developer experience even better.
You can learn more about it in this blog post.
Prisma FOSS Fund
We started a fund to support independent free and open source software teams. Each month, we will donate $5,000 to a selected project to maintain its work and continue its development.
You can learn more about the FOSS Fund initiative in this blog post.
Videos, livestreams & more
What's new in Prisma
Every other Thursday, our developer advocates, Nikolas Burk, Alex Ruheni, Tasin Ishmam, and Sabin Adams, discuss the latest Prisma release and other news from the Prisma ecosystem and community. If you want to travel back in time and learn about a past release, you can find all of the shows from this quarter here:
Videos
We published several videos this quarter on our YouTube channel. Check them out, and subscribe to not miss out on future videos.
- Build a Fullstack App with Remix, Prisma & MongoDB — Workshop
- A Practical Introduction to Prisma & MongoDB — Workshop
- Build A Fullstack App with Remix, Prisma & MongoDB — Playlist
- Prisma & MongoDB Live Office Hours
- Amplication — an interview with Yuval Hazaz
Written content
In this quarter, we published several articles on our blog:
- Database access on the Edge with Next.js, Vercel & Prisma Data Proxy
- Announcing the Prisma FOSS Fund
- Building a REST API with NestJS and Prisma: Input Validation & Transformation
- The Prisma Data Platform is now Generally Available
- Building a REST API with NestJS and Prisma
- Prisma Support for CockroachDB Is Production Ready 🪳
- How Prisma helps Amplication evolutionize backend development
- Build A Fullstack App with Remix, Prisma & MongoDB (series)
We also published several technical articles on the Data Guide that you might find useful:
- What is MongoDB?
- Introduction to MongoDB connection URIs
- Comparing relational and document databases
- What are document databases?
- How MongoDB encrypts data
- Introduction to MongoDB database tools & utilities
- How to sort query results in MongoDB
- Working with dates and times in MongoDB
- Introduction to OLAP and OLTP
- How microservices and monoliths impact the database
- Introduction to database caching
We are hiring
Also, we're hiring for various roles! If you're interested in joining us, check out our jobs page.
What's Next
The best places to stay up-to-date about what we are currently working on are our GitHub issues and our public roadmap.
You can also engage in conversations in our Slack channel and start a discussion on GitHub or join one of the many Prisma meetups around the world.
Keep reading

See Your Migration History in Prisma Studio
The Prisma Studio Migrations view shows every applied Prisma Next migration as a timeline with a visual diff, the executed SQL, and a schema diff.



Your agent can now provision Prisma Postgres through Stripe
Add a Prisma Postgres database to your Stripe project with one command: spending limits out of the box, plan changes from the CLI you already use.

Build your next app with Prisma
Start free. Scale when you’re ready.