Relations
A relation is a connection between two models in the Prisma schema. For example, there is a one-to-many relation between User and Post because one user can have many blog posts.
The following Prisma schema defines a one-to-many relation between the User and Post models. The fields involved in defining the relation are highlighted:
- Relational databases
- MongoDB
model User {
id Int @id @default(autoincrement())
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
author User @relation(fields: [authorId], references: [id])
authorId Int // relation scalar field (used in the `@relation` attribute above)
title String
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
posts Post[]
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId // relation scalar field (used in the `@relation` attribute above)
title String
}
At a Prisma ORM level, the User / Post relation is made up of:
- Two relation fields:
authorandposts. Relation fields define connections between models at the Prisma ORM level and do not exist in the database. These fields are used to generate Prisma Client. - The scalar
authorIdfield, which is referenced by the@relationattribute. This field does exist in the database - it is the foreign key that connectsPostandUser.
At a Prisma ORM level, a connection between two models is always represented by a relation field on each side of the relation.
Relations in the database
Relational databases
The following entity relationship diagram defines the same one-to-many relation between the User and Post tables in a relational database:
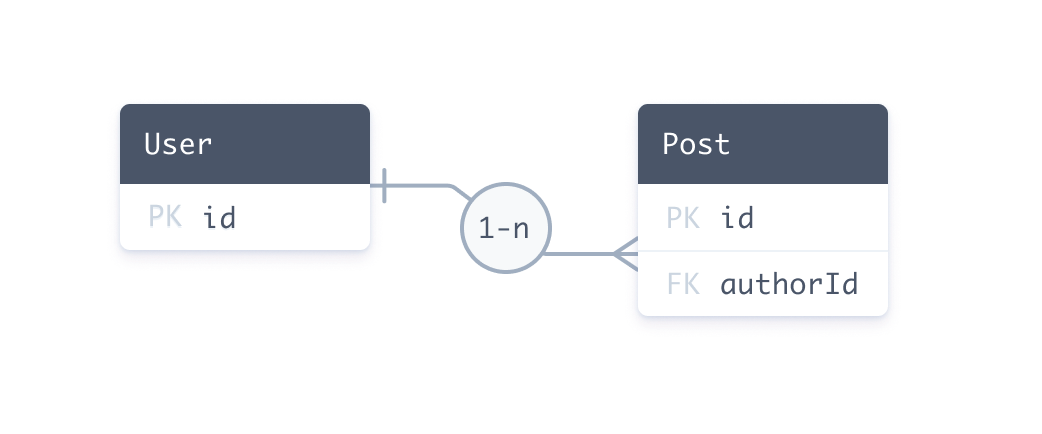
In SQL, you use a foreign key to create a relation between two tables. Foreign keys are stored on one side of the relation. Our example is made up of:
- A foreign key column in the
Posttable namedauthorId. - A primary key column in the
Usertable namedid. TheauthorIdcolumn in thePosttable references theidcolumn in theUsertable.
In the Prisma schema, the foreign key / primary key relationship is represented by the @relation attribute on the author field:
author User @relation(fields: [authorId], references: [id])
Note: Relations in the Prisma schema represent relationships that exist between tables in the database. If the relationship does not exist in the database, it does not exist in the Prisma schema.
MongoDB
For MongoDB, Prisma ORM currently uses a normalized data model design, which means that documents reference each other by ID in a similar way to relational databases.
The following document represents a User (in the User collection):
{ "_id": { "$oid": "60d5922d00581b8f0062e3a8" }, "name": "Ella" }
The following list of Post documents (in the Post collection) each have a authorId field which reference the same user:
[
{
"_id": { "$oid": "60d5922e00581b8f0062e3a9" },
"title": "How to make sushi",
"authorId": { "$oid": "60d5922d00581b8f0062e3a8" }
},
{
"_id": { "$oid": "60d5922e00581b8f0062e3aa" },
"title": "How to re-install Windows",
"authorId": { "$oid": "60d5922d00581b8f0062e3a8" }
}
]
This data structure represents a one-to-many relation because multiple Post documents refer to the same User document.
@db.ObjectId on IDs and relation scalar fields
If your model's ID is an ObjectId (represented by a String field), you must add @db.ObjectId to the model's ID and the relation scalar field on the other side of the relation:
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
posts Post[]
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId // relation scalar field (used in the `@relation` attribute above)
title String
}
Relations in Prisma Client
Prisma Client is generated from the Prisma schema. The following examples demonstrate how relations manifest when you use Prisma Client to get, create, and update records.
Create a record and nested records
The following query creates a User record and two connected Post records:
const userAndPosts = await prisma.user.create({
data: {
posts: {
create: [
{ title: 'Prisma Day 2020' }, // Populates authorId with user's id
{ title: 'How to write a Prisma schema' }, // Populates authorId with user's id
],
},
},
})
In the underlying database, this query:
- Creates a
Userwith an auto-generatedid(for example,20) - Creates two new
Postrecords and sets theauthorIdof both records to20
Retrieve a record and include related records
The following query retrieves a User by id and includes any related Post records:
const getAuthor = await prisma.user.findUnique({
where: {
id: "20",
},
include: {
posts: true, // All posts where authorId == 20
},
});
In the underlying database, this query:
- Retrieves the
Userrecord with anidof20 - Retrieves all
Postrecords with anauthorIdof20
Associate an existing record to another existing record
The following query associates an existing Post record with an existing User record:
const updateAuthor = await prisma.user.update({
where: {
id: 20,
},
data: {
posts: {
connect: {
id: 4,
},
},
},
})
In the underlying database, this query uses a nested connect query to link the post with an id of 4 to the user with an id of 20. The query does this with the following steps:
- The query first looks for the user with an
idof20. - The query then sets the
authorIDforeign key to20. This links the post with anidof4to the user with anidof20.
In this query, the current value of authorID does not matter. The query changes authorID to 20, no matter its current value.
Types of relations
There are three different types (or cardinalities) of relations in Prisma ORM:
- One-to-one (also called 1-1 relations)
- One-to-many (also called 1-n relations)
- Many-to-many (also called m-n relations)
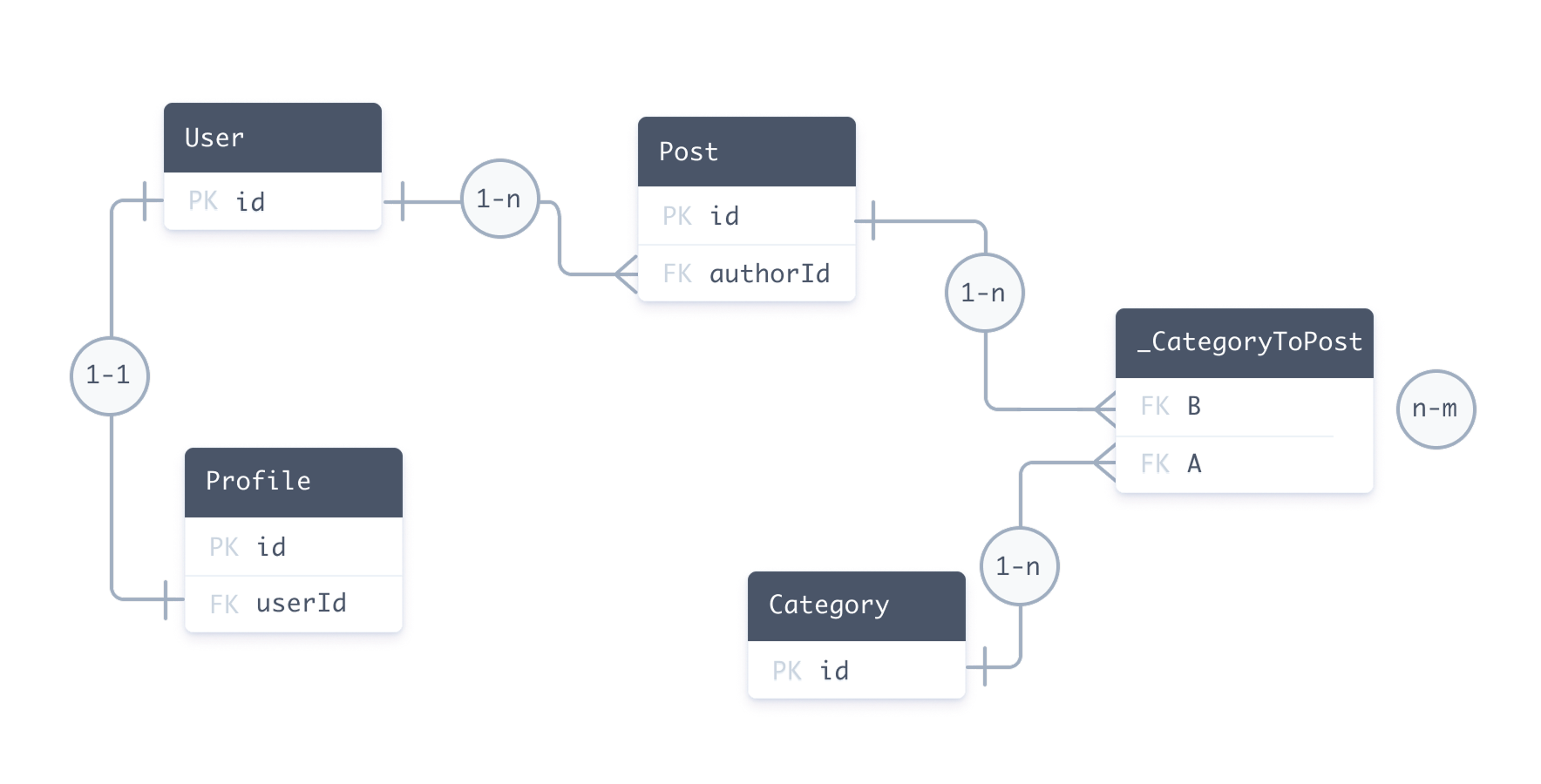
The following Prisma schema includes every type of relation:
- one-to-one:
User↔Profile - one-to-many:
User↔Post - many-to-many:
Post↔Category
- Relational databases
- MongoDB
model User {
id Int @id @default(autoincrement())
posts Post[]
profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user User @relation(fields: [userId], references: [id])
userId Int @unique // relation scalar field (used in the `@relation` attribute above)
}
model Post {
id Int @id @default(autoincrement())
author User @relation(fields: [authorId], references: [id])
authorId Int // relation scalar field (used in the `@relation` attribute above)
categories Category[]
}
model Category {
id Int @id @default(autoincrement())
posts Post[]
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
posts Post[]
profile Profile?
}
model Profile {
id String @id @default(auto()) @map("_id") @db.ObjectId
user User @relation(fields: [userId], references: [id])
userId String @unique @db.ObjectId // relation scalar field (used in the `@relation` attribute above)
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId // relation scalar field (used in the `@relation` attribute above)
categories Category[] @relation(fields: [categoryIds], references: [id])
categoryIds String[] @db.ObjectId
}
model Category {
id String @id @default(auto()) @map("_id") @db.ObjectId
posts Post[] @relation(fields: [postIds], references: [id])
postIds String[] @db.ObjectId
}
This schema is the same as the example data model but has all scalar fields removed (except for the required relation scalar fields) so you can focus on the relation fields.
This example uses implicit many-to-many relations. These relations do not require the @relation attribute unless you need to disambiguate relations.
Notice that the syntax is slightly different between relational databases and MongoDB - particularly for many-to-many relations.
For relational databases, the following entity relationship diagram represents the database that corresponds to the sample Prisma schema:
For MongoDB, Prisma ORM uses a normalized data model design, which means that documents reference each other by ID in a similar way to relational databases. See the MongoDB section for more details.
Implicit and explicit many-to-many relations
Many-to-many relations in relational databases can be modelled in two ways:
- explicit many-to-many relations, where the relation table is represented as an explicit model in your Prisma schema
- implicit many-to-many relations, where Prisma ORM manages the relation table and it does not appear in the Prisma schema.
Implicit many-to-many relations require both models to have a single @id. Be aware of the following:
- You cannot use a multi-field ID
- You cannot use a
@uniquein place of an@id
To use either of these features, you must set up an explicit many-to-many instead.
The implicit many-to-many relation still manifests in a relation table in the underlying database. However, Prisma ORM manages this relation table.
If you use an implicit many-to-many relation instead of an explicit one, it makes the Prisma Client API simpler (because, for example, you have one fewer level of nesting inside of nested writes).
If you're not using Prisma Migrate but obtain your data model from introspection, you can still make use of implicit many-to-many relations by following Prisma ORM's conventions for relation tables.
Relation fields
Relation fields are fields on a Prisma model that do not have a scalar type. Instead, their type is another model.
Every relation must have exactly two relation fields, one on each model. In the case of one-to-one and one-to-many relations, an additional relation scalar field is required which gets linked by one of the two relation fields in the @relation attribute. This relation scalar field is the direct representation of the foreign key in the underlying database.
- Relational databases
- MongoDB
model User {
id Int @id @default(autoincrement())
email String @unique
role Role @default(USER)
posts Post[] // relation field (defined only at the Prisma ORM level)
}
model Post {
id Int @id @default(autoincrement())
title String
author User @relation(fields: [authorId], references: [id]) // relation field (uses the relation scalar field `authorId` below)
authorId Int // relation scalar field (used in the `@relation` attribute above)
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
email String @unique
role Role @default(USER)
posts Post[] // relation field (defined only at the Prisma ORM level)
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
title String
author User @relation(fields: [authorId], references: [id]) // relation field (uses the relation scalar field `authorId` below)
authorId String @db.ObjectId // relation scalar field (used in the `@relation` attribute above)
}
Both posts and author are relation fields because their types are not scalar types but other models.
Also note that the annotated relation field author needs to link the relation scalar field authorId on the Post model inside the @relation attribute. The relation scalar field represents the foreign key in the underlying database.
Both the relation fields (i.e. posts and author) are defined purely on a Prisma ORM-level, they don't manifest in the database.
Annotated relation fields
Relations that require one side of the relation to be annotated with the @relation attribute are referred to as annotated relation fields. This includes:
- one-to-one relations
- one-to-many relations
- many-to-many relations for MongoDB only
The side of the relation which is annotated with the @relation attribute represents the side that stores the foreign key in the underlying database. The "actual" field that represents the foreign key is required on that side of the relation as well, it's called relation scalar field, and is referenced inside @relation attribute:
- Relational databases
- MongoDB
author User @relation(fields: [authorId], references: [id])
authorId Int
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
A scalar field becomes a relation scalar field when it's used in the fields of a @relation attribute.
Relation scalar fields
Relation scalar field naming conventions
Because a relation scalar field always belongs to a relation field, the following naming convention is common:
- Relation field:
author - Relation scalar field:
authorId(relation field name +Id)
The @relation attribute
The @relation attribute can only be applied to the relation fields, not to scalar fields.
The @relation attribute is required when:
- you define a one-to-one or one-to-many relation, it is required on one side of the relation (with the corresponding relation scalar field)
- you need to disambiguate a relation (that's e.g. the case when you have two relations between the same models)
- you define a self-relation
- you define a many-to-many relation for MongoDB
- you need to control how the relation table is represented in the underlying database (e.g. use a specific name for a relation table)
Note: Implicit many-to-many relations in relational databases do not require the
@relationattribute.
Disambiguating relations
When you define two relations between the same two models, you need to add the name argument in the @relation attribute to disambiguate them. As an example for why that's needed, consider the following models:
- Relational databases
- MongoDB
// NOTE: This schema is intentionally incorrect. See below for a working solution.
model User {
id Int @id @default(autoincrement())
name String?
writtenPosts Post[]
pinnedPost Post?
}
model Post {
id Int @id @default(autoincrement())
title String?
author User @relation(fields: [authorId], references: [id])
authorId Int
pinnedBy User? @relation(fields: [pinnedById], references: [id])
pinnedById Int?
}
// NOTE: This schema is intentionally incorrect. See below for a working solution.
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
name String?
writtenPosts Post[]
pinnedPost Post?
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
title String?
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
pinnedBy User? @relation(fields: [pinnedById], references: [id])
pinnedById String? @db.ObjectId
}
In that case, the relations are ambiguous, there are four different ways to interpret them:
User.writtenPosts↔Post.author+Post.authorIdUser.writtenPosts↔Post.pinnedBy+Post.pinnedByIdUser.pinnedPost↔Post.author+Post.authorIdUser.pinnedPost↔Post.pinnedBy+Post.pinnedById
To disambiguate these relations, you need to annotate the relation fields with the @relation attribute and provide the name argument. You can set any name (except for the empty string ""), but it must be the same on both sides of the relation:
- Relational databases
- MongoDB
model User {
id Int @id @default(autoincrement())
name String?
writtenPosts Post[] @relation("WrittenPosts")
pinnedPost Post? @relation("PinnedPost")
}
model Post {
id Int @id @default(autoincrement())
title String?
author User @relation("WrittenPosts", fields: [authorId], references: [id])
authorId Int
pinnedBy User? @relation("PinnedPost", fields: [pinnedById], references: [id])
pinnedById Int? @unique
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
name String?
writtenPosts Post[] @relation("WrittenPosts")
pinnedPost Post? @relation("PinnedPost")
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
title String?
author User @relation("WrittenPosts", fields: [authorId], references: [id])
authorId String @db.ObjectId
pinnedBy User? @relation("PinnedPost", fields: [pinnedById], references: [id])
pinnedById String? @unique @db.ObjectId
}